 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Hybrid Beamforming with Liquid Crystal Antennas and Liquid Neural Networks
Apr 08, 2026Sub-terahertz (sub-THz) multi-user multiple-input multiple-output (MU-MIMO) systems unlock immense bandwidth for 6G wireless communications. However, practical deployment of wireless systems in sub-THz bands faces critical challenges such as increased atmospheric absorption, reduced channel coherence time due to increased Doppler spread at higher carrier frequencies, and hardware bottlenecks as low-loss sub-THz phase shifters are difficult to realize. To overcome the hardware and channel estimation challenges of sub-THz systems, this paper proposes a hybrid beamforming (BF) framework that integrates reconfigurable liquid crystal (LC) antennas with a liquid neural network (LNN) for transmitter. Specifically, we employ an LC antenna as the analog BF stage of a hybrid BF architecture, exploiting its voltage-driven permittivity tunability to achieve high-gain beam steering without the need for lossy phase shifters. For digital BF, we utilize an ordinary differential equations-defined LNN to learn temporal channel dynamics, and use a manifold optimization technique to compress the search space. We validated the proposed method on simulated site-specific 108 GHz ray-tracing channels in an urban scenario using NYURay, a ray-tracing simulator validated against 142 GHz propagation measurements. The 108 GHz carrier frequency matches the operating band of the LC antenna hardware. The proposed method achieves an 88.6\% spectral efficiency (SE) gain and higher robustness to imperfect channel estimation compared to the learning-aided gradient descent and gated recurrent unit machine learning baselines, and 1.9 times higher SE than the 3GPP TR~38.901 standard antenna model, highlighting the potential of LC-based hardware for sub-THz communications.
NYUSIM: A Roadmap to AI-Enabled Statistical Channel Modeling and Simulation
Feb 17, 2026Integrating artificial intelligence (AI) into wireless channel modeling requires large, accurate, and physically consistent datasets derived from real measurements. Such datasets are essential for training and validating models that learn spatio-temporal channel behavior across frequencies and environments. NYUSIM, introduced by NYU WIRELESS in 2016, generates realistic spatio-temporal channel data using extensive outdoor and indoor measurements between 28 and 142 GHz. To improve scalability and support 6G research, we migrated the complete NYUSIM framework from MATLAB to Python, and are incorporating new statistical model generation capabilities from extensive field measurements in the new 6G upper mid-band spectrum at 6.75 GHz (FR1(C)) and 16.95 GHz (FR3) [1]. The NYUSIM Python also incorporates a 3D antenna data format, referred to as Ant3D, which is a standardized, full-sphere format for defining canonical, commercial, or measured antenna patterns for any statistical or site-specific ray tracing modeling tool. Migration from MATLAB to Python was rigorously validated through Kolmogorov-Smirnov (K-S) tests, moment analysis, and end-to-end testing with unified randomness control, confirming statistical consistency and reproduction of spatio-temporal channel statistics, including spatial consistency with the open-source MATLAB NYUSIM v4.0 implementation. The NYUSIM Python version is designed to integrate with modern AI workflows and enable large-scale parallel data generation, establishing a robust, verified, and extensible foundation for future AI-enabled channel modeling.
HoRAMA: Holistic Reconstruction with Automated Material Assignment for Ray Tracing using NYURay
Feb 13, 2026Next-generation wireless networks at upper mid-band and millimeter-wave frequencies require accurate site-specific deterministic channel propagation prediction. Wireless ray tracing (RT) provides site-specific predictions but demands high-fidelity three-dimensional (3D) environment models with material properties. Manual 3D model reconstruction achieves high accuracy but requires weeks of expert effort, creating scalability bottlenecks for large environment reconstruction. Traditional vision-based 3D reconstruction methods lack RT compatibility due to geometrically defective meshes and missing material properties. This paper presents Holistic Reconstruction with Automated Material Assignment (HoRAMA) for wireless propagation prediction using NYURay. HoRAMA generates RT-compatible 3D models from RGB video readily captured using a smartphone or low-cost portable camera, by integrating MASt3R-SLAM dense point cloud generation with vision language model-assisted material assignment. The HoRAMA 3D reconstruction method is verified by comparing NYURay RT predictions, using both manually created and HoRAMA-generated 3D models, against field measurements at 6.75 GHz and 16.95 GHz across 12 TX-RX locations in a 700 square meter factory. HoRAMA ray tracing predictions achieve a 2.28 dB RMSE for matched multipath component (MPC) power predictions, comparable to the manually created 3D model baseline (2.18 dB), while reducing 3D reconstruction time from two months to 16 hours. HoRAMA enables scalable wireless digital twin creation for RT network planning, infrastructure deployment, and beam management in 5G/6G systems, as well as eventual real-time implementation at the edge.
