 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy Intelligent Education: A Systematic Perspective on Progress, Challenges, and Future Directions
Jan 29, 2026In recent years, trustworthiness has garnered increasing attention and exploration in the field of intelligent education, due to the inherent sensitivity of educational scenarios, such as involving minors and vulnerable groups, highly personalized learning data, and high-stakes educational outcomes. However, existing research either focuses on task-specific trustworthy methods without a holistic view of trustworthy intelligent education, or provides survey-level discussions that remain high-level and fragmented, lacking a clear and systematic categorization. To address these limitations, in this paper, we present a systematic and structured review of trustworthy intelligent education. Specifically, We first organize intelligent education into five representative task categories: learner ability assessment, learning resource recommendation, learning analytics, educational content understanding, and instructional assistance. Building on this task landscape, we review existing studies from five trustworthiness perspectives, including safety and privacy, robustness, fairness, explainability, and sustainability, and summarize and categorize the research methodologies and solution strategies therein. Finally, we summarize key challenges and discuss future research directions. This survey aims to provide a coherent reference framework and facilitate a clearer understanding of trustworthiness in intelligent education.
Breaking Robustness Barriers in Cognitive Diagnosis: A One-Shot Neural Architecture Search Perspective
Jan 08, 2026With the advancement of network technologies, intelligent tutoring systems (ITS) have emerged to deliver increasingly precise and tailored personalized learning services. Cognitive diagnosis (CD) has emerged as a core research task in ITS, aiming to infer learners' mastery of specific knowledge concepts by modeling the mapping between learning behavior data and knowledge states. However, existing research prioritizes model performance enhancement while neglecting the pervasive noise contamination in observed response data, significantly hindering practical deployment. Furthermore, current cognitive diagnosis models (CDMs) rely heavily on researchers' domain expertise for structural design, which fails to exhaustively explore architectural possibilities, thus leaving model architectures' full potential untapped. To address this issue, we propose OSCD, an evolutionary multi-objective One-Shot neural architecture search method for Cognitive Diagnosis, designed to efficiently and robustly improve the model's capability in assessing learner proficiency. Specifically, OSCD operates through two distinct stages: training and searching. During the training stage, we construct a search space encompassing diverse architectural combinations and train a weight-sharing supernet represented via the complete binary tree topology, enabling comprehensive exploration of potential architectures beyond manual design priors. In the searching stage, we formulate the optimal architecture search under heterogeneous noise scenarios as a multi-objective optimization problem (MOP), and develop an optimization framework integrating a Pareto-optimal solution search strategy with cross-scenario performance evaluation for resolution. Extensive experiments on real-world educational datasets validate the effectiveness and robustness of the optimal architectures discovered by our OSCD model for CD tasks.
DisenGCD: A Meta Multigraph-assisted Disentangled Graph Learning Framework for Cognitive Diagnosis
Oct 23, 2024



Existing graph learning-based cognitive diagnosis (CD) methods have made relatively good results, but their student, exercise, and concept representations are learned and exchanged in an implicit unified graph, which makes the interaction-agnostic exercise and concept representations be learned poorly, failing to provide high robustness against noise in students' interactions. Besides, lower-order exercise latent representations obtained in shallow layers are not well explored when learning the student representation. To tackle the issues, this paper suggests a meta multigraph-assisted disentangled graph learning framework for CD (DisenGCD), which learns three types of representations on three disentangled graphs: student-exercise-concept interaction, exercise-concept relation, and concept dependency graphs, respectively. Specifically, the latter two graphs are first disentangled from the interaction graph. Then, the student representation is learned from the interaction graph by a devised meta multigraph learning module; multiple learnable propagation paths in this module enable current student latent representation to access lower-order exercise latent representations, which can lead to more effective nad robust student representations learned; the exercise and concept representations are learned on the relation and dependency graphs by graph attention modules. Finally, a novel diagnostic function is devised to handle three disentangled representations for prediction. Experiments show better performance and robustness of DisenGCD than state-of-the-art CD methods and demonstrate the effectiveness of the disentangled learning framework and meta multigraph module. The source code is available at \textcolor{red}{\url{https://github.com/BIMK/Intelligent-Education/tree/main/DisenGCD}}.
DISCO: A Hierarchical Disentangled Cognitive Diagnosis Framework for Interpretable Job Recommendation
Oct 10, 2024



