 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Fidelity Hybrid Reinforcement Learning via Information Gain Maximization
Sep 18, 2025Optimizing a reinforcement learning (RL) policy typically requires extensive interactions with a high-fidelity simulator of the environment, which are often costly or impractical. Offline RL addresses this problem by allowing training from pre-collected data, but its effectiveness is strongly constrained by the size and quality of the dataset. Hybrid offline-online RL leverages both offline data and interactions with a single simulator of the environment. In many real-world scenarios, however, multiple simulators with varying levels of fidelity and computational cost are available. In this work, we study multi-fidelity hybrid RL for policy optimization under a fixed cost budget. We introduce multi-fidelity hybrid RL via information gain maximization (MF-HRL-IGM), a hybrid offline-online RL algorithm that implements fidelity selection based on information gain maximization through a bootstrapping approach. Theoretical analysis establishes the no-regret property of MF-HRL-IGM, while empirical evaluations demonstrate its superior performance compared to existing benchmarks.
Data-Efficient Prediction-Powered Calibration via Cross-Validation
Jul 27, 2025Calibration data are necessary to formally quantify the uncertainty of the decisions produced by an existing artificial intelligence (AI) model. To overcome the common issue of scarce calibration data, a promising approach is to employ synthetic labels produced by a (generally different) predictive model. However, fine-tuning the label-generating predictor on the inference task of interest, as well as estimating the residual bias of the synthetic labels, demand additional data, potentially exacerbating the calibration data scarcity problem. This paper introduces a novel approach that efficiently utilizes limited calibration data to simultaneously fine-tune a predictor and estimate the bias of the synthetic labels. The proposed method yields prediction sets with rigorous coverage guarantees for AI-generated decisions. Experimental results on an indoor localization problem validate the effectiveness and performance gains of our solution.
How to Bridge the Sim-to-Real Gap in Digital Twin-Aided Telecommunication Networks
Jul 09, 2025Training effective artificial intelligence models for telecommunications is challenging due to the scarcity of deployment-specific data. Real data collection is expensive, and available datasets often fail to capture the unique operational conditions and contextual variability of the network environment. Digital twinning provides a potential solution to this problem, as simulators tailored to the current network deployment can generate site-specific data to augment the available training datasets. However, there is a need to develop solutions to bridge the inherent simulation-to-reality (sim-to-real) gap between synthetic and real-world data. This paper reviews recent advances on two complementary strategies: 1) the calibration of digital twins (DTs) through real-world measurements, and 2) the use of sim-to-real gap-aware training strategies to robustly handle residual discrepancies between digital twin-generated and real data. For the latter, we evaluate two conceptually distinct methods that model the sim-to-real gap either at the level of the environment via Bayesian learning or at the level of the training loss via prediction-powered inference.
Context-Aware Doubly-Robust Semi-Supervised Learning
Feb 21, 2025The widespread adoption of artificial intelligence (AI) in next-generation communication systems is challenged by the heterogeneity of traffic and network conditions, which call for the use of highly contextual, site-specific, data. A promising solution is to rely not only on real-world data, but also on synthetic pseudo-data generated by a network digital twin (NDT). However, the effectiveness of this approach hinges on the accuracy of the NDT, which can vary widely across different contexts. To address this problem, this paper introduces context-aware doubly-robust (CDR) learning, a novel semi-supervised scheme that adapts its reliance on the pseudo-data to the different levels of fidelity of the NDT across contexts. CDR is evaluated on the task of downlink beamforming, showing superior performance compared to previous state-of-the-art semi-supervised approaches.
Semi-Supervised Learning via Cross-Prediction-Powered Inference for Wireless Systems
May 24, 2024In many wireless application scenarios, acquiring labeled data can be prohibitively costly, requiring complex optimization processes or measurement campaigns. Semi-supervised learning leverages unlabeled samples to augment the available dataset by assigning synthetic labels obtained via machine learning (ML)-based predictions. However, treating the synthetic labels as true labels may yield worse-performing models as compared to models trained using only labeled data. Inspired by the recently developed prediction-powered inference (PPI) framework, this work investigates how to leverage the synthetic labels produced by an ML model, while accounting for the inherent bias with respect to true labels. To this end, we first review PPI and its recent extensions, namely tuned PPI and cross-prediction-powered inference (CPPI). Then, we introduce a novel variant of PPI, referred to as tuned CPPI, that provides CPPI with an additional degree of freedom in adapting to the quality of the ML-based labels. Finally, we showcase two applications of PPI-based techniques in wireless systems, namely beam alignment based on channel knowledge maps in millimeter-wave systems and received signal strength information-based indoor localization. Simulation results show the advantages of PPI-based techniques over conventional approaches that rely solely on labeled data or that apply standard pseudo-labeling strategies from semi-supervised learning. Furthermore, the proposed tuned CPPI method is observed to guarantee the best performance among all benchmark schemes, especially in the regime of limited labeled data.
