 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication-Driven Value Alignment in Agentic AI Systems: Survey and Perspectives
Jun 11, 2025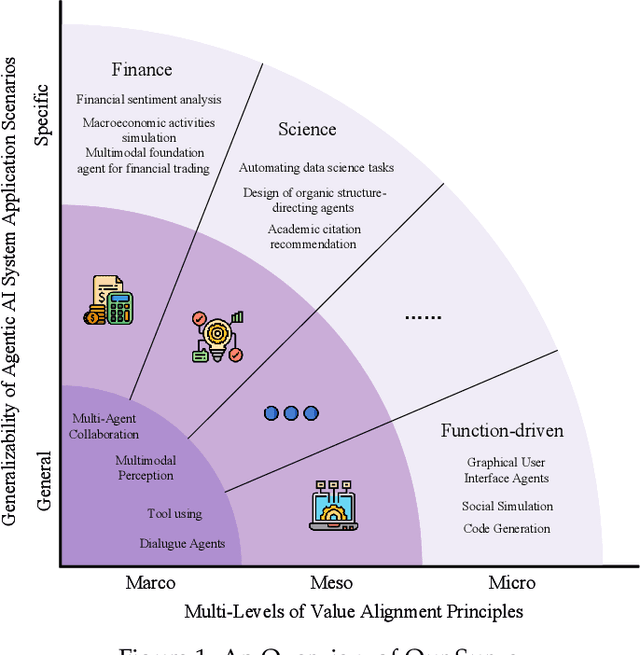
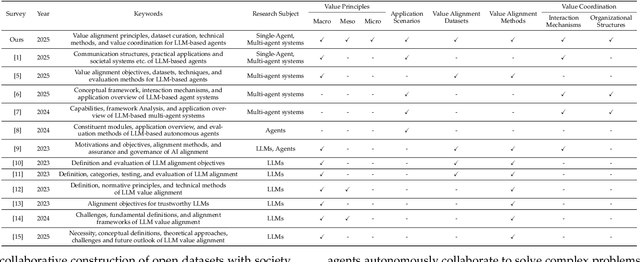
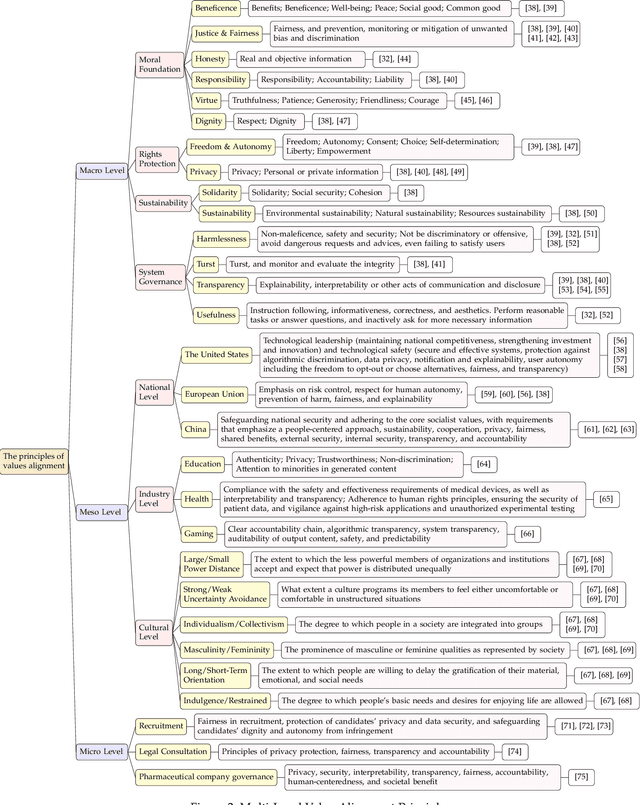
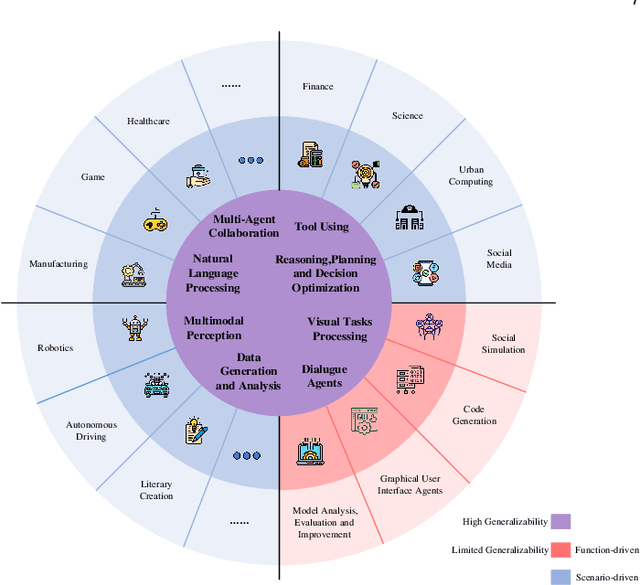
The ongoing evolution of AI paradigms has propelled AI research into the Agentic AI stage. Consequently, the focus of research has shifted from single agents and simple applications towards multi-agent autonomous decision-making and task collaboration in complex environments. As Large Language Models (LLMs) advance, their applications become more diverse and complex, leading to increasingly situational and systemic risks. This has brought significant attention to value alignment for AI agents, which aims to ensure that an agent's goals, preferences, and behaviors align with human values and societal norms. This paper reviews value alignment in agent systems within specific application scenarios. It integrates the advancements in AI driven by large models with the demands of social governance. Our review covers value principles, agent system application scenarios, and agent value alignment evaluation. Specifically, value principles are organized hierarchically from a top-down perspective, encompassing macro, meso, and micro levels. Agent system application scenarios are categorized and reviewed from a general-to-specific viewpoint. Agent value alignment evaluation systematically examines datasets for value alignment assessment and relevant value alignment methods. Additionally, we delve into value coordination among multiple agents within agent systems. Finally, we propose several potential research directions in this field.
