 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Collaborate Over Graphs: A Selective Federated Multi-Task Learning Approach
Jun 11, 2025We present a novel federated multi-task learning method that leverages cross-client similarity to enable personalized learning for each client. To avoid transmitting the entire model to the parameter server, we propose a communication-efficient scheme that introduces a feature anchor, a compact vector representation that summarizes the features learned from the client's local classes. This feature anchor is shared with the server to account for local clients' distribution. In addition, the clients share the classification heads, a lightweight linear layer, and perform a graph-based regularization to enable collaboration among clients. By modeling collaboration between clients as a dynamic graph and continuously updating and refining this graph, we can account for any drift from the clients. To ensure beneficial knowledge transfer and prevent negative collaboration, we leverage a community detection-based approach that partitions this dynamic graph into homogeneous communities, maximizing the sum of task similarities, represented as the graph edges' weights, within each community. This mechanism restricts collaboration to highly similar clients within their formed communities, ensuring positive interaction and preserving personalization. Extensive experiments on two heterogeneous datasets demonstrate that our method significantly outperforms state-of-the-art baselines. Furthermore, we show that our method exhibits superior computation and communication efficiency and promotes fairness across clients.
Large-Scale AI in Telecom: Charting the Roadmap for Innovation, Scalability, and Enhanced Digital Experiences
Mar 06, 2025



This white paper discusses the role of large-scale AI in the telecommunications industry, with a specific focus on the potential of generative AI to revolutionize network functions and user experiences, especially in the context of 6G systems. It highlights the development and deployment of Large Telecom Models (LTMs), which are tailored AI models designed to address the complex challenges faced by modern telecom networks. The paper covers a wide range of topics, from the architecture and deployment strategies of LTMs to their applications in network management, resource allocation, and optimization. It also explores the regulatory, ethical, and standardization considerations for LTMs, offering insights into their future integration into telecom infrastructure. The goal is to provide a comprehensive roadmap for the adoption of LTMs to enhance scalability, performance, and user-centric innovation in telecom networks.
MIRA: A Method of Federated MultI-Task Learning for LaRge LAnguage Models
Oct 20, 2024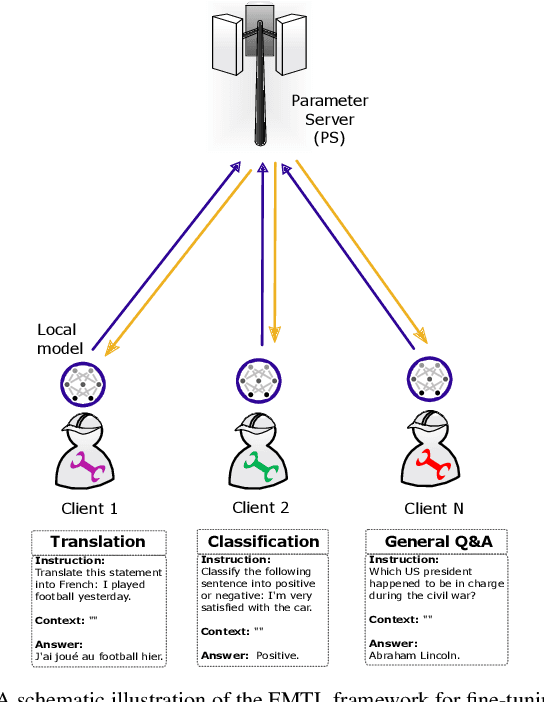
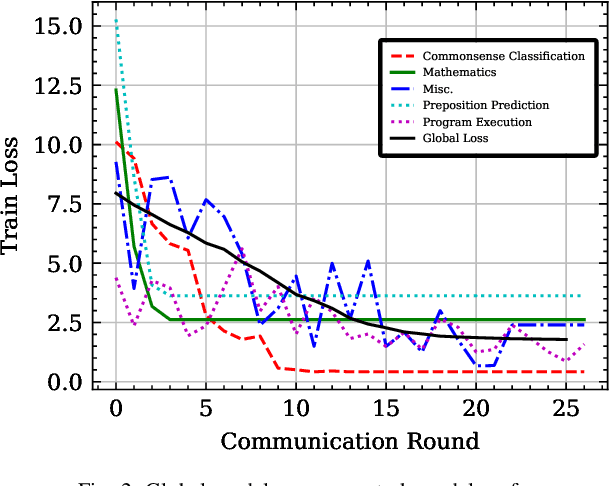
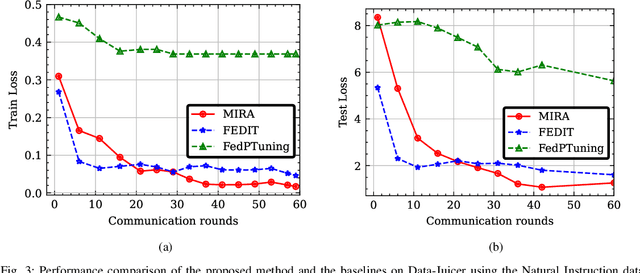
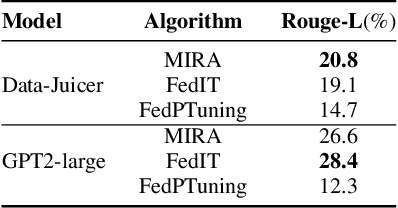
In this paper, we introduce a method for fine-tuning Large Language Models (LLMs), inspired by Multi-Task learning in a federated manner. Our approach leverages the structure of each client's model and enables a learning scheme that considers other clients' tasks and data distribution. To mitigate the extensive computational and communication overhead often associated with LLMs, we utilize a parameter-efficient fine-tuning method, specifically Low-Rank Adaptation (LoRA), reducing the number of trainable parameters. Experimental results, with different datasets and models, demonstrate the proposed method's effectiveness compared to existing frameworks for federated fine-tuning of LLMs in terms of average and local performances. The proposed scheme outperforms existing baselines by achieving lower local loss for each client while maintaining comparable global performance.
Fed-Sophia: A Communication-Efficient Second-Order Federated Learning Algorithm
Jun 10, 2024



Federated learning is a machine learning approach where multiple devices collaboratively learn with the help of a parameter server by sharing only their local updates. While gradient-based optimization techniques are widely adopted in this domain, the curvature information that second-order methods exhibit is crucial to guide and speed up the convergence. This paper introduces a scalable second-order method, allowing the adoption of curvature information in federated large models. Our method, coined Fed-Sophia, combines a weighted moving average of the gradient with a clipping operation to find the descent direction. In addition to that, a lightweight estimation of the Hessian's diagonal is used to incorporate the curvature information. Numerical evaluation shows the superiority, robustness, and scalability of the proposed Fed-Sophia scheme compared to first and second-order baselines.