Conservative and Risk-Aware Offline Multi-Agent Reinforcement Learning for Digital Twins
Feb 13, 2024



Digital twin (DT) platforms are increasingly regarded as a promising technology for controlling, optimizing, and monitoring complex engineering systems such as next-generation wireless networks. An important challenge in adopting DT solutions is their reliance on data collected offline, lacking direct access to the physical environment. This limitation is particularly severe in multi-agent systems, for which conventional multi-agent reinforcement (MARL) requires online interactions with the environment. A direct application of online MARL schemes to an offline setting would generally fail due to the epistemic uncertainty entailed by the limited availability of data. In this work, we propose an offline MARL scheme for DT-based wireless networks that integrates distributional RL and conservative Q-learning to address the environment's inherent aleatoric uncertainty and the epistemic uncertainty arising from limited data. To further exploit the offline data, we adapt the proposed scheme to the centralized training decentralized execution framework, allowing joint training of the agents' policies. The proposed MARL scheme, referred to as multi-agent conservative quantile regression (MA-CQR) addresses general risk-sensitive design criteria and is applied to the trajectory planning problem in drone networks, showcasing its advantages.
Over-The-Air Federated Learning Over Scalable Cell-free Massive MIMO
Dec 13, 2022Cell-free massive MIMO is emerging as a promising technology for future wireless communication systems, which is expected to offer uniform coverage and high spectral efficiency compared to classical cellular systems. We study in this paper how cell-free massive MIMO can support federated edge learning. Taking advantage of the additive nature of the wireless multiple access channel, over-the-air computation is exploited, where the clients send their local updates simultaneously over the same communication resource. This approach, known as over-the-air federated learning (OTA-FL), is proven to alleviate the communication overhead of federated learning over wireless networks. Considering channel correlation and only imperfect channel state information available at the central server, we propose a practical implementation of OTA-FL over cell-free massive MIMO. The convergence of the proposed implementation is studied analytically and experimentally, confirming the benefits of cell-free massive MIMO for OTA-FL.
CSI-based Indoor Localization via Attention-Augmented Residual Convolutional Neural Network
May 11, 2022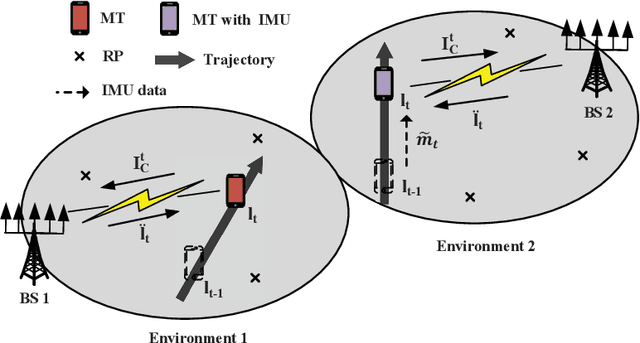

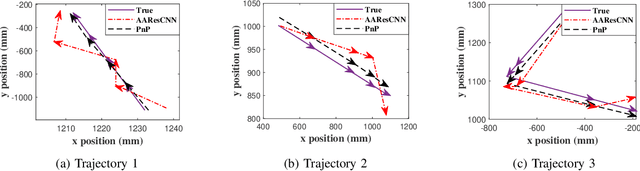

Deep learning has been widely adopted for channel state information (CSI)-fingerprinting indoor localization systems. These systems usually consist of two main parts, i.e., a positioning network that learns the mapping from high-dimensional CSI to physical locations and a tracking system that utilizes historical CSI to reduce the positioning error. This paper presents a new localization system with high accuracy and generality. On the one hand, the receptive field of the existing convolutional neural network (CNN)-based positioning networks is limited, restricting their performance as useful information in CSI is not explored thoroughly. As a solution, we propose a novel attention-augmented Residual CNN to utilize the local information and global context in CSI exhaustively. On the other hand, considering the generality of a tracking system, we decouple the tracking system from the CSI environments so that one tracking system for all environments becomes possible. Specifically, we remodel the tracking problem as a denoising task and solve it with deep trajectory prior. Furthermore, we investigate how the precision difference of inertial measurement units will adversely affect the tracking performance and adopt plug-and-play to solve the precision difference problem. Experiments show the superiority of our methods over existing approaches in performance and generality improvement.
