 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Temporal Discrepancy as Motion Prior: A Loss-Weighting Strategy for Dynamic Fidelity in T2V
Jan 28, 2026Video generation models have achieved notable progress in static scenarios, yet their performance in motion video generation remains limited, with quality degrading under drastic dynamic changes. This is due to noise disrupting temporal coherence and increasing the difficulty of learning dynamic regions. {Unfortunately, existing diffusion models rely on static loss for all scenarios, constraining their ability to capture complex dynamics.} To address this issue, we introduce Latent Temporal Discrepancy (LTD) as a motion prior to guide loss weighting. LTD measures frame-to-frame variation in the latent space, assigning larger penalties to regions with higher discrepancy while maintaining regular optimization for stable regions. This motion-aware strategy stabilizes training and enables the model to better reconstruct high-frequency dynamics. Extensive experiments on the general benchmark VBench and the motion-focused VMBench show consistent gains, with our method outperforming strong baselines by 3.31% on VBench and 3.58% on VMBench, achieving significant improvements in motion quality.
Artifact-Aware Evaluation for High-Quality Video Generation
Jan 28, 2026With the rapid advancement of video generation techniques, evaluating and auditing generated videos has become increasingly crucial. Existing approaches typically offer coarse video quality scores, lacking detailed localization and categorization of specific artifacts. In this work, we introduce a comprehensive evaluation protocol focusing on three key aspects affecting human perception: Appearance, Motion, and Camera. We define these axes through a taxonomy of 10 prevalent artifact categories reflecting common generative failures observed in video generation. To enable robust artifact detection and categorization, we introduce GenVID, a large-scale dataset of 80k videos generated by various state-of-the-art video generation models, each carefully annotated for the defined artifact categories. Leveraging GenVID, we develop DVAR, a Dense Video Artifact Recognition framework for fine-grained identification and classification of generative artifacts. Extensive experiments show that our approach significantly improves artifact detection accuracy and enables effective filtering of low-quality content.
Ranking-aware Reinforcement Learning for Ordinal Ranking
Jan 28, 2026Ordinal regression and ranking are challenging due to inherent ordinal dependencies that conventional methods struggle to model. We propose Ranking-Aware Reinforcement Learning (RARL), a novel RL framework that explicitly learns these relationships. At its core, RARL features a unified objective that synergistically integrates regression and Learning-to-Rank (L2R), enabling mutual improvement between the two tasks. This is driven by a ranking-aware verifiable reward that jointly assesses regression precision and ranking accuracy, facilitating direct model updates via policy optimization. To further enhance training, we introduce Response Mutation Operations (RMO), which inject controlled noise to improve exploration and prevent stagnation at saddle points. The effectiveness of RARL is validated through extensive experiments on three distinct benchmarks.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
API: Empowering Generalizable Real-World Image Dehazing via Adaptive Patch Importance Learning
Jan 05, 2026Real-world image dehazing is a fundamental yet challenging task in low-level vision. Existing learning-based methods often suffer from significant performance degradation when applied to complex real-world hazy scenes, primarily due to limited training data and the intrinsic complexity of haze density distributions.To address these challenges, we introduce a novel Adaptive Patch Importance-aware (API) framework for generalizable real-world image dehazing. Specifically, our framework consists of an Automatic Haze Generation (AHG) module and a Density-aware Haze Removal (DHR) module. AHG provides a hybrid data augmentation strategy by generating realistic and diverse hazy images as additional high-quality training data. DHR considers hazy regions with varying haze density distributions for generalizable real-world image dehazing in an adaptive patch importance-aware manner. To alleviate the ambiguity of the dehazed image details, we further introduce a new Multi-Negative Contrastive Dehazing (MNCD) loss, which fully utilizes information from multiple negative samples across both spatial and frequency domains. Extensive experiments demonstrate that our framework achieves state-of-the-art performance across multiple real-world benchmarks, delivering strong results in both quantitative metrics and qualitative visual quality, and exhibiting robust generalization across diverse haze distributions.
Nighttime Hazy Image Enhancement via Progressively and Mutually Reinforcing Night-Haze Priors
Jan 05, 2026Enhancing the visibility of nighttime hazy images is challenging due to the complex degradation distributions. Existing methods mainly address a single type of degradation (e.g., haze or low-light) at a time, ignoring the interplay of different degradation types and resulting in limited visibility improvement. We observe that the domain knowledge shared between low-light and haze priors can be reinforced mutually for better visibility. Based on this key insight, in this paper, we propose a novel framework that enhances visibility in nighttime hazy images by reinforcing the intrinsic consistency between haze and low-light priors mutually and progressively. In particular, our model utilizes image-, patch-, and pixel-level experts that operate across visual and frequency domains to recover global scene structure, regional patterns, and fine-grained details progressively. A frequency-aware router is further introduced to adaptively guide the contribution of each expert, ensuring robust image restoration. Extensive experiments demonstrate the superior performance of our model on nighttime dehazing benchmarks both quantitatively and qualitatively. Moreover, we showcase the generalizability of our model in daytime dehazing and low-light enhancement tasks.
