 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Future of ChatGPT-enabled Labor Market: A Preliminary Study
Apr 20, 2023As a phenomenal large language model, ChatGPT has achieved unparalleled success in various real-world tasks and increasingly plays an important role in our daily lives and work. However, extensive concerns are also raised about the potential ethical issues, especially about whether ChatGPT-like artificial general intelligence (AGI) will replace human jobs. To this end, in this paper, we introduce a preliminary data-driven study on the future of ChatGPT-enabled labor market from the view of Human-AI Symbiosis instead of Human-AI Confrontation. To be specific, we first conduct an in-depth analysis of large-scale job posting data in BOSS Zhipin, the largest online recruitment platform in China. The results indicate that about 28% of occupations in the current labor market require ChatGPT-related skills. Furthermore, based on a large-scale occupation-centered knowledge graph, we develop a semantic information enhanced collaborative filtering algorithm to predict the future occupation-skill relations in the labor market. As a result, we find that additional 45% occupations in the future will require ChatGPT-related skills. In particular, industries related to technology, products, and operations are expected to have higher proficiency requirements for ChatGPT-related skills, while the manufacturing, services, education, and health science related industries will have lower requirements for ChatGPT-related skills.
SRDiff: Single Image Super-Resolution with Diffusion Probabilistic Models
May 18, 2021
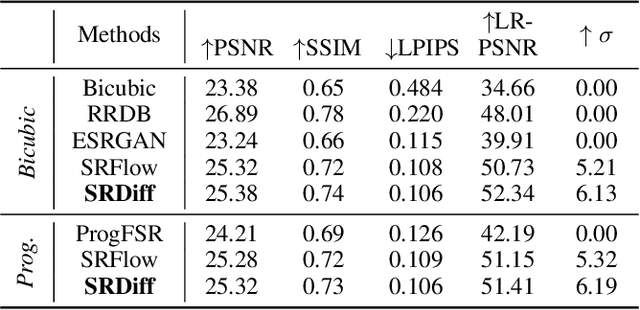
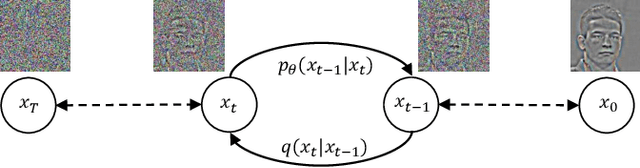
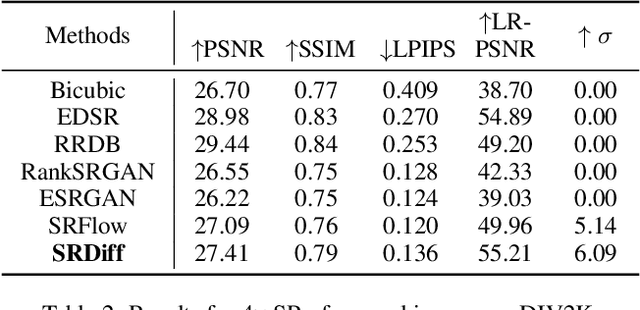
Single image super-resolution (SISR) aims to reconstruct high-resolution (HR) images from the given low-resolution (LR) ones, which is an ill-posed problem because one LR image corresponds to multiple HR images. Recently, learning-based SISR methods have greatly outperformed traditional ones, while suffering from over-smoothing, mode collapse or large model footprint issues for PSNR-oriented, GAN-driven and flow-based methods respectively. To solve these problems, we propose a novel single image super-resolution diffusion probabilistic model (SRDiff), which is the first diffusion-based model for SISR. SRDiff is optimized with a variant of the variational bound on the data likelihood and can provide diverse and realistic SR predictions by gradually transforming the Gaussian noise into a super-resolution (SR) image conditioned on an LR input through a Markov chain. In addition, we introduce residual prediction to the whole framework to speed up convergence. Our extensive experiments on facial and general benchmarks (CelebA and DIV2K datasets) show that 1) SRDiff can generate diverse SR results in rich details with state-of-the-art performance, given only one LR input; 2) SRDiff is easy to train with a small footprint; and 3) SRDiff can perform flexible image manipulation including latent space interpolation and content fusion.
