 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-UAV Path Learning for Age and Power Optimization in IoT with UAV Battery Recharge
Jan 09, 2023



In many emerging Internet of Things (IoT) applications, the freshness of the is an important design criterion. Age of Information (AoI) quantifies the freshness of the received information or status update. This work considers a setup of deployed IoT devices in an IoT network; multiple unmanned aerial vehicles (UAVs) serve as mobile relay nodes between the sensors and the base station. We formulate an optimization problem to jointly plan the UAVs' trajectory, while minimizing the AoI of the received messages and the devices' energy consumption. The solution accounts for the UAVs' battery lifetime and flight time to recharging depots to ensure the UAVs' green operation. The complex optimization problem is efficiently solved using a deep reinforcement learning algorithm. In particular, we propose a deep Q-network, which works as a function approximation to estimate the state-action value function. The proposed scheme is quick to converge and results in a lower ergodic age and ergodic energy consumption when compared with benchmark algorithms such as greedy algorithm (GA), nearest neighbour (NN), and random-walk (RW).
A Learning-Based Trajectory Planning of Multiple UAVs for AoI Minimization in IoT Networks
Sep 13, 2022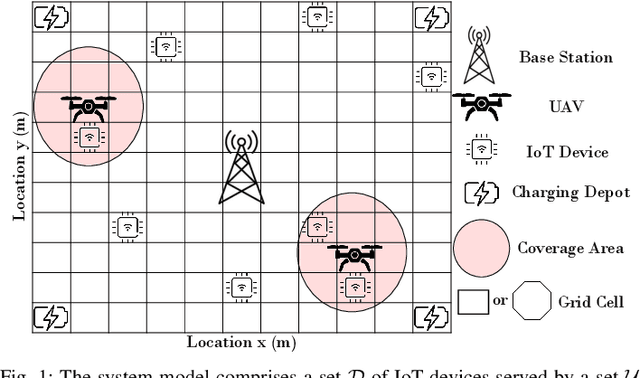
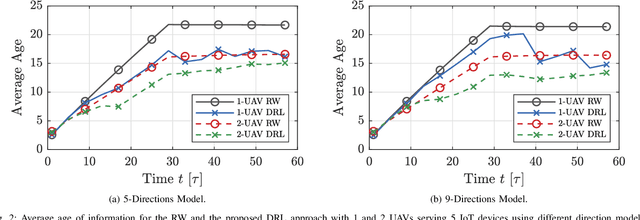
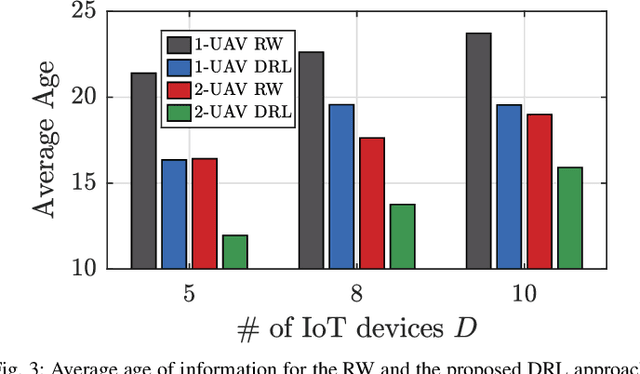
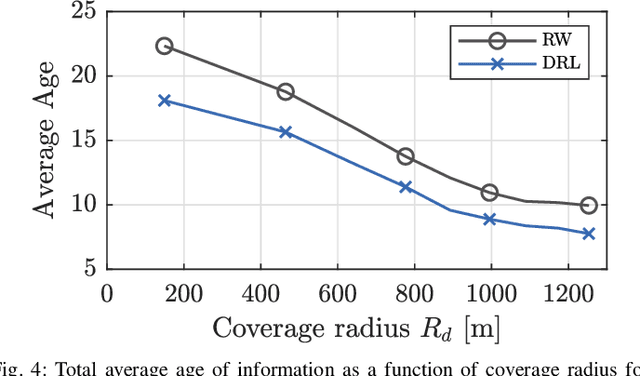
Many emerging Internet of Things (IoT) applications rely on information collected by sensor nodes where the freshness of information is an important criterion. \textit{Age of Information} (AoI) is a metric that quantifies information timeliness, i.e., the freshness of the received information or status update. This work considers a setup of deployed sensors in an IoT network, where multiple unmanned aerial vehicles (UAVs) serve as mobile relay nodes between the sensors and the base station. We formulate an optimization problem to jointly plan the UAVs' trajectory, while minimizing the AoI of the received messages. This ensures that the received information at the base station is as fresh as possible. The complex optimization problem is efficiently solved using a deep reinforcement learning (DRL) algorithm. In particular, we propose a deep Q-network, which works as a function approximation to estimate the state-action value function. The proposed scheme is quick to converge and results in a lower AoI than the random walk scheme. Our proposed algorithm reduces the average age by approximately $25\%$ and requires down to $50\%$ less energy when compared to the baseline scheme.