Rate Maximization for UAV-assisted ISAC System with Fluid Antennas
Oct 09, 2025This letter investigates the joint sensing problem between unmanned aerial vehicles (UAV) and base stations (BS) in integrated sensing and communication (ISAC) systems with fluid antennas (FA). In this system, the BS enhances its sensing performance through the UAV's perception system. We aim to maximize the communication rate between the BS and UAV while guaranteeing the joint system's sensing capability. By establishing a communication-sensing model with convex optimization properties, we decompose the problem and apply convex optimization to progressively solve key variables. An iterative algorithm employing an alternating optimization approach is subsequently developed to determine the optimal solution, significantly reducing the solution complexity. Simulation results validate the algorithm's effectiveness in balancing system performance.
FoMo4Wheat: Toward reliable crop vision foundation models with globally curated data
Sep 08, 2025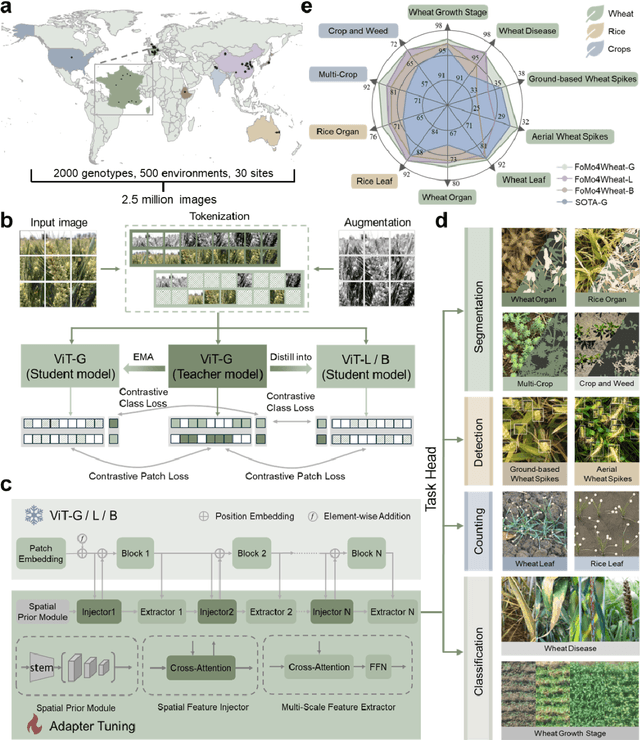

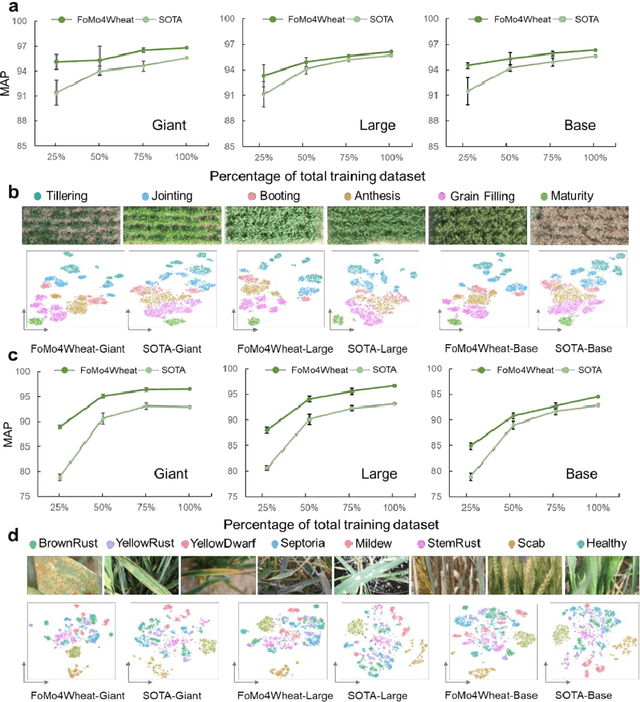
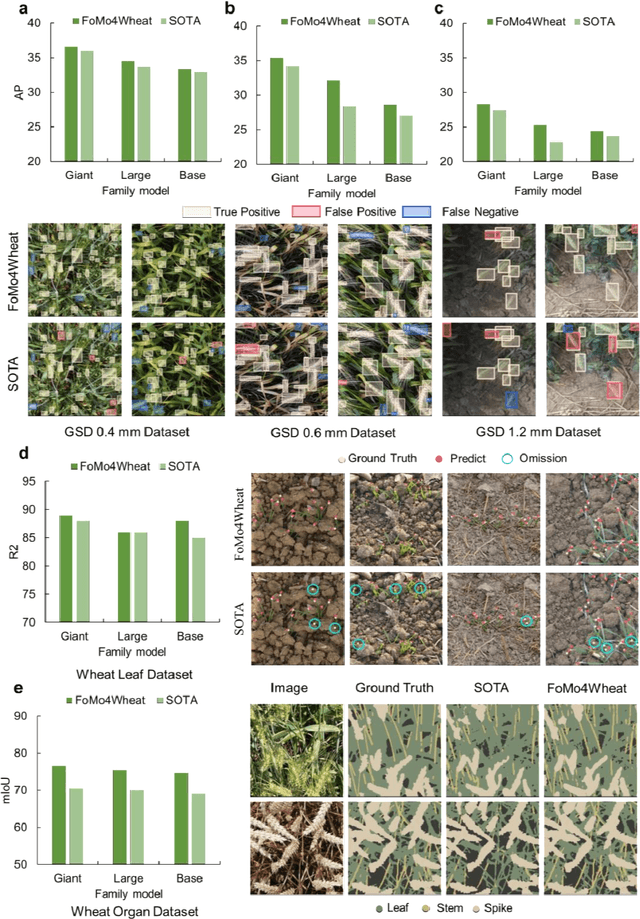
Vision-driven field monitoring is central to digital agriculture, yet models built on general-domain pretrained backbones often fail to generalize across tasks, owing to the interaction of fine, variable canopy structures with fluctuating field conditions. We present FoMo4Wheat, one of the first crop-domain vision foundation model pretrained with self-supervision on ImAg4Wheat, the largest and most diverse wheat image dataset to date (2.5 million high-resolution images collected over a decade at 30 global sites, spanning >2,000 genotypes and >500 environmental conditions). This wheat-specific pretraining yields representations that are robust for wheat and transferable to other crops and weeds. Across ten in-field vision tasks at canopy and organ levels, FoMo4Wheat models consistently outperform state-of-the-art models pretrained on general-domain dataset. These results demonstrate the value of crop-specific foundation models for reliable in-field perception and chart a path toward a universal crop foundation model with cross-species and cross-task capabilities. FoMo4Wheat models and the ImAg4Wheat dataset are publicly available online: https://github.com/PheniX-Lab/FoMo4Wheat and https://huggingface.co/PheniX-Lab/FoMo4Wheat. The demonstration website is: https://fomo4wheat.phenix-lab.com/.
E-React: Towards Emotionally Controlled Synthesis of Human Reactions
