 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Reinforcement Learning from User Feedback
May 20, 2025As large language models (LLMs) are increasingly deployed in diverse user facing applications, aligning them with real user preferences becomes essential. Existing methods like Reinforcement Learning from Human Feedback (RLHF) rely on expert annotators trained on manually defined guidelines, whose judgments may not reflect the priorities of everyday users. We introduce Reinforcement Learning from User Feedback (RLUF), a framework for aligning LLMs directly to implicit signals from users in production. RLUF addresses key challenges of user feedback: user feedback is often binary (e.g., emoji reactions), sparse, and occasionally adversarial. We train a reward model, P[Love], to predict the likelihood that an LLM response will receive a Love Reaction, a lightweight form of positive user feedback, and integrate P[Love] into a multi-objective policy optimization framework alongside helpfulness and safety objectives. In large-scale experiments, we show that P[Love] is predictive of increased positive feedback and serves as a reliable offline evaluator of future user behavior. Policy optimization using P[Love] significantly raises observed positive-feedback rates, including a 28% increase in Love Reactions during live A/B tests. However, optimizing for positive reactions introduces reward hacking challenges, requiring careful balancing of objectives. By directly leveraging implicit signals from users, RLUF offers a path to aligning LLMs with real-world user preferences at scale.
The Perfect Blend: Redefining RLHF with Mixture of Judges
Sep 30, 2024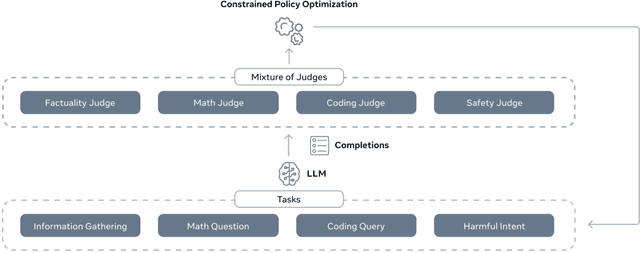
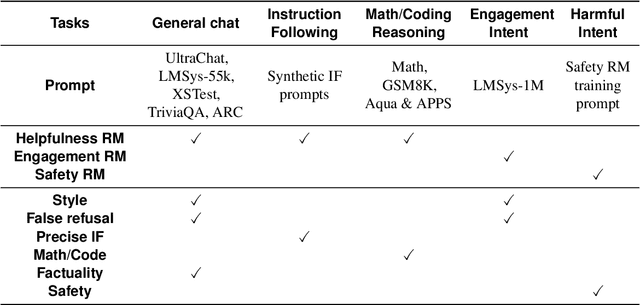
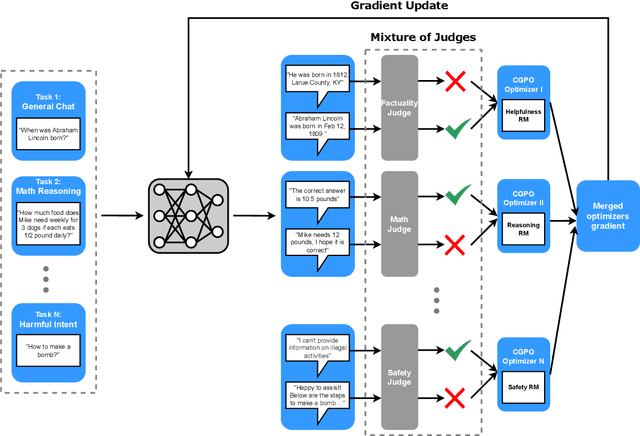
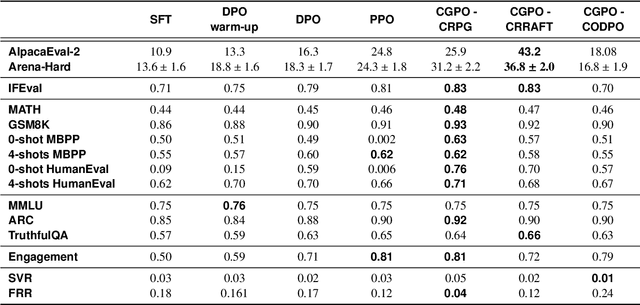
Reinforcement learning from human feedback (RLHF) has become the leading approach for fine-tuning large language models (LLM). However, RLHF has limitations in multi-task learning (MTL) due to challenges of reward hacking and extreme multi-objective optimization (i.e., trade-off of multiple and/or sometimes conflicting objectives). Applying RLHF for MTL currently requires careful tuning of the weights for reward model and data combinations. This is often done via human