The rapid development of online recruitment platforms has created unprecedented opportunities for job seekers while concurrently posing the significant challenge of quickly and accurately pinpointing positions that align with their skills and preferences. Job recommendation systems have significantly alleviated the extensive search burden for job seekers by optimizing user engagement metrics, such as clicks and applications, thus achieving notable success. In recent years, a substantial amount of research has been devoted to developing effective job recommendation models, primarily focusing on text-matching based and behavior modeling based methods. While these approaches have realized impressive outcomes, it is imperative to note that research on the explainability of recruitment recommendations remains profoundly unexplored. To this end, in this paper, we propose DISCO, a hierarchical Disentanglement based Cognitive diagnosis framework, aimed at flexibly accommodating the underlying representation learning model for effective and interpretable job recommendations. Specifically, we first design a hierarchical representation disentangling module to explicitly mine the hierarchical skill-related factors implied in hidden representations of job seekers and jobs. Subsequently, we propose level-aware association modeling to enhance information communication and robust representation learning both inter- and intra-level, which consists of the interlevel knowledge influence module and the level-wise contrastive learning. Finally, we devise an interaction diagnosis module incorporating a neural diagnosis function for effectively modeling the multi-level recruitment interaction process between job seekers and jobs, which introduces the cognitive measurement theory.
RIGL: A Unified Reciprocal Approach for Tracing the Independent and Group Learning Processes
Jun 18, 2024In the realm of education, both independent learning and group learning are esteemed as the most classic paradigms. The former allows learners to self-direct their studies, while the latter is typically characterized by teacher-directed scenarios. Recent studies in the field of intelligent education have leveraged deep temporal models to trace the learning process, capturing the dynamics of students' knowledge states, and have achieved remarkable performance. However, existing approaches have primarily focused on modeling the independent learning process, with the group learning paradigm receiving less attention. Moreover, the reciprocal effect between the two learning processes, especially their combined potential to foster holistic student development, remains inadequately explored. To this end, in this paper, we propose RIGL, a unified Reciprocal model to trace knowledge states at both the individual and group levels, drawing from the Independent and Group Learning processes. Specifically, we first introduce a time frame-aware reciprocal embedding module to concurrently model both student and group response interactions across various time frames. Subsequently, we employ reciprocal enhanced learning modeling to fully exploit the comprehensive and complementary information between the two behaviors. Furthermore, we design a relation-guided temporal attentive network, comprised of dynamic graph modeling coupled with a temporal self-attention mechanism. It is used to delve into the dynamic influence of individual and group interactions throughout the learning processes. Conclusively, we introduce a bias-aware contrastive learning module to bolster the stability of the model's training. Extensive experiments on four real-world educational datasets clearly demonstrate the effectiveness of the proposed RIGL model.
Endowing Interpretability for Neural Cognitive Diagnosis by Efficient Kolmogorov-Arnold Networks
May 23, 2024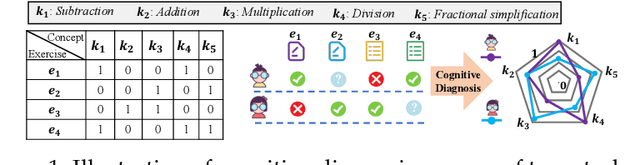

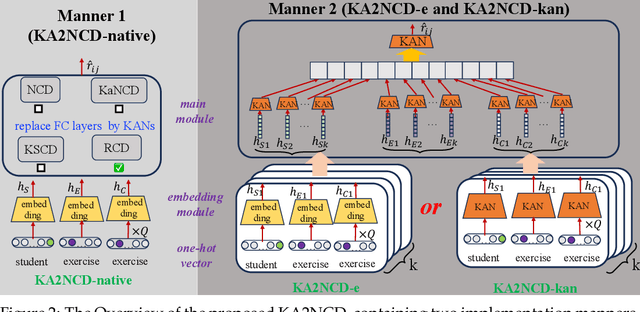
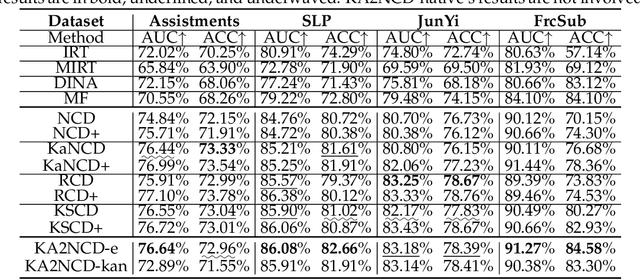
In the realm of intelligent education, cognitive diagnosis plays a crucial role in subsequent recommendation tasks attributed to the revealed students' proficiency in knowledge concepts. Although neural network-based neural cognitive diagnosis models (CDMs) have exhibited significantly better performance than traditional models, neural cognitive diagnosis is criticized for the poor model interpretability due to the multi-layer perception (MLP) employed, even with the monotonicity assumption. Therefore, this paper proposes to empower the interpretability of neural cognitive diagnosis models through efficient kolmogorov-arnold networks (KANs), named KAN2CD, where KANs are designed to enhance interpretability in two manners. Specifically, in the first manner, KANs are directly used to replace the used MLPs in existing neural CDMs; while in the second manner, the student embedding, exercise embedding, and concept embedding are directly processed by several KANs, and then their outputs are further combined and learned in a unified KAN to get final predictions. To overcome the problem of training KANs slowly, we modify the implementation of original KANs to accelerate the training. Experiments on four real-world datasets show that the proposed KA2NCD exhibits better performance than traditional CDMs, and the proposed KA2NCD still has a bit of performance leading even over the existing neural CDMs. More importantly, the learned structures of KANs enable the proposed KA2NCD to hold as good interpretability as traditional CDMs, which is superior to existing neural CDMs. Besides, the training cost of the proposed KA2NCD is competitive to existing models.
Evolutionary Neural Architecture Search for Transformer in Knowledge Tracing
Oct 02, 2023



Knowledge tracing (KT) aims to trace students' knowledge states by predicting whether students answer correctly on exercises. Despite the excellent performance of existing Transformer-based KT approaches, they are criticized for the manually selected input features for fusion and the defect of single global context modelling to directly capture students' forgetting behavior in KT, when the related records are distant from the current record in terms of time. To address the issues, this paper first considers adding convolution operations to the Transformer to enhance its local context modelling ability used for students' forgetting behavior, then proposes an evolutionary neural architecture search approach to automate the input feature selection and automatically determine where to apply which operation for achieving the balancing of the local/global context modelling. In the search space, the original global path containing the attention module in Transformer is replaced with the sum of a global path and a local path that could contain different convolutions, and the selection of input features is also considered. To search the best architecture, we employ an effective evolutionary algorithm to explore the search space and also suggest a search space reduction strategy to accelerate the convergence of the algorithm. Experimental results on the two largest and most challenging education datasets demonstrate the effectiveness of the architecture found by the proposed approach.