 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResilient UAV Trajectory Planning via Few-Shot Meta-Offline Reinforcement Learning
Feb 03, 2025

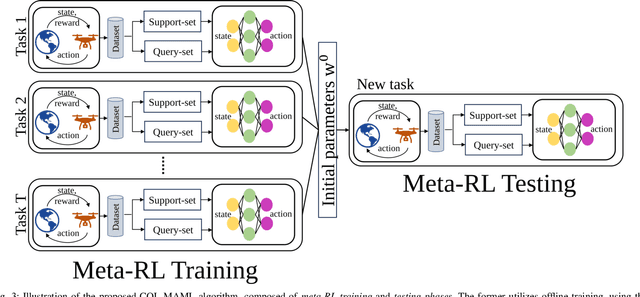

Reinforcement learning (RL) has been a promising essence in future 5G-beyond and 6G systems. Its main advantage lies in its robust model-free decision-making in complex and large-dimension wireless environments. However, most existing RL frameworks rely on online interaction with the environment, which might not be feasible due to safety and cost concerns. Another problem with online RL is the lack of scalability of the designed algorithm with dynamic or new environments. This work proposes a novel, resilient, few-shot meta-offline RL algorithm combining offline RL using conservative Q-learning (CQL) and meta-learning using model-agnostic meta-learning (MAML). The proposed algorithm can train RL models using static offline datasets without any online interaction with the environments. In addition, with the aid of MAML, the proposed model can be scaled up to new unseen environments. We showcase the proposed algorithm for optimizing an unmanned aerial vehicle (UAV) 's trajectory and scheduling policy to minimize the age-of-information (AoI) and transmission power of limited-power devices. Numerical results show that the proposed few-shot meta-offline RL algorithm converges faster than baseline schemes, such as deep Q-networks and CQL. In addition, it is the only algorithm that can achieve optimal joint AoI and transmission power using an offline dataset with few shots of data points and is resilient to network failures due to unprecedented environmental changes.
Age and Power Minimization via Meta-Deep Reinforcement Learning in UAV Networks
Jan 24, 2025



