 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLacaDM: A Latent Causal Diffusion Model for Multiobjective Reinforcement Learning
Dec 22, 2025Multiobjective reinforcement learning (MORL) poses significant challenges due to the inherent conflicts between objectives and the difficulty of adapting to dynamic environments. Traditional methods often struggle to generalize effectively, particularly in large and complex state-action spaces. To address these limitations, we introduce the Latent Causal Diffusion Model (LacaDM), a novel approach designed to enhance the adaptability of MORL in discrete and continuous environments. Unlike existing methods that primarily address conflicts between objectives, LacaDM learns latent temporal causal relationships between environmental states and policies, enabling efficient knowledge transfer across diverse MORL scenarios. By embedding these causal structures within a diffusion model-based framework, LacaDM achieves a balance between conflicting objectives while maintaining strong generalization capabilities in previously unseen environments. Empirical evaluations on various tasks from the MOGymnasium framework demonstrate that LacaDM consistently outperforms the state-of-art baselines in terms of hypervolume, sparsity, and expected utility maximization, showcasing its effectiveness in complex multiobjective tasks.
OmniMER: Indonesian Multimodal Emotion Recognition via Auxiliary-Enhanced LLM Adaptation
Dec 22, 2025Indonesian, spoken by over 200 million people, remains underserved in multimodal emotion recognition research despite its dominant presence on Southeast Asian social media platforms. We introduce IndoMER, the first multimodal emotion recognition benchmark for Indonesian, comprising 1,944 video segments from 203 speakers with temporally aligned text, audio, and visual annotations across seven emotion categories. The dataset exhibits realistic challenges including cross-modal inconsistency and long-tailed class distributions shaped by Indonesian cultural communication norms. To address these challenges, we propose OmniMER, a multimodal adaptation framework built upon Qwen2.5-Omni that enhances emotion recognition through three auxiliary modality-specific perception tasks: emotion keyword extraction for text, facial expression analysis for video, and prosody analysis for audio. These auxiliary tasks help the model identify emotion-relevant cues in each modality before fusion, reducing reliance on spurious correlations in low-resource settings. Experiments on IndoMER show that OmniMER achieves 0.582 Macro-F1 on sentiment classification and 0.454 on emotion recognition, outperforming the base model by 7.6 and 22.1 absolute points respectively. Cross-lingual evaluation on the Chinese CH-SIMS dataset further demonstrates the generalizability of the proposed framework. The dataset and code are publicly available. https://github.com/yanxm01/INDOMER
A Unified Framework for Combinatorial Optimization Based on Graph Neural Networks
Jun 19, 2024
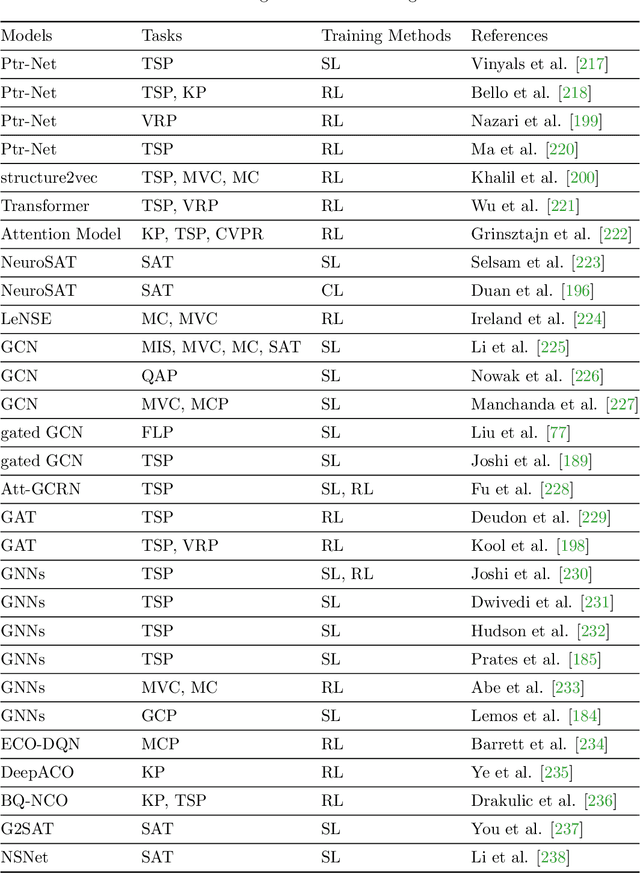