Robust Deep Learning-Based Physical Layer Communications: Strategies and Approaches
May 02, 2025Deep learning (DL) has emerged as a transformative technology with immense potential to reshape the sixth-generation (6G) wireless communication network. By utilizing advanced algorithms for feature extraction and pattern recognition, DL provides unprecedented capabilities in optimizing the network efficiency and performance, particularly in physical layer communications. Although DL technologies present the great potential, they also face significant challenges related to the robustness, which are expected to intensify in the complex and demanding 6G environment. Specifically, current DL models typically exhibit substantial performance degradation in dynamic environments with time-varying channels, interference of noise and different scenarios, which affect their effectiveness in diverse real-world applications. This paper provides a comprehensive overview of strategies and approaches for robust DL-based methods in physical layer communications. First we introduce the key challenges that current DL models face. Then we delve into a detailed examination of DL approaches specifically tailored to enhance robustness in 6G, which are classified into data-driven and model-driven strategies. Finally, we verify the effectiveness of these methods by case studies and outline future research directions.
Wireless Large AI Model: Shaping the AI-Native Future of 6G and Beyond
Apr 20, 2025The emergence of sixth-generation and beyond communication systems is expected to fundamentally transform digital experiences through introducing unparalleled levels of intelligence, efficiency, and connectivity. A promising technology poised to enable this revolutionary vision is the wireless large AI model (WLAM), characterized by its exceptional capabilities in data processing, inference, and decision-making. In light of these remarkable capabilities, this paper provides a comprehensive survey of WLAM, elucidating its fundamental principles, diverse applications, critical challenges, and future research opportunities. We begin by introducing the background of WLAM and analyzing the key synergies with wireless networks, emphasizing the mutual benefits. Subsequently, we explore the foundational characteristics of WLAM, delving into their unique relevance in wireless environments. Then, the role of WLAM in optimizing wireless communication systems across various use cases and the reciprocal benefits are systematically investigated. Furthermore, we discuss the integration of WLAM with emerging technologies, highlighting their potential to enable transformative capabilities and breakthroughs in wireless communication. Finally, we thoroughly examine the high-level challenges hindering the practical implementation of WLAM and discuss pivotal future research directions.
Liquid Neural Networks: Next-Generation AI for Telecom from First Principles
Apr 03, 2025Artificial intelligence (AI) has emerged as a transformative technology with immense potential to reshape the next-generation of wireless networks. By leveraging advanced algorithms and machine learning techniques, AI offers unprecedented capabilities in optimizing network performance, enhancing data processing efficiency, and enabling smarter decision-making processes. However, existing AI solutions face significant challenges in terms of robustness and interpretability. Specifically, current AI models exhibit substantial performance degradation in dynamic environments with varying data distributions, and the black-box nature of these algorithms raises concerns regarding safety, transparency, and fairness. This presents a major challenge in integrating AI into practical communication systems. Recently, a novel type of neural network, known as the liquid neural networks (LNNs), has been designed from first principles to address these issues. In this paper, we explore the potential of LNNs in telecommunications. First, we illustrate the mechanisms of LNNs and highlight their unique advantages over traditional networks. Then we unveil the opportunities that LNNs bring to future wireless networks. Furthermore, we discuss the challenges and design directions for the implementation of LNNs. Finally, we summarize the performance of LNNs in two case studies.
TeleMoM: Consensus-Driven Telecom Intelligence via Mixture of Models
Apr 03, 2025Large language models (LLMs) face significant challenges in specialized domains like telecommunication (Telecom) due to technical complexity, specialized terminology, and rapidly evolving knowledge. Traditional methods, such as scaling model parameters or retraining on domain-specific corpora, are computationally expensive and yield diminishing returns, while existing approaches like retrieval-augmented generation, mixture of experts, and fine-tuning struggle with accuracy, efficiency, and coordination. To address this issue, we propose Telecom mixture of models (TeleMoM), a consensus-driven ensemble framework that integrates multiple LLMs for enhanced decision-making in Telecom. TeleMoM employs a two-stage process: proponent models generate justified responses, and an adjudicator finalizes decisions, supported by a quality-checking mechanism. This approach leverages strengths of diverse models to improve accuracy, reduce biases, and handle domain-specific complexities effectively. Evaluation results demonstrate that TeleMoM achieves a 9.7\% increase in answer accuracy, highlighting its effectiveness in Telecom applications.
Large-Scale AI in Telecom: Charting the Roadmap for Innovation, Scalability, and Enhanced Digital Experiences
Mar 06, 2025



This white paper discusses the role of large-scale AI in the telecommunications industry, with a specific focus on the potential of generative AI to revolutionize network functions and user experiences, especially in the context of 6G systems. It highlights the development and deployment of Large Telecom Models (LTMs), which are tailored AI models designed to address the complex challenges faced by modern telecom networks. The paper covers a wide range of topics, from the architecture and deployment strategies of LTMs to their applications in network management, resource allocation, and optimization. It also explores the regulatory, ethical, and standardization considerations for LTMs, offering insights into their future integration into telecom infrastructure. The goal is to provide a comprehensive roadmap for the adoption of LTMs to enhance scalability, performance, and user-centric innovation in telecom networks.
