 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Snapshots to Trajectories: Learning Single-Cell Gene Expression Dynamics via Conditional Flow Matching
May 21, 2026Single-cell RNA sequencing (scRNA-seq) provides high-dimensional profiles of cellular states, enabling data-driven modeling of cellular dynamics over time. In practice, time-resolved scRNA-seq is collected at only a few discrete time points as unpaired snapshot populations, leaving substantial temporal gaps. This motivates trajectory inference at unmeasured time points. Existing methods mainly follow two directions, optimal-transport (OT) alignment provides distribution-level matching between observed snapshots, while continuous-time generative models support forecasting via learned dynamics. However, two challenges remain: (i) unpaired snapshots render local transitions between adjacent time points ambiguous, leading to unstable supervision; and (ii) long-horizon prediction relies on repeated integration, where small modeling errors compound and cause distribution drift. To address these challenges, we propose single-cell Flow Matching (scFM), a latent generative framework based on coupling-conditioned flow matching. First, we compute entropically regularized OT couplings between adjacent snapshots and use them to construct soft, weighted flow-matching targets for learning time-dependent velocity fields. Second, we learn bidirectional velocity fields and leverage their consistency to refine couplings and improve temporal coherence under sparse supervision. Third, we introduce distribution-level alignment and latent dynamic regularization to anchor long rollouts and mitigate drift. Experiments on real-world time-series scRNA-seq datasets show that scFM consistently improves distributional prediction performance for both temporal interpolation and extrapolation. Moreover, scFM yields more accurate trajectory reconstruction and temporally coherent visualizations where intermediate time points are absent, indicating a more faithful recovery of underlying temporal gene expression dynamics.
MobilityBench: A Benchmark for Evaluating Route-Planning Agents in Real-World Mobility Scenarios
Feb 26, 2026Route-planning agents powered by large language models (LLMs) have emerged as a promising paradigm for supporting everyday human mobility through natural language interaction and tool-mediated decision making. However, systematic evaluation in real-world mobility settings is hindered by diverse routing demands, non-deterministic mapping services, and limited reproducibility. In this study, we introduce MobilityBench, a scalable benchmark for evaluating LLM-based route-planning agents in real-world mobility scenarios. MobilityBench is constructed from large-scale, anonymized real user queries collected from Amap and covers a broad spectrum of route-planning intents across multiple cities worldwide. To enable reproducible, end-to-end evaluation, we design a deterministic API-replay sandbox that eliminates environmental variance from live services. We further propose a multi-dimensional evaluation protocol centered on outcome validity, complemented by assessments of instruction understanding, planning, tool use, and efficiency. Using MobilityBench, we evaluate multiple LLM-based route-planning agents across diverse real-world mobility scenarios and provide an in-depth analysis of their behaviors and performance. Our findings reveal that current models perform competently on Basic information retrieval and Route Planning tasks, yet struggle considerably with Preference-Constrained Route Planning, underscoring significant room for improvement in personalized mobility applications. We publicly release the benchmark data, evaluation toolkit, and documentation at https://github.com/AMAP-ML/MobilityBench .
SciHorizon-GENE: Benchmarking LLM for Life Sciences Inference from Gene Knowledge to Functional Understanding
Jan 21, 2026Large language models (LLMs) have shown growing promise in biomedical research, particularly for knowledge-driven interpretation tasks. However, their ability to reliably reason from gene-level knowledge to functional understanding, a core requirement for knowledge-enhanced cell atlas interpretation, remains largely underexplored. To address this gap, we introduce SciHorizon-GENE, a large-scale gene-centric benchmark constructed from authoritative biological databases. The benchmark integrates curated knowledge for over 190K human genes and comprises more than 540K questions covering diverse gene-to-function reasoning scenarios relevant to cell type annotation, functional interpretation, and mechanism-oriented analysis. Motivated by behavioral patterns observed in preliminary examinations, SciHorizon-GENE evaluates LLMs along four biologically critical perspectives: research attention sensitivity, hallucination tendency, answer completeness, and literature influence, explicitly targeting failure modes that limit the safe adoption of LLMs in biological interpretation pipelines. We systematically evaluate a wide range of state-of-the-art general-purpose and biomedical LLMs, revealing substantial heterogeneity in gene-level reasoning capabilities and persistent challenges in generating faithful, complete, and literature-grounded functional interpretations. Our benchmark establishes a systematic foundation for analyzing LLM behavior at the gene scale and offers insights for model selection and development, with direct relevance to knowledge-enhanced biological interpretation.