Graph neural networks (GNNs) have emerged as a powerful tool for solving combinatorial optimization problems (COPs), exhibiting state-of-the-art performance in both graph-structured and non-graph-structured domains. However, existing approaches lack a unified framework capable of addressing a wide range of COPs. After presenting a summary of representative COPs and a brief review of recent advancements in GNNs for solving COPs, this paper proposes a unified framework for solving COPs based on GNNs, including graph representation of COPs, equivalent conversion of non-graph structured COPs to graph-structured COPs, graph decomposition, and graph simplification. The proposed framework leverages the ability of GNNs to effectively capture the relational information and extract features from the graph representation of COPs, offering a generic solution to COPs that can address the limitations of state-of-the-art in solving non-graph-structured and highly complex graph-structured COPs.
Federated Incomplete Multi-View Clustering with Heterogeneous Graph Neural Networks
Jun 12, 2024



Federated multi-view clustering offers the potential to develop a global clustering model using data distributed across multiple devices. However, current methods face challenges due to the absence of label information and the paramount importance of data privacy. A significant issue is the feature heterogeneity across multi-view data, which complicates the effective mining of complementary clustering information. Additionally, the inherent incompleteness of multi-view data in a distributed setting can further complicate the clustering process. To address these challenges, we introduce a federated incomplete multi-view clustering framework with heterogeneous graph neural networks (FIM-GNNs). In the proposed FIM-GNNs, autoencoders built on heterogeneous graph neural network models are employed for feature extraction of multi-view data at each client site. At the server level, heterogeneous features from overlapping samples of each client are aggregated into a global feature representation. Global pseudo-labels are generated at the server to enhance the handling of incomplete view data, where these labels serve as a guide for integrating and refining the clustering process across different data views. Comprehensive experiments have been conducted on public benchmark datasets to verify the performance of the proposed FIM-GNNs in comparison with state-of-the-art algorithms.
EmoDM: A Diffusion Model for Evolutionary Multi-objective Optimization
Jan 29, 2024



Evolutionary algorithms have been successful in solving multi-objective optimization problems (MOPs). However, as a class of population-based search methodology, evolutionary algorithms require a large number of evaluations of the objective functions, preventing them from being applied to a wide range of expensive MOPs. To tackle the above challenge, this work proposes for the first time a diffusion model that can learn to perform evolutionary multi-objective search, called EmoDM. This is achieved by treating the reversed convergence process of evolutionary search as the forward diffusion and learn the noise distributions from previously solved evolutionary optimization tasks. The pre-trained EmoDM can then generate a set of non-dominated solutions for a new MOP by means of its reverse diffusion without further evolutionary search, thereby significantly reducing the required function evaluations. To enhance the scalability of EmoDM, a mutual entropy-based attention mechanism is introduced to capture the decision variables that are most important for the objectives. Experimental results demonstrate the competitiveness of EmoDM in terms of both the search performance and computational efficiency compared with state-of-the-art evolutionary algorithms in solving MOPs having up to 5000 decision variables. The pre-trained EmoDM is shown to generalize well to unseen problems, revealing its strong potential as a general and efficient MOP solver.
An Edge-Aware Graph Autoencoder Trained on Scale-Imbalanced Data for Travelling Salesman Problems
Oct 10, 2023Recent years have witnessed a surge in research on machine learning for combinatorial optimization since learning-based approaches can outperform traditional heuristics and approximate exact solvers at a lower computation cost. However, most existing work on supervised neural combinatorial optimization focuses on TSP instances with a fixed number of cities and requires large amounts of training samples to achieve a good performance, making them less practical to be applied to realistic optimization scenarios. This work aims to develop a data-driven graph representation learning method for solving travelling salesman problems (TSPs) with various numbers of cities. To this end, we propose an edge-aware graph autoencoder (EdgeGAE) model that can learn to solve TSPs after being trained on solution data of various sizes with an imbalanced distribution. We formulate the TSP as a link prediction task on sparse connected graphs. A residual gated encoder is trained to learn latent edge embeddings, followed by an edge-centered decoder to output link predictions in an end-to-end manner. To improve the model's generalization capability of solving large-scale problems, we introduce an active sampling strategy into the training process. In addition, we generate a benchmark dataset containing 50,000 TSP instances with a size from 50 to 500 cities, following an extremely scale-imbalanced distribution, making it ideal for investigating the model's performance for practical applications. We conduct experiments using different amounts of training data with various scales, and the experimental results demonstrate that the proposed data-driven approach achieves a highly competitive performance among state-of-the-art learning-based methods for solving TSPs.
Evolutionary Neural Architecture Search for Transformer in Knowledge Tracing
Oct 02, 2023