Age-of-information (AoI) and transmission power are crucial performance metrics in low energy wireless networks, where information freshness is of paramount importance. This study examines a power-limited internet of things (IoT) network supported by a flying unmanned aerial vehicle(UAV) that collects data. Our aim is to optimize the UAV flight trajectory and scheduling policy to minimize a varying AoI and transmission power combination. To tackle this variation, this paper proposes a meta-deep reinforcement learning (RL) approach that integrates deep Q-networks (DQNs) with model-agnostic meta-learning (MAML). DQNs determine optimal UAV decisions, while MAML enables scalability across varying objective functions. Numerical results indicate that the proposed algorithm converges faster and adapts to new objectives more effectively than traditional deep RL methods, achieving minimal AoI and transmission power overall.
MetaGraphLoc: A Graph-based Meta-learning Scheme for Indoor Localization via Sensor Fusion
Nov 26, 2024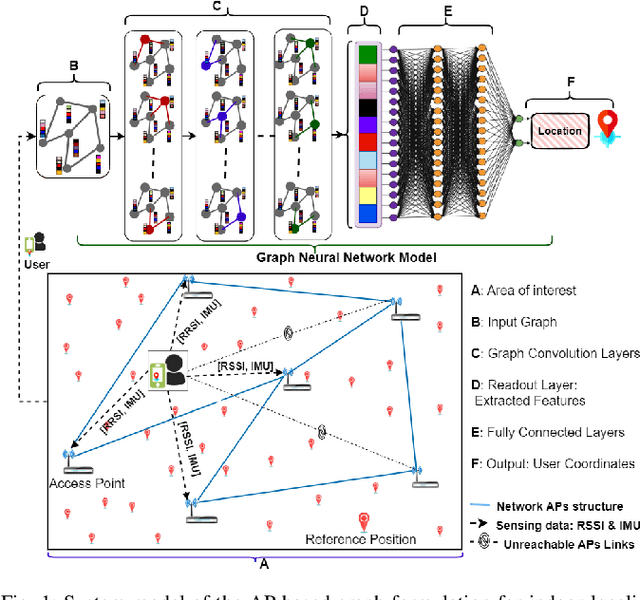
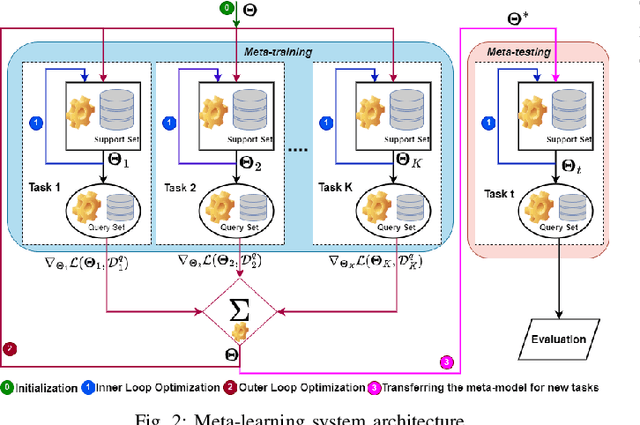
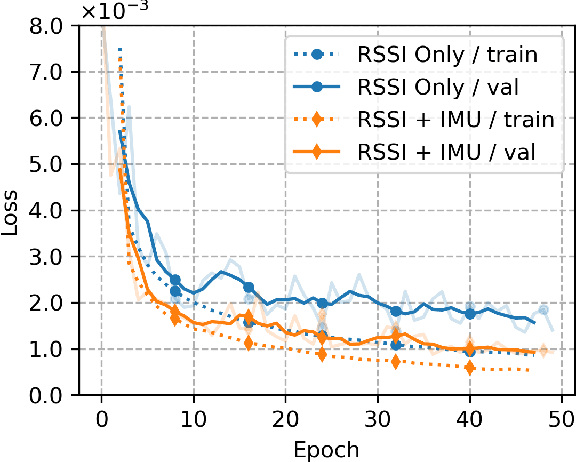
Accurate indoor localization remains challenging due to variations in wireless signal environments and limited data availability. This paper introduces MetaGraphLoc, a novel system leveraging sensor fusion, graph neural networks (GNNs), and meta-learning to overcome these limitations. MetaGraphLoc integrates received signal strength indicator measurements with inertial measurement unit data to enhance localization accuracy. Our proposed GNN architecture, featuring dynamic edge construction (DEC), captures the spatial relationships between access points and underlying data patterns. MetaGraphLoc employs a meta-learning framework to adapt the GNN model to new environments with minimal data collection, significantly reducing calibration efforts. Extensive evaluations demonstrate the effectiveness of MetaGraphLoc. Data fusion reduces localization error by 15.92%, underscoring its importance. The GNN with DEC outperforms traditional deep neural networks by up to 30.89%, considering accuracy. Furthermore, the meta-learning approach enables efficient adaptation to new environments, minimizing data collection requirements. These advancements position MetaGraphLoc as a promising solution for indoor localization, paving the way for improved navigation and location-based services in the ever-evolving Internet of Things networks.
Offline and Distributional Reinforcement Learning for Radio Resource Management
Sep 25, 2024



Reinforcement learning (RL) has proved to have a promising role in future intelligent wireless networks. Online RL has been adopted for radio resource management (RRM), taking over traditional schemes. However, due to its reliance on online interaction with the environment, its role becomes limited in practical, real-world problems where online interaction is not feasible. In addition, traditional RL stands short in front of the uncertainties and risks in real-world stochastic environments. In this manner, we propose an offline and distributional RL scheme for the RRM problem, enabling offline training using a static dataset without any interaction with the environment and considering the sources of uncertainties using the distributions of the return. Simulation results demonstrate that the proposed scheme outperforms conventional resource management models. In addition, it is the only scheme that surpasses online RL and achieves a $16 \%$ gain over online RL.
Conservative and Risk-Aware Offline Multi-Agent Reinforcement Learning for Digital Twins
Feb 13, 2024