ScienceDB AI: An LLM-Driven Agentic Recommender System for Large-Scale Scientific Data Sharing Services
Jan 03, 2026The rapid growth of AI for Science (AI4S) has underscored the significance of scientific datasets, leading to the establishment of numerous national scientific data centers and sharing platforms. Despite this progress, efficiently promoting dataset sharing and utilization for scientific research remains challenging. Scientific datasets contain intricate domain-specific knowledge and contexts, rendering traditional collaborative filtering-based recommenders inadequate. Recent advances in Large Language Models (LLMs) offer unprecedented opportunities to build conversational agents capable of deep semantic understanding and personalized recommendations. In response, we present ScienceDB AI, a novel LLM-driven agentic recommender system developed on Science Data Bank (ScienceDB), one of the largest global scientific data-sharing platforms. ScienceDB AI leverages natural language conversations and deep reasoning to accurately recommend datasets aligned with researchers' scientific intents and evolving requirements. The system introduces several innovations: a Scientific Intention Perceptor to extract structured experimental elements from complicated queries, a Structured Memory Compressor to manage multi-turn dialogues effectively, and a Trustworthy Retrieval-Augmented Generation (Trustworthy RAG) framework. The Trustworthy RAG employs a two-stage retrieval mechanism and provides citable dataset references via Citable Scientific Task Record (CSTR) identifiers, enhancing recommendation trustworthiness and reproducibility. Through extensive offline and online experiments using over 10 million real-world datasets, ScienceDB AI has demonstrated significant effectiveness. To our knowledge, ScienceDB AI is the first LLM-driven conversational recommender tailored explicitly for large-scale scientific dataset sharing services. The platform is publicly accessible at: https://ai.scidb.cn/en.
SciRerankBench: Benchmarking Rerankers Towards Scientific Retrieval-Augmented Generated LLMs
Aug 12, 2025Scientific literature question answering is a pivotal step towards new scientific discoveries. Recently, \textit{two-stage} retrieval-augmented generated large language models (RAG-LLMs) have shown impressive advancements in this domain. Such a two-stage framework, especially the second stage (reranker), is particularly essential in the scientific domain, where subtle differences in terminology may have a greatly negative impact on the final factual-oriented or knowledge-intensive answers. Despite this