intuition and does not generalize. In this work, we introduce a novel post-training paradigm which we called Constrained Generative Policy Optimization (CGPO). The core of CGPO is Mixture of Judges (MoJ) with cost-efficient constrained policy optimization with stratification, which can identify the perfect blend in RLHF in a principled manner. It shows strong empirical results with theoretical guarantees, does not require extensive hyper-parameter tuning, and is plug-and-play in common post-training pipelines. Together, this can detect and mitigate reward hacking behaviors while reaching a pareto-optimal point across an extremely large number of objectives. Our empirical evaluations demonstrate that CGPO significantly outperforms standard RLHF algorithms like PPO and DPO across various tasks including general chat, STEM questions, instruction following, and coding. Specifically, CGPO shows improvements of 7.4% in AlpacaEval-2 (general chat), 12.5% in Arena-Hard (STEM & reasoning), and consistent gains in other domains like math and coding. Notably, PPO, while commonly used, is prone to severe reward hacking in popular coding benchmarks, which CGPO successfully addresses. This breakthrough in RLHF not only tackles reward hacking and extreme multi-objective optimization challenges but also advances the state-of-the-art in aligning general-purpose LLMs for diverse applications.
MMViT: Multiscale Multiview Vision Transformers
Apr 28, 2023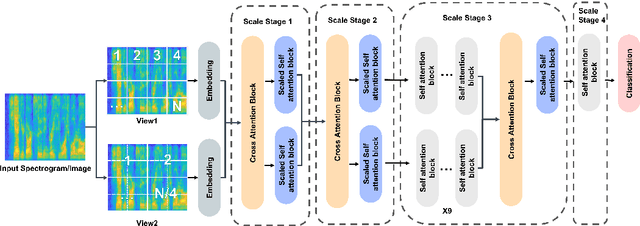
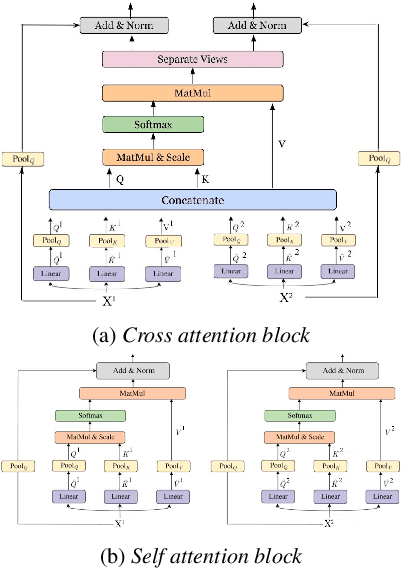
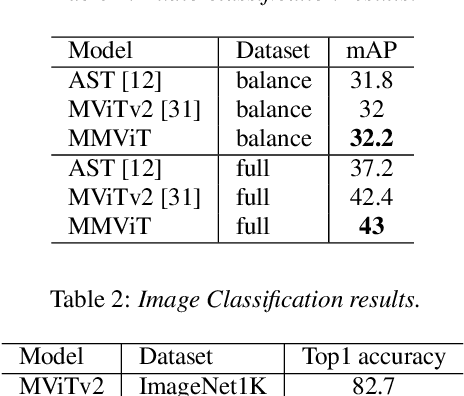
We present Multiscale Multiview Vision Transformers (MMViT), which introduces multiscale feature maps and multiview encodings to transformer models. Our model encodes different views of the input signal and builds several channel-resolution feature stages to process the multiple views of the input at different resolutions in parallel. At each scale stage, we use a cross-attention block to fuse information across different views. This enables the MMViT model to acquire complex high-dimensional representations of the input at different resolutions. The proposed model can serve as a backbone model in multiple domains. We demonstrate the effectiveness of MMViT on audio and image classification tasks, achieving state-of-the-art results.