Digital twin (DT) platforms are increasingly regarded as a promising technology for controlling, optimizing, and monitoring complex engineering systems such as next-generation wireless networks. An important challenge in adopting DT solutions is their reliance on data collected offline, lacking direct access to the physical environment. This limitation is particularly severe in multi-agent systems, for which conventional multi-agent reinforcement (MARL) requires online interactions with the environment. A direct application of online MARL schemes to an offline setting would generally fail due to the epistemic uncertainty entailed by the limited availability of data. In this work, we propose an offline MARL scheme for DT-based wireless networks that integrates distributional RL and conservative Q-learning to address the environment's inherent aleatoric uncertainty and the epistemic uncertainty arising from limited data. To further exploit the offline data, we adapt the proposed scheme to the centralized training decentralized execution framework, allowing joint training of the agents' policies. The proposed MARL scheme, referred to as multi-agent conservative quantile regression (MA-CQR) addresses general risk-sensitive design criteria and is applied to the trajectory planning problem in drone networks, showcasing its advantages.
Traffic Learning and Proactive UAV Trajectory Planning for Data Uplink in Markovian IoT Models
Jan 24, 2024



The age of information (AoI) is used to measure the freshness of the data. In IoT networks, the traditional resource management schemes rely on a message exchange between the devices and the base station (BS) before communication which causes high AoI, high energy consumption, and low reliability. Unmanned aerial vehicles (UAVs) as flying BSs have many advantages in minimizing the AoI, energy-saving, and throughput improvement. In this paper, we present a novel learning-based framework that estimates the traffic arrival of IoT devices based on Markovian events. The learning proceeds to optimize the trajectory of multiple UAVs and their scheduling policy. First, the BS predicts the future traffic of the devices. We compare two traffic predictors: the forward algorithm (FA) and the long short-term memory (LSTM). Afterward, we propose a deep reinforcement learning (DRL) approach to optimize the optimal policy of each UAV. Finally, we manipulate the optimum reward function for the proposed DRL approach. Simulation results show that the proposed algorithm outperforms the random-walk (RW) baseline model regarding the AoI, scheduling accuracy, and transmission power.
Age Minimization in Massive IoT via UAV Swarm: A Multi-agent Reinforcement Learning Approach
Sep 26, 2023



In many massive IoT communication scenarios, the IoT devices require coverage from dynamic units that can move close to the IoT devices and reduce the uplink energy consumption. A robust solution is to deploy a large number of UAVs (UAV swarm) to provide coverage and a better line of sight (LoS) for the IoT network. However, the study of these massive IoT scenarios with a massive number of serving units leads to high dimensional problems with high complexity. In this paper, we apply multi-agent deep reinforcement learning to address the high-dimensional problem that results from deploying a swarm of UAVs to collect fresh information from IoT devices. The target is to minimize the overall age of information in the IoT network. The results reveal that both cooperative and partially cooperative multi-agent deep reinforcement learning approaches are able to outperform the high-complexity centralized deep reinforcement learning approach, which stands helpless in large-scale networks.
LoRaWAN-enabled Smart Campus: The Dataset and a People Counter Use Case
Apr 26, 2023IoT has a significant role in the smart campus. This paper presents a detailed description of the Smart Campus dataset based on LoRaWAN. LoRaWAN is an emerging technology that enables serving hundreds of IoT devices. First, we describe the LoRa network that connects the devices to the server. Afterward, we analyze the missing transmissions and propose a k-nearest neighbor solution to handle the missing values. Then, we predict future readings using a long short-term memory (LSTM). Finally, as one example application, we build a deep neural network to predict the number of people inside a room based on the selected sensor's readings. Our results show that our model achieves an accuracy of $95 \: \%$ in predicting the number of people. Moreover, the dataset is openly available and described in detail, which is opportunity for exploration of other features and applications.
Multi-UAV Path Learning for Age and Power Optimization in IoT with UAV Battery Recharge
Jan 09, 2023



