 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAUV Trajectory Learning for Underwater Acoustic Energy Transfer and Age Minimization
Jan 13, 2026Internet of underwater things (IoUT) is increasingly gathering attention with the aim of monitoring sea life and deep ocean environment, underwater surveillance as well as maintenance of underwater installments. However, conventional IoUT devices, reliant on battery power, face limitations in lifespan and pose environmental hazards upon disposal. This paper introduces a sustainable approach for simultaneous information uplink from the IoUT devices and acoustic energy transfer (AET) to the devices via an autonomous underwater vehicle (AUV), potentially enabling them to operate indefinitely. To tackle the time-sensitivity, we adopt age of information (AoI), and Jain's fairness index. We develop two deep-reinforcement learning (DRL) algorithms, offering a high-complexity, high-performance frequency division duplex (FDD) solution and a low-complexity, medium-performance time division duplex (TDD) approach. The results elucidate that the proposed FDD and TDD solutions significantly reduce the average AoI and boost the harvested energy as well as data collection fairness compared to baseline approaches.
Age and Power Minimization via Meta-Deep Reinforcement Learning in UAV Networks
Jan 24, 2025



Age-of-information (AoI) and transmission power are crucial performance metrics in low energy wireless networks, where information freshness is of paramount importance. This study examines a power-limited internet of things (IoT) network supported by a flying unmanned aerial vehicle(UAV) that collects data. Our aim is to optimize the UAV flight trajectory and scheduling policy to minimize a varying AoI and transmission power combination. To tackle this variation, this paper proposes a meta-deep reinforcement learning (RL) approach that integrates deep Q-networks (DQNs) with model-agnostic meta-learning (MAML). DQNs determine optimal UAV decisions, while MAML enables scalability across varying objective functions. Numerical results indicate that the proposed algorithm converges faster and adapts to new objectives more effectively than traditional deep RL methods, achieving minimal AoI and transmission power overall.
MetaGraphLoc: A Graph-based Meta-learning Scheme for Indoor Localization via Sensor Fusion
Nov 26, 2024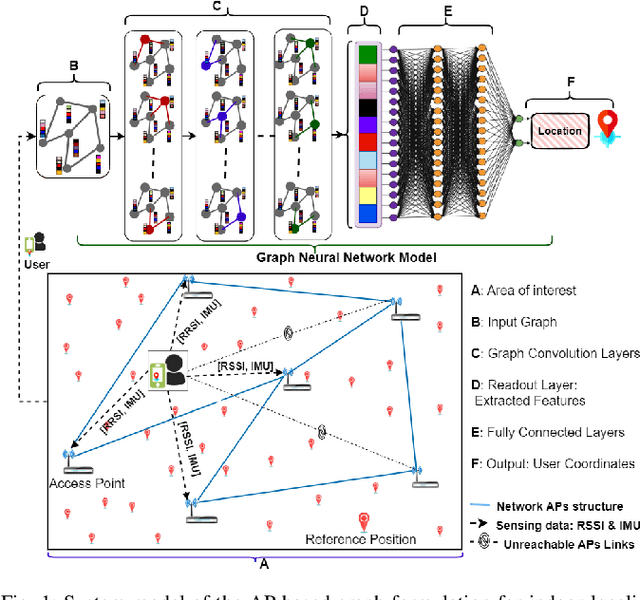
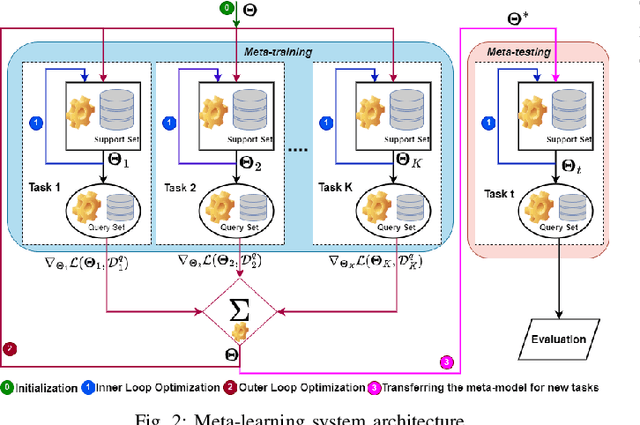
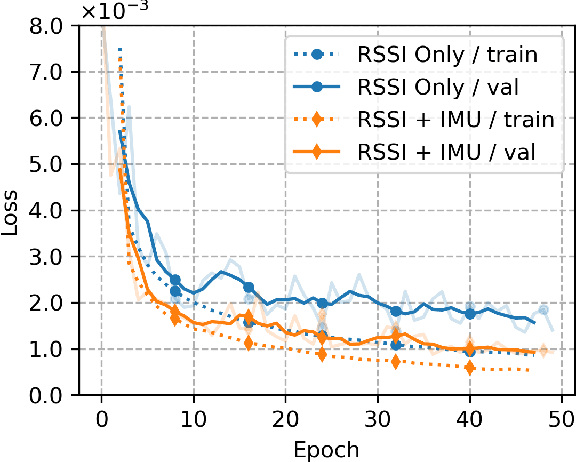
Accurate indoor localization remains challenging due to variations in wireless signal environments and limited data availability. This paper introduces MetaGraphLoc, a novel system leveraging sensor fusion, graph neural networks (GNNs), and meta-learning to overcome these limitations. MetaGraphLoc integrates received signal strength indicator measurements with inertial measurement unit data to enhance localization accuracy. Our proposed GNN architecture, featuring dynamic edge construction (DEC), captures the spatial relationships between access points and underlying data patterns. MetaGraphLoc employs a meta-learning framework to adapt the GNN model to new environments with minimal data collection, significantly reducing calibration efforts. Extensive evaluations demonstrate the effectiveness of MetaGraphLoc. Data fusion reduces localization error by 15.92%, underscoring its importance. The GNN with DEC outperforms traditional deep neural networks by up to 30.89%, considering accuracy. Furthermore, the meta-learning approach enables efficient adaptation to new environments, minimizing data collection requirements. These advancements position MetaGraphLoc as a promising solution for indoor localization, paving the way for improved navigation and location-based services in the ever-evolving Internet of Things networks.
TinyML NLP Approach for Semantic Wireless Sentiment Classification
Nov 09, 2024