TIPCB: A Simple but Effective Part-based Convolutional Baseline for Text-based Person Search
May 25, 2021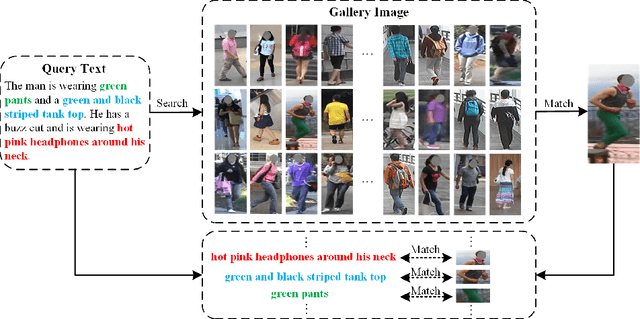



Text-based person search is a sub-task in the field of image retrieval, which aims to retrieve target person images according to a given textual description. The significant feature gap between two modalities makes this task very challenging. Many existing methods attempt to utilize local alignment to address this problem in the fine-grained level. However, most relevant methods introduce additional models or complicated training and evaluation strategies, which are hard to use in realistic scenarios. In order to facilitate the practical application, we propose a simple but effective end-to-end learning framework for text-based person search named TIPCB (i.e., Text-Image Part-based Convolutional Baseline). Firstly, a novel dual-path local alignment network structure is proposed to extract visual and textual local representations, in which images are segmented horizontally and texts are aligned adaptively. Then, we propose a multi-stage cross-modal matching strategy, which eliminates the modality gap from three feature levels, including low level, local level and global level. Extensive experiments are conducted on the widely-used benchmark dataset (CUHK-PEDES) and verify that our method outperforms the state-of-the-art methods by 3.69%, 2.95% and 2.31% in terms of Top-1, Top-5 and Top-10. Our code has been released in https://github.com/OrangeYHChen/TIPCB.