significant progress, the potential and limitations of these works remain unexplored. In this work, we present a Scientific Rerank-oriented RAG Benchmark (SciRerankBench), for evaluating rerankers within RAG-LLMs systems, spanning five scientific subjects. To rigorously assess the reranker performance in terms of noise resilience, relevance disambiguation, and factual consistency, we develop three types of question-context-answer (Q-C-A) pairs, i.e., Noisy Contexts (NC), Semantically Similar but Logically Irrelevant Contexts (SSLI), and Counterfactual Contexts (CC). Through systematic evaluation of 13 widely used rerankers on five families of LLMs, we provide detailed insights into their relative strengths and limitations. To the best of our knowledge, SciRerankBench is the first benchmark specifically developed to evaluate rerankers within RAG-LLMs, which provides valuable observations and guidance for their future development.
Application-Driven Value Alignment in Agentic AI Systems: Survey and Perspectives
Jun 11, 2025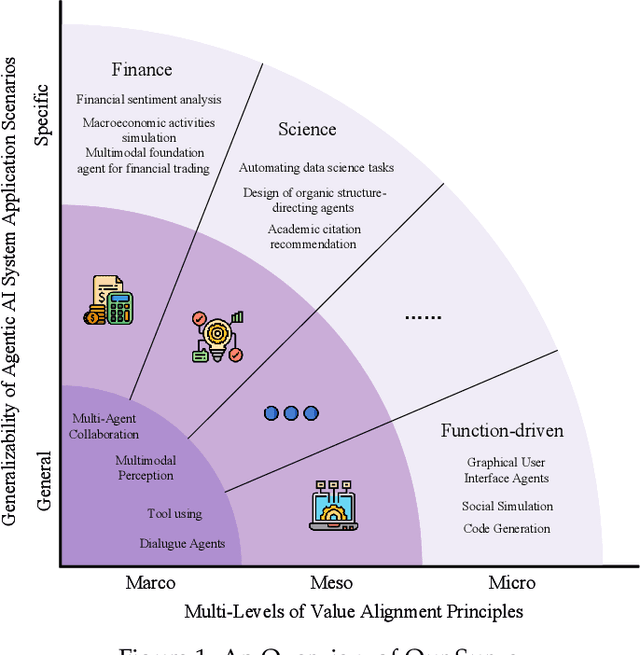
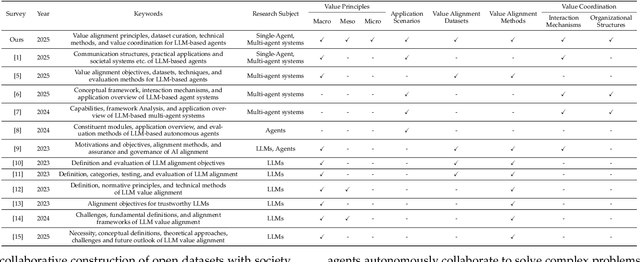
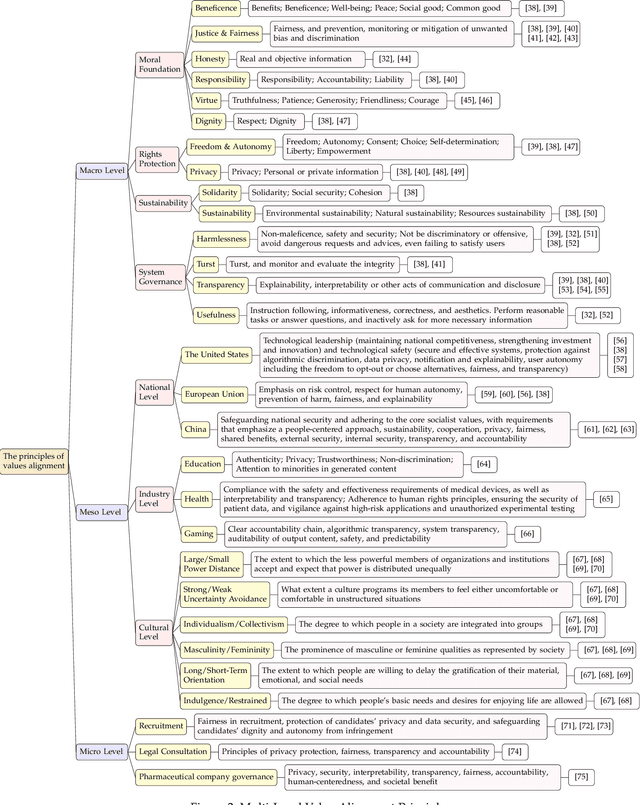
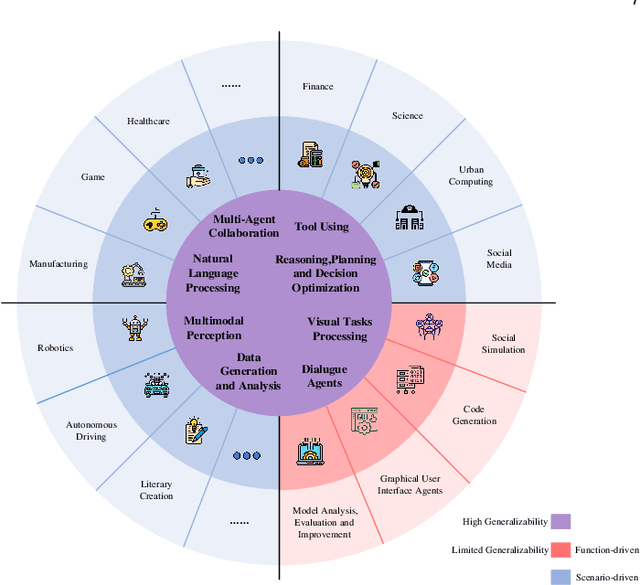
The ongoing evolution of AI paradigms has propelled AI research into the Agentic AI stage. Consequently, the focus of research has shifted from single agents and simple applications towards multi-agent autonomous decision-making and task collaboration in complex environments. As Large Language Models (LLMs) advance, their applications become more diverse and complex, leading to increasingly situational and systemic risks. This has brought significant attention to value alignment for AI agents, which aims to ensure that an agent's goals, preferences, and behaviors align with human values and societal norms. This paper reviews value alignment in agent systems within specific application scenarios. It integrates the advancements in AI driven by large models with the demands of social governance. Our review covers value principles, agent system application scenarios, and agent value alignment evaluation. Specifically, value principles are organized hierarchically from a top-down perspective, encompassing macro, meso, and micro levels. Agent system application scenarios are categorized and reviewed from a general-to-specific viewpoint. Agent value alignment evaluation systematically examines datasets for value alignment assessment and relevant value alignment methods. Additionally, we delve into value coordination among multiple agents within agent systems. Finally, we propose several potential research directions in this field.