Knowledge tracing (KT) aims to trace students' knowledge states by predicting whether students answer correctly on exercises. Despite the excellent performance of existing Transformer-based KT approaches, they are criticized for the manually selected input features for fusion and the defect of single global context modelling to directly capture students' forgetting behavior in KT, when the related records are distant from the current record in terms of time. To address the issues, this paper first considers adding convolution operations to the Transformer to enhance its local context modelling ability used for students' forgetting behavior, then proposes an evolutionary neural architecture search approach to automate the input feature selection and automatically determine where to apply which operation for achieving the balancing of the local/global context modelling. In the search space, the original global path containing the attention module in Transformer is replaced with the sum of a global path and a local path that could contain different convolutions, and the selection of input features is also considered. To search the best architecture, we employ an effective evolutionary algorithm to explore the search space and also suggest a search space reduction strategy to accelerate the convergence of the algorithm. Experimental results on the two largest and most challenging education datasets demonstrate the effectiveness of the architecture found by the proposed approach.
Augmented Transformers with Adaptive n-grams Embedding for Multilingual Scene Text Recognition
Feb 28, 2023



While vision transformers have been highly successful in improving the performance in image-based tasks, not much work has been reported on applying transformers to multilingual scene text recognition due to the complexities in the visual appearance of multilingual texts. To fill the gap, this paper proposes an augmented transformer architecture with n-grams embedding and cross-language rectification (TANGER). TANGER consists of a primary transformer with single patch embeddings of visual images, and a supplementary transformer with adaptive n-grams embeddings that aims to flexibly explore the potential correlations between neighbouring visual patches, which is essential for feature extraction from multilingual scene texts. Cross-language rectification is achieved with a loss function that takes into account both language identification and contextual coherence scoring. Extensive comparative studies are conducted on four widely used benchmark datasets as well as a new multilingual scene text dataset containing Indonesian, English, and Chinese collected from tourism scenes in Indonesia. Our experimental results demonstrate that TANGER is considerably better compared to the state-of-the-art, especially in handling complex multilingual scene texts.
A Graph Neural Network with Negative Message Passing for Graph Coloring
Jan 26, 2023



Graph neural networks have received increased attention over the past years due to their promising ability to handle graph-structured data, which can be found in many real-world problems such as recommended systems and drug synthesis. Most existing research focuses on using graph neural networks to solve homophilous problems, but little attention has been paid to heterophily-type problems. In this paper, we propose a graph network model for graph coloring, which is a class of representative heterophilous problems. Different from the conventional graph networks, we introduce negative message passing into the proposed graph neural network for more effective information exchange in handling graph coloring problems. Moreover, a new loss function taking into account the self-information of the nodes is suggested to accelerate the learning process. Experimental studies are carried out to compare the proposed graph model with five state-of-the-art algorithms on ten publicly available graph coloring problems and one real-world application. Numerical results demonstrate the effectiveness of the proposed graph neural network.
End-to-End Pareto Set Prediction with Graph Neural Networks for Multi-objective Facility Location
Oct 27, 2022



The facility location problems (FLPs) are a typical class of NP-hard combinatorial optimization problems, which are widely seen in the supply chain and logistics. Many mathematical and heuristic algorithms have been developed for optimizing the FLP. In addition to the transportation cost, there are usually multiple conflicting objectives in realistic applications. It is therefore desirable to design algorithms that find a set of Pareto solutions efficiently without enormous search cost. In this paper, we consider the multi-objective facility location problem (MO-FLP) that simultaneously minimizes the overall cost and maximizes the system reliability. We develop a learning-based approach to predicting the distribution probability of the entire Pareto set for a given problem. To this end, the MO-FLP is modeled as a bipartite graph optimization problem and two graph neural networks are constructed to learn the implicit graph representation on nodes and edges. The network outputs are then converted into the probability distribution of the Pareto set, from which a set of non-dominated solutions can be sampled non-autoregressively. Experimental results on MO-FLP instances of different scales show that the proposed approach achieves a comparable performance to a widely used multi-objective evolutionary algorithm in terms of the solution quality while significantly reducing the computational cost for search.