Aug 08, 2025Emotion serves as an essential component in daily human interactions. Existing human motion generation frameworks do not consider the impact of emotions, which reduces naturalness and limits their application in interactive tasks, such as human reaction synthesis. In this work, we introduce a novel task: generating diverse reaction motions in response to different emotional cues. However, learning emotion representation from limited motion data and incorporating it into a motion generation framework remains a challenging problem. To address the above obstacles, we introduce a semi-supervised emotion prior in an actor-reactor diffusion model to facilitate emotion-driven reaction synthesis. Specifically, based on the observation that motion clips within a short sequence tend to share the same emotion, we first devise a semi-supervised learning framework to train an emotion prior. With this prior, we further train an actor-reactor diffusion model to generate reactions by considering both spatial interaction and emotional response. Finally, given a motion sequence of an actor, our approach can generate realistic reactions under various emotional conditions. Experimental results demonstrate that our model outperforms existing reaction generation methods. The code and data will be made publicly available at https://ereact.github.io/
Scene Graph-Aided Probabilistic Semantic Communication for Image Transmission
Jul 16, 2025Semantic communication emphasizes the transmission of meaning rather than raw symbols. It offers a promising solution to alleviate network congestion and improve transmission efficiency. In this paper, we propose a wireless image communication framework that employs probability graphs as shared semantic knowledge base among distributed users. High-level image semantics are represented via scene graphs, and a two-stage compression algorithm is devised to remove predictable components based on learned conditional and co-occurrence probabilities. At the transmitter, the algorithm filters redundant relations and entity pairs, while at the receiver, semantic recovery leverages the same probability graphs to reconstruct omitted information. For further research, we also put forward a multi-round semantic compression algorithm with its theoretical performance analysis. Simulation results demonstrate that our semantic-aware scheme achieves superior transmission throughput and satiable semantic alignment, validating the efficacy of leveraging high-level semantics for image communication.