Low-light Image Restoration with Short- and Long-exposure Raw Pairs
Jul 01, 2020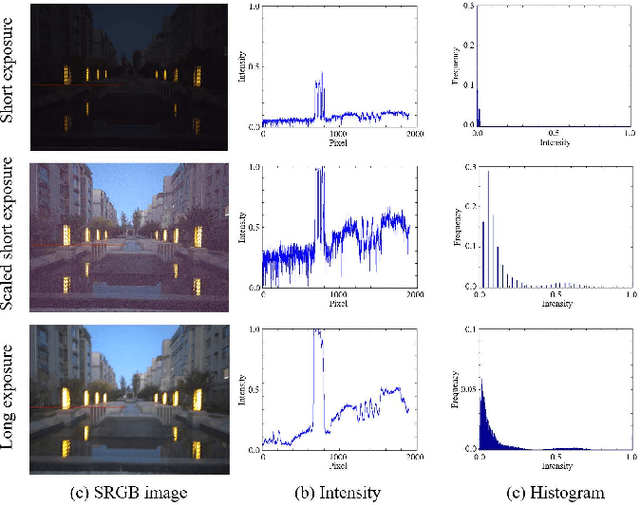



Low-light imaging with handheld mobile devices is a challenging issue. Limited by the existing models and training data, most existing methods cannot be effectively applied in real scenarios. In this paper, we propose a new low-light image restoration method by using the complementary information of short- and long-exposure images. We first propose a novel data generation method to synthesize realistic short- and longexposure raw images by simulating the imaging pipeline in lowlight environment. Then, we design a new long-short-exposure fusion network (LSFNet) to deal with the problems of low-light image fusion, including high noise, motion blur, color distortion and misalignment. The proposed LSFNet takes pairs of shortand long-exposure raw images as input, and outputs a clear RGB image. Using our data generation method and the proposed LSFNet, we can recover the details and color of the original scene, and improve the low-light image quality effectively. Experiments demonstrate that our method can outperform the state-of-the art methods.
Beyond Camera Motion Removing: How to Handle Outliers in Deblurring
Feb 24, 2020
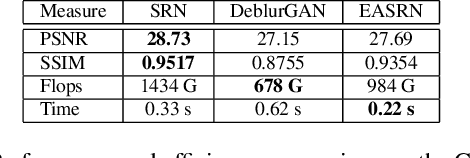
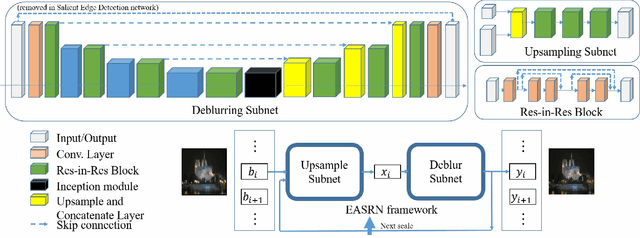
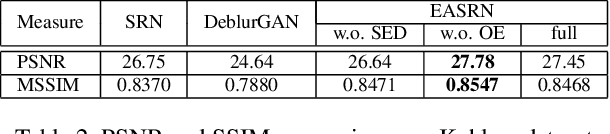
Performing camera motion deblurring is an important low-level vision task for achieving better imaging quality. When a scene has outliers such as saturated pixels and salt-and pepper noise, the image becomes more difficult to restore. In this paper, we propose an edge-aware scalerecurrent network (EASRN) to conduct camera motion deblurring. EASRN has a separate deblurring module that removes blur at multiple scales and an upsampling module that fuses different input scales. We propose a salient edge detection network to supervise the training process and solve the outlier problem by proposing a novel method of dataset generation. Light streaks are printed on the sharp image to simulate the cutoff effect from saturation. We evaluate our method on the standard deblurring datasets. Both objective evaluation indexes and subjective visualization show that our method results in better deblurring quality than the other state-of-the-art approaches.
Spatial-Adaptive Network for Single Image Denoising
Jan 28, 2020

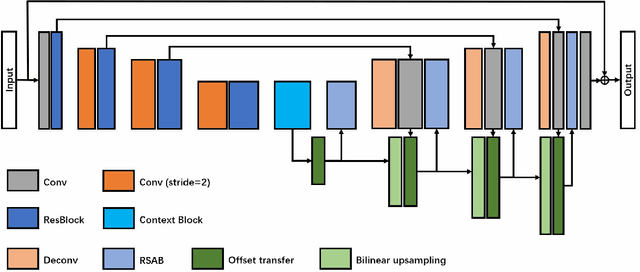
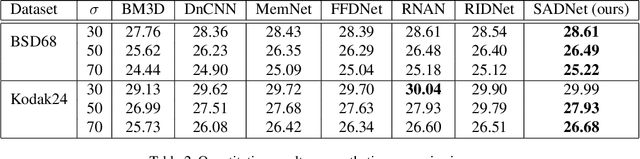
Previous works have shown that convolutional neural networks can achieve good performance in image denoising tasks. However, limited by the local rigid convolutional operation, these methods lead to oversmoothing artifacts. A deeper network structure could alleviate these problems, but more computational overhead is needed. In this paper, we propose a novel spatial-adaptive denoising network (SADNet) for efficient single image blind noise removal. To adapt to changes in spatial textures and edges, we design a residual spatial-adaptive block. Deformable convolution is introduced to sample the spatially correlated features for weighting. An encoder-decoder structure with a context block is introduced to capture multiscale information. With noise removal from the coarse to fine, a high-quality noisefree image can be obtained. We apply our method to both synthetic and real noisy image datasets. The experimental results demonstrate that our method can surpass the state-of-the-art denoising methods both quantitatively and visually.