Natural Language Processing (NLP) operations, such as semantic sentiment analysis and text synthesis, may often impair users' privacy and demand significant on device computational resources. Centralized learning (CL) on the edge offers an alternative energy-efficient approach, yet requires the collection of raw information, which affects the user's privacy. While Federated learning (FL) preserves privacy, it requires high computational energy on board tiny user devices. We introduce split learning (SL) as an energy-efficient alternative, privacy-preserving tiny machine learning (TinyML) scheme and compare it to FL and CL in the presence of Rayleigh fading and additive noise. Our results show that SL reduces processing power and CO2 emissions while maintaining high accuracy, whereas FL offers a balanced compromise between efficiency and privacy. Hence, this study provides insights into deploying energy-efficient, privacy-preserving NLP models on edge devices.
Five Key Enablers for Communication during and after Disasters
Sep 10, 2024



Civilian communication during disasters such as earthquakes, floods, and military conflicts is crucial for saving lives. Nevertheless, several challenges exist during these circumstances such as the destruction of cellular communication and electricity infrastructure, lack of line of sight (LoS), and difficulty of localization under the rubble. In this article, we discuss key enablers that can boost communication during disasters, namely, satellite and aerial platforms, redundancy, silencing, and sustainable networks aided with wireless energy transfer (WET). The article also highlights how these solutions can be implemented in order to solve the failure of communication during disasters. Finally, it sheds light on unresolved challenges, as well as future research directions.
Fed-Sophia: A Communication-Efficient Second-Order Federated Learning Algorithm
Jun 10, 2024



Federated learning is a machine learning approach where multiple devices collaboratively learn with the help of a parameter server by sharing only their local updates. While gradient-based optimization techniques are widely adopted in this domain, the curvature information that second-order methods exhibit is crucial to guide and speed up the convergence. This paper introduces a scalable second-order method, allowing the adoption of curvature information in federated large models. Our method, coined Fed-Sophia, combines a weighted moving average of the gradient with a clipping operation to find the descent direction. In addition to that, a lightweight estimation of the Hessian's diagonal is used to incorporate the curvature information. Numerical evaluation shows the superiority, robustness, and scalability of the proposed Fed-Sophia scheme compared to first and second-order baselines.
Conservative and Risk-Aware Offline Multi-Agent Reinforcement Learning for Digital Twins
Feb 13, 2024