Over-The-Air Federated Learning under Byzantine Attacks
May 05, 2022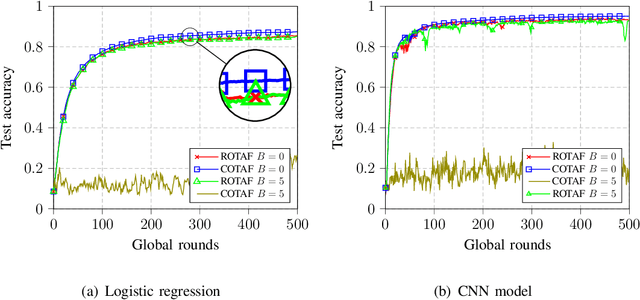
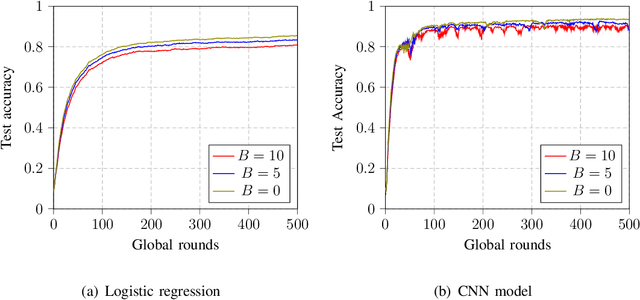
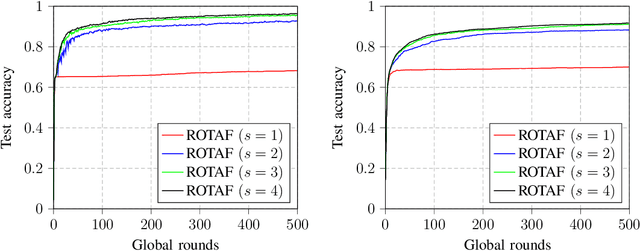
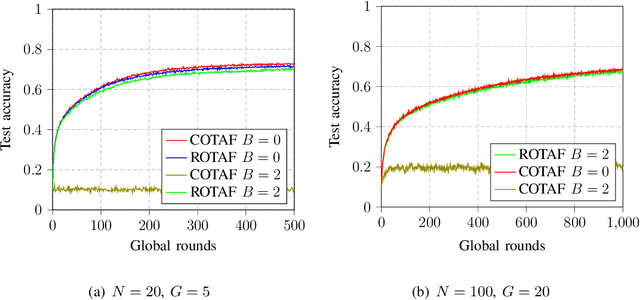
Federated learning (FL) is a promising solution to enable many AI applications, where sensitive datasets from distributed clients are needed for collaboratively training a global model. FL allows the clients to participate in the training phase, governed by a central server, without sharing their local data. One of the main challenges of FL is the communication overhead, where the model updates of the participating clients are sent to the central server at each global training round. Over-the-air computation (AirComp) has been recently proposed to alleviate the communication bottleneck where the model updates are sent simultaneously over the multiple-access channel. However, simple averaging of the model updates via AirComp makes the learning process vulnerable to random or intended modifications of the local model updates of some Byzantine clients. In this paper, we propose a transmission and aggregation framework to reduce the effect of such attacks while preserving the benefits of AirComp for FL. For the proposed robust approach, the central server divides the participating clients randomly into groups and allocates a transmission time slot for each group. The updates of the different groups are then aggregated using a robust aggregation technique. We extend our approach to handle the case of non-i.i.d. local data, where a resampling step is added before robust aggregation. We analyze the convergence of the proposed approach for both cases of i.i.d. and non-i.i.d. data and demonstrate that the proposed algorithm converges at a linear rate to a neighborhood of the optimal solution. Experiments on real datasets are provided to confirm the robustness of the proposed approach.
Robust Federated Learning via Over-The-Air Computation
Nov 11, 2021

This paper investigates the robustness of over-the-air federated learning to Byzantine attacks. The simple averaging of the model updates via over-the-air computation makes the learning task vulnerable to random or intended modifications of the local model updates of some malicious clients. We propose a robust transmission and aggregation framework to such attacks while preserving the benefits of over-the-air computation for federated learning. For the proposed robust federated learning, the participating clients are randomly divided into groups and a transmission time slot is allocated to each group. The parameter server aggregates the results of the different groups using a robust aggregation technique and conveys the result to the clients for another training round. We also analyze the convergence of the proposed algorithm. Numerical simulations confirm the robustness of the proposed approach to Byzantine attacks.