 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocateEdit-Bench: A Benchmark for Instruction-Based Editing Localization
Feb 05, 2026Recent advancements in image editing have enabled highly controllable and semantically-aware alteration of visual content, posing unprecedented challenges to manipulation localization. However, existing AI-generated forgery localization methods primarily focus on inpainting-based manipulations, making them ineffective against the latest instruction-based editing paradigms. To bridge this critical gap, we propose LocateEdit-Bench, a large-scale dataset comprising $231$K edited images, designed specifically to benchmark localization methods against instruction-driven image editing. Our dataset incorporates four cutting-edge editing models and covers three common edit types. We conduct a detailed analysis of the dataset and develop two multi-metric evaluation protocols to assess existing localization methods. Our work establishes a foundation to keep pace with the evolving landscape of image editing, thereby facilitating the development of effective methods for future forgery localization. Dataset will be open-sourced upon acceptance.
Few-Shot Learner Generalizes Across AI-Generated Image Detection
Jan 15, 2025



Current fake image detectors trained on large synthetic image datasets perform satisfactorily on limited studied generative models. However, they suffer a notable performance decline over unseen models. Besides, collecting adequate training data from online generative models is often expensive or infeasible. To overcome these issues, we propose Few-Shot Detector (FSD), a novel AI-generated image detector which learns a specialized metric space to effectively distinguish unseen fake images by utilizing very few samples. Experiments show FSD achieves state-of-the-art performance by $+7.4\%$ average ACC on GenImage dataset. More importantly, our method is better capable of capturing the intra-category common features in unseen images without further training.
The Future of ChatGPT-enabled Labor Market: A Preliminary Study
Apr 20, 2023As a phenomenal large language model, ChatGPT has achieved unparalleled success in various real-world tasks and increasingly plays an important role in our daily lives and work. However, extensive concerns are also raised about the potential ethical issues, especially about whether ChatGPT-like artificial general intelligence (AGI) will replace human jobs. To this end, in this paper, we introduce a preliminary data-driven study on the future of ChatGPT-enabled labor market from the view of Human-AI Symbiosis instead of Human-AI Confrontation. To be specific, we first conduct an in-depth analysis of large-scale job posting data in BOSS Zhipin, the largest online recruitment platform in China. The results indicate that about 28% of occupations in the current labor market require ChatGPT-related skills. Furthermore, based on a large-scale occupation-centered knowledge graph, we develop a semantic information enhanced collaborative filtering algorithm to predict the future occupation-skill relations in the labor market. As a result, we find that additional 45% occupations in the future will require ChatGPT-related skills. In particular, industries related to technology, products, and operations are expected to have higher proficiency requirements for ChatGPT-related skills, while the manufacturing, services, education, and health science related industries will have lower requirements for ChatGPT-related skills.
DialogPaint: A Dialog-based Image Editing Model
Mar 17, 2023

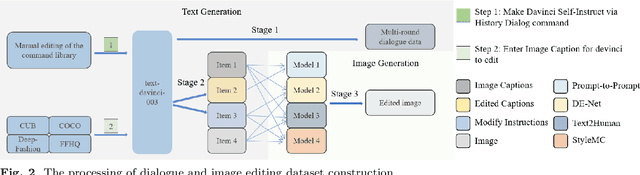
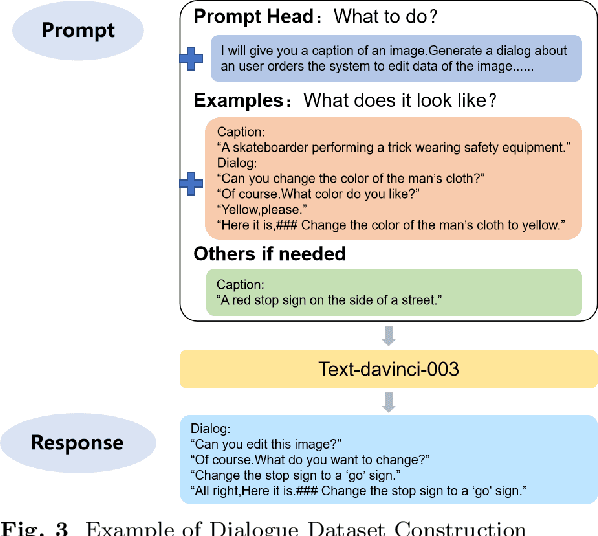
We present DialogPaint, an innovative framework that employs an interactive conversational approach for image editing. The framework comprises a pretrained dialogue model (Blenderbot) and a diffusion model (Stable Diffusion). The dialogue model engages in conversation with users to understand their requirements and generates concise instructions based on the dialogue. Subsequently, the Stable Diffusion model employs these instructions, along with the input image, to produce the desired output. Due to the difficulty of acquiring fine-tuning data for such models, we leverage multiple large-scale models to generate simulated dialogues and corresponding image pairs. After fine-tuning our framework with the synthesized data, we evaluate its performance in real application scenes. The results demonstrate that DialogPaint excels in both objective and subjective evaluation metrics effectively handling ambiguous instructions and performing tasks such as object replacement, style transfer, color modification. Moreover, our framework supports multi-round editing, allowing for the completion of complicated editing tasks.