Digital twin (DT) platforms are increasingly regarded as a promising technology for controlling, optimizing, and monitoring complex engineering systems such as next-generation wireless networks. An important challenge in adopting DT solutions is their reliance on data collected offline, lacking direct access to the physical environment. This limitation is particularly severe in multi-agent systems, for which conventional multi-agent reinforcement (MARL) requires online interactions with the environment. A direct application of online MARL schemes to an offline setting would generally fail due to the epistemic uncertainty entailed by the limited availability of data. In this work, we propose an offline MARL scheme for DT-based wireless networks that integrates distributional RL and conservative Q-learning to address the environment's inherent aleatoric uncertainty and the epistemic uncertainty arising from limited data. To further exploit the offline data, we adapt the proposed scheme to the centralized training decentralized execution framework, allowing joint training of the agents' policies. The proposed MARL scheme, referred to as multi-agent conservative quantile regression (MA-CQR) addresses general risk-sensitive design criteria and is applied to the trajectory planning problem in drone networks, showcasing its advantages.
Traffic Learning and Proactive UAV Trajectory Planning for Data Uplink in Markovian IoT Models
Jan 24, 2024The age of information (AoI) is used to measure the freshness of the data. In IoT networks, the traditional resource management schemes rely on a message exchange between the devices and the base station (BS) before communication which causes high AoI, high energy consumption, and low reliability. Unmanned aerial vehicles (UAVs) as flying BSs have many advantages in minimizing the AoI, energy-saving, and throughput improvement. In this paper, we present a novel learning-based framework that estimates the traffic arrival of IoT devices based on Markovian events. The learning proceeds to optimize the trajectory of multiple UAVs and their scheduling policy. First, the BS predicts the future traffic of the devices. We compare two traffic predictors: the forward algorithm (FA) and the long short-term memory (LSTM). Afterward, we propose a deep reinforcement learning (DRL) approach to optimize the optimal policy of each UAV. Finally, we manipulate the optimum reward function for the proposed DRL approach. Simulation results show that the proposed algorithm outperforms the random-walk (RW) baseline model regarding the AoI, scheduling accuracy, and transmission power.
Age Minimization in Massive IoT via UAV Swarm: A Multi-agent Reinforcement Learning Approach
Sep 26, 2023In many massive IoT communication scenarios, the IoT devices require coverage from dynamic units that can move close to the IoT devices and reduce the uplink energy consumption. A robust solution is to deploy a large number of UAVs (UAV swarm) to provide coverage and a better line of sight (LoS) for the IoT network. However, the study of these massive IoT scenarios with a massive number of serving units leads to high dimensional problems with high complexity. In this paper, we apply multi-agent deep reinforcement learning to address the high-dimensional problem that results from deploying a swarm of UAVs to collect fresh information from IoT devices. The target is to minimize the overall age of information in the IoT network. The results reveal that both cooperative and partially cooperative multi-agent deep reinforcement learning approaches are able to outperform the high-complexity centralized deep reinforcement learning approach, which stands helpless in large-scale networks.
Meta-Learning Based Few Pilots Demodulation and Interference Cancellation For NOMA Uplink
Jun 09, 2023Non-Orthogonal Multiple Access (NOMA) is at the heart of a paradigm shift towards non-orthogonal communication due to its potential to scale well in massive deployments. Nevertheless, the overhead of channel estimation remains a key challenge in such scenarios. This paper introduces a data-driven, meta-learning-aided NOMA uplink model that minimizes the channel estimation overhead and does not require perfect channel knowledge. Unlike conventional deep learning successive interference cancellation (SICNet), Meta-Learning aided SIC (meta-SICNet) is able to share experience across different devices, facilitating learning for new incoming devices while reducing training overhead. Our results confirm that meta-SICNet outperforms classical SIC and conventional SICNet as it can achieve a lower symbol error rate with fewer pilots.