In many emerging Internet of Things (IoT) applications, the freshness of the is an important design criterion. Age of Information (AoI) quantifies the freshness of the received information or status update. This work considers a setup of deployed IoT devices in an IoT network; multiple unmanned aerial vehicles (UAVs) serve as mobile relay nodes between the sensors and the base station. We formulate an optimization problem to jointly plan the UAVs' trajectory, while minimizing the AoI of the received messages and the devices' energy consumption. The solution accounts for the UAVs' battery lifetime and flight time to recharging depots to ensure the UAVs' green operation. The complex optimization problem is efficiently solved using a deep reinforcement learning algorithm. In particular, we propose a deep Q-network, which works as a function approximation to estimate the state-action value function. The proposed scheme is quick to converge and results in a lower ergodic age and ergodic energy consumption when compared with benchmark algorithms such as greedy algorithm (GA), nearest neighbour (NN), and random-walk (RW).
A Learning-Based Trajectory Planning of Multiple UAVs for AoI Minimization in IoT Networks
Sep 13, 2022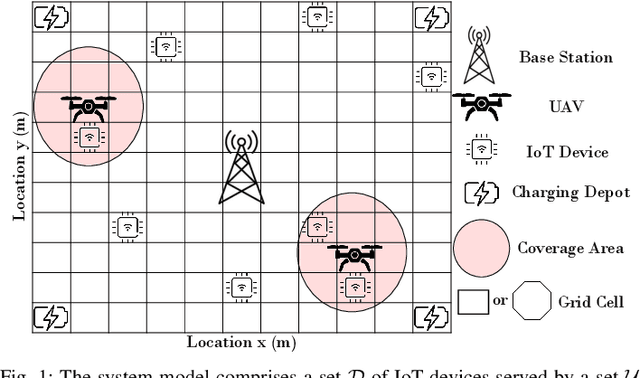
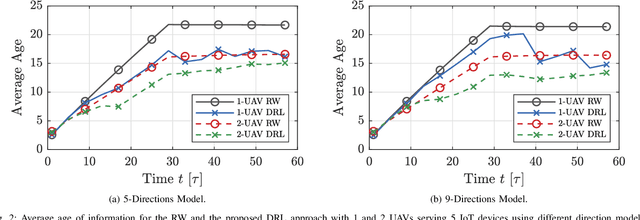
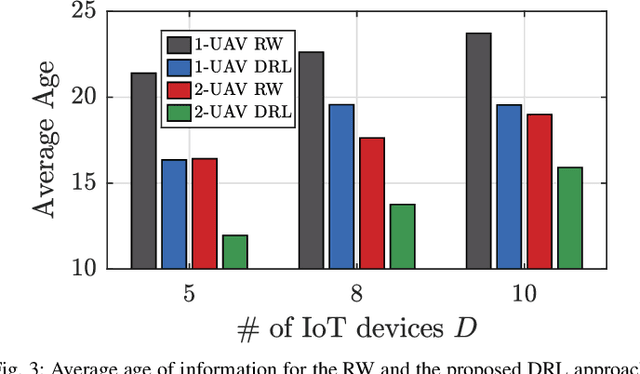
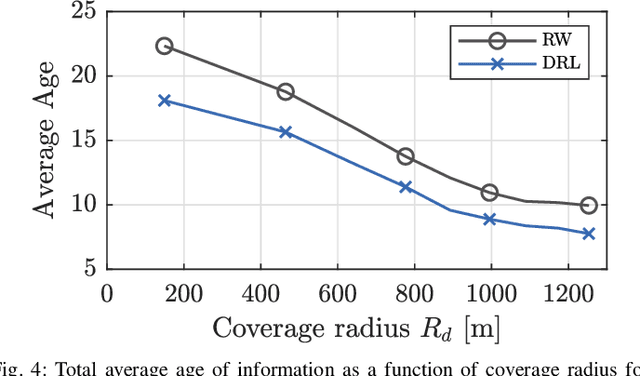
Many emerging Internet of Things (IoT) applications rely on information collected by sensor nodes where the freshness of information is an important criterion. \textit{Age of Information} (AoI) is a metric that quantifies information timeliness, i.e., the freshness of the received information or status update. This work considers a setup of deployed sensors in an IoT network, where multiple unmanned aerial vehicles (UAVs) serve as mobile relay nodes between the sensors and the base station. We formulate an optimization problem to jointly plan the UAVs' trajectory, while minimizing the AoI of the received messages. This ensures that the received information at the base station is as fresh as possible. The complex optimization problem is efficiently solved using a deep reinforcement learning (DRL) algorithm. In particular, we propose a deep Q-network, which works as a function approximation to estimate the state-action value function. The proposed scheme is quick to converge and results in a lower AoI than the random walk scheme. Our proposed algorithm reduces the average age by approximately $25\%$ and requires down to $50\%$ less energy when compared to the baseline scheme.