GenKI: Enhancing Open-Domain Question Answering with Knowledge Integration and Controllable Generation in Large Language Models
May 26, 2025Open-domain question answering (OpenQA) represents a cornerstone in natural language processing (NLP), primarily focused on extracting answers from unstructured textual data. With the rapid advancements in Large Language Models (LLMs), LLM-based OpenQA methods have reaped the benefits of emergent understanding and answering capabilities enabled by massive parameters compared to traditional methods. However, most of these methods encounter two critical challenges: how to integrate knowledge into LLMs effectively and how to adaptively generate results with specific answer formats for various task situations. To address these challenges, we propose a novel framework named GenKI, which aims to improve the OpenQA performance by exploring Knowledge Integration and controllable Generation on LLMs simultaneously. Specifically, we first train a dense passage retrieval model to retrieve associated knowledge from a given knowledge base. Subsequently, we introduce a novel knowledge integration model that incorporates the retrieval knowledge into instructions during fine-tuning to intensify the model. Furthermore, to enable controllable generation in LLMs, we leverage a certain fine-tuned LLM and an ensemble based on text consistency incorporating all coherence, fluency, and answer format assurance. Finally, extensive experiments conducted on the TriviaQA, MSMARCO, and CMRC2018 datasets, featuring diverse answer formats, have demonstrated the effectiveness of GenKI with comparison of state-of-the-art baselines. Moreover, ablation studies have disclosed a linear relationship between the frequency of retrieved knowledge and the model's ability to recall knowledge accurately against the ground truth. Our code of GenKI is available at https://github.com/USTC-StarTeam/GenKI
Enhancing Job Salary Prediction with Disentangled Composition Effect Modeling: A Neural Prototyping Approach
Mar 17, 2025In the era of the knowledge economy, understanding how job skills influence salary is crucial for promoting recruitment with competitive salary systems and aligned salary expectations. Despite efforts on salary prediction based on job positions and talent demographics, there still lacks methods to effectively discern the set-structured skills' intricate composition effect on job salary. While recent advances in neural networks have significantly improved accurate set-based quantitative modeling, their lack of explainability hinders obtaining insights into the skills' composition effects. Indeed, model explanation for set data is challenging due to the combinatorial nature, rich semantics, and unique format. To this end, in this paper, we propose a novel intrinsically explainable set-based neural prototyping approach, namely \textbf{LGDESetNet}, for explainable salary prediction that can reveal disentangled skill sets that impact salary from both local and global perspectives. Specifically, we propose a skill graph-enhanced disentangled discrete subset selection layer to identify multi-faceted influential input subsets with varied semantics. Furthermore, we propose a set-oriented prototype learning method to extract globally influential prototypical sets. The resulting output is transparently derived from the semantic interplay between these input subsets and global prototypes. Extensive experiments on four real-world datasets demonstrate that our method achieves superior performance than state-of-the-art baselines in salary prediction while providing explainable insights into salary-influencing patterns.
A Comprehensive Survey on Self-Interpretable Neural Networks
Jan 26, 2025Neural networks have achieved remarkable success across various fields. However, the lack of interpretability limits their practical use, particularly in critical decision-making scenarios. Post-hoc interpretability, which provides explanations for pre-trained models, is often at risk of robustness and fidelity. This has inspired a rising interest in self-interpretable neural networks, which inherently reveal the prediction rationale through the model structures. Although there exist surveys on post-hoc interpretability, a comprehensive and systematic survey of self-interpretable neural networks is still missing. To address this gap, we first collect and review existing works on self-interpretable neural networks and provide a structured summary of their methodologies from five key perspectives: attribution-based, function-based, concept-based, prototype-based, and rule-based self-interpretation. We also present concrete, visualized examples of model explanations and discuss their applicability across diverse scenarios, including image, text, graph data, and deep reinforcement learning. Additionally, we summarize existing evaluation metrics for self-interpretability and identify open challenges in this field, offering insights for future research. To support ongoing developments, we present a publicly accessible resource to track advancements in this domain: https://github.com/yangji721/Awesome-Self-Interpretable-Neural-Network.
Knowledge-Guided Biomarker Identification for Label-Free Single-Cell RNA-Seq Data: A Reinforcement Learning Perspective
Jan 02, 2025



Gene panel selection aims to identify the most informative genomic biomarkers in label-free genomic datasets. Traditional approaches, which rely on domain expertise, embedded machine learning models, or heuristic-based iterative optimization, often introduce biases and inefficiencies, potentially obscuring critical biological signals. To address these challenges, we present an iterative gene panel selection strategy that harnesses ensemble knowledge from existing gene selection algorithms to establish preliminary boundaries or prior knowledge, which guide the initial search space. Subsequently, we incorporate reinforcement learning through a reward function shaped by expert behavior, enabling dynamic refinement and targeted selection of gene panels. This integration mitigates biases stemming from initial boundaries while capitalizing on RL's stochastic adaptability. Comprehensive comparative experiments, case studies, and downstream analyses demonstrate the effectiveness of our method, highlighting its improved precision and efficiency for label-free biomarker discovery. Our results underscore the potential of this approach to advance single-cell genomics data analysis.