End-to-end Transformer for Compressed Video Quality Enhancement
Oct 25, 2022Convolutional neural networks have achieved excellent results in compressed video quality enhancement task in recent years. State-of-the-art methods explore the spatiotemporal information of adjacent frames mainly by deformable convolution. However, offset fields in deformable convolution are difficult to train, and its instability in training often leads to offset overflow, which reduce the efficiency of correlation modeling. In this work, we propose a transformer-based compressed video quality enhancement (TVQE) method, consisting of Swin-AutoEncoder based Spatio-Temporal feature Fusion (SSTF) module and Channel-wise Attention based Quality Enhancement (CAQE) module. The proposed SSTF module learns both local and global features with the help of Swin-AutoEncoder, which improves the ability of correlation modeling. Meanwhile, the window mechanism-based Swin Transformer and the encoderdecoder structure greatly improve the execution efficiency. On the other hand, the proposed CAQE module calculates the channel attention, which aggregates the temporal information between channels in the feature map, and finally achieves the efficient fusion of inter-frame information. Extensive experimental results on the JCT-VT test sequences show that the proposed method achieves better performance in average for both subjective and objective quality. Meanwhile, our proposed method outperforms existing ones in terms of both inference speed and GPU consumption.
GlassLoc: Plenoptic Grasp Pose Detection in Transparent Clutter
Sep 17, 2019
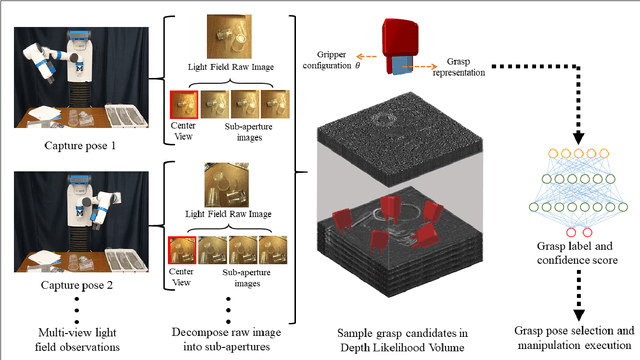
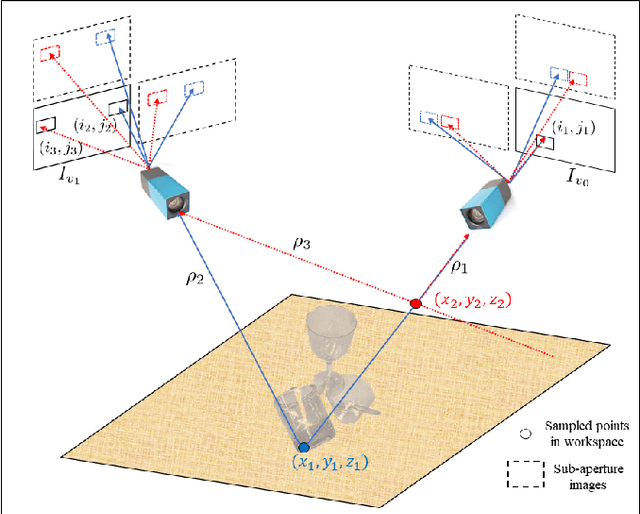
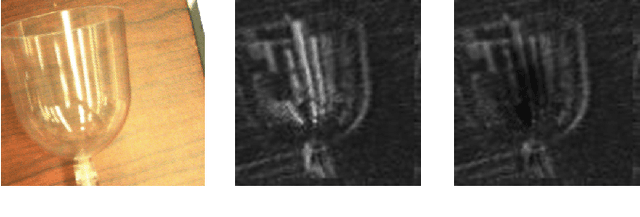
Transparent objects are prevalent across many environments of interest for dexterous robotic manipulation. Such transparent material leads to considerable uncertainty for robot perception and manipulation, and remains an open challenge for robotics. This problem is exacerbated when multiple transparent objects cluster into piles of clutter. In household environments, for example, it is common to encounter piles of glassware in kitchens, dining rooms, and reception areas, which are essentially invisible to modern robots. We present the GlassLoc algorithm for grasp pose detection of transparent objects in transparent clutter using plenoptic sensing. GlassLoc classifies graspable locations in space informed by a Depth Likelihood Volume (DLV) descriptor. We extend the DLV to infer the occupancy of transparent objects over a given space from multiple plenoptic viewpoints. We demonstrate and evaluate the GlassLoc algorithm on a Michigan Progress Fetch mounted with a first-generation Lytro. The effectiveness of our algorithm is evaluated through experiments for grasp detection and execution with a variety of transparent glassware in minor clutter.
Overview of the NLPCC 2015 Shared Task: Chinese Word Segmentation and POS Tagging for Micro-blog Texts
Jun 30, 2015
In this paper, we give an overview for the shared task at the 4th CCF Conference on Natural Language Processing \& Chinese Computing (NLPCC 2015): Chinese word segmentation and part-of-speech (POS) tagging for micro-blog texts. Different with the popular used newswire datasets, the dataset of this shared task consists of the relatively informal micro-texts. The shared task has two sub-tasks: (1) individual Chinese word segmentation and (2) joint Chinese word segmentation and POS Tagging. Each subtask has three tracks to distinguish the systems with different resources. We first introduce the dataset and task, then we characterize the different approaches of the participating systems, report the test results, and provide a overview analysis of these results. An online system is available for open registration and evaluation at http://nlp.fudan.edu.cn/nlpcc2015.