Robust Beamforming with Gradient-based Liquid Neural Network
May 17, 2024Millimeter-wave (mmWave) multiple-input multiple-output (MIMO) communication with the advanced beamforming technologies is a key enabler to meet the growing demands of future mobile communication. However, the dynamic nature of cellular channels in large-scale urban mmWave MIMO communication scenarios brings substantial challenges, particularly in terms of complexity and robustness. To address these issues, we propose a robust gradient-based liquid neural network (GLNN) framework that utilizes ordinary differential equation-based liquid neurons to solve the beamforming problem. Specifically, our proposed GLNN framework takes gradients of the optimization objective function as inputs to extract the high-order channel feature information, and then introduces a residual connection to mitigate the training burden. Furthermore, we use the manifold learning technique to compress the search space of the beamforming problem. These designs enable the GLNN to effectively maintain low complexity while ensuring strong robustness to noisy and highly dynamic channels. Extensive simulation results demonstrate that the GLNN can achieve 4.15% higher spectral efficiency than that of typical iterative algorithms, and reduce the time consumption to only 1.61% that of conventional methods.
Robust Continuous-Time Beam Tracking with Liquid Neural Network
May 01, 2024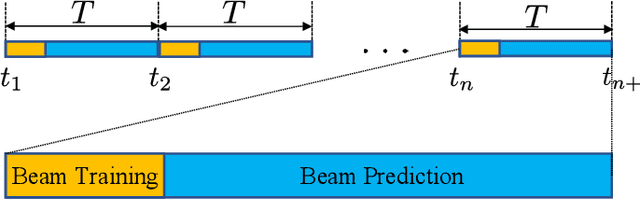
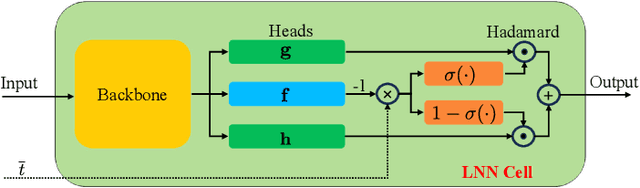
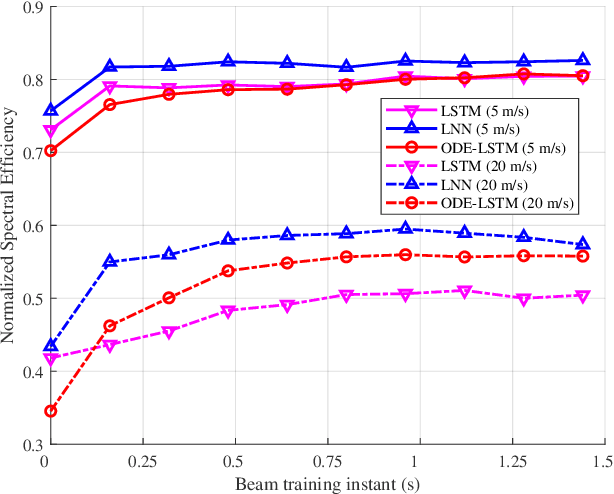
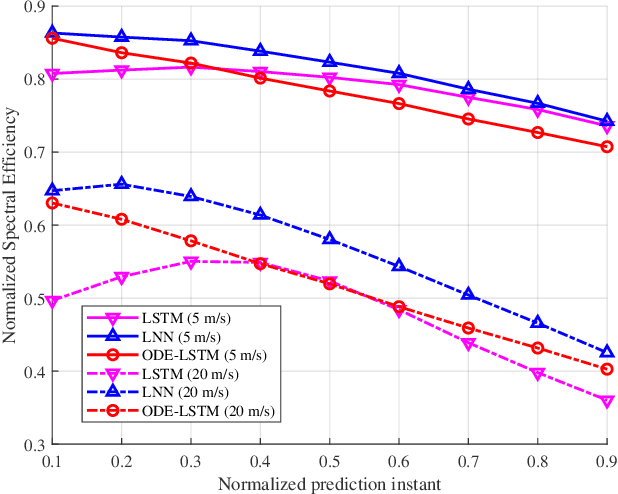
Millimeter-wave (mmWave) technology is increasingly recognized as a pivotal technology of the sixth-generation communication networks due to the large amounts of available spectrum at high frequencies. However, the huge overhead associated with beam training imposes a significant challenge in mmWave communications, particularly in urban environments with high background noise. To reduce this high overhead, we propose a novel solution for robust continuous-time beam tracking with liquid neural network, which dynamically adjust the narrow mmWave beams to ensure real-time beam alignment with mobile users. Through extensive simulations, we validate the effectiveness of our proposed method and demonstrate its superiority over existing state-of-the-art deep-learning-based approaches. Specifically, our scheme achieves at most 46.9% higher normalized spectral efficiency than the baselines when the user is moving at 5 m/s, demonstrating the potential of liquid neural networks to enhance mmWave mobile communication performance.