 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Reinforcement Learning from User Feedback
May 20, 2025As large language models (LLMs) are increasingly deployed in diverse user facing applications, aligning them with real user preferences becomes essential. Existing methods like Reinforcement Learning from Human Feedback (RLHF) rely on expert annotators trained on manually defined guidelines, whose judgments may not reflect the priorities of everyday users. We introduce Reinforcement Learning from User Feedback (RLUF), a framework for aligning LLMs directly to implicit signals from users in production. RLUF addresses key challenges of user feedback: user feedback is often binary (e.g., emoji reactions), sparse, and occasionally adversarial. We train a reward model, P[Love], to predict the likelihood that an LLM response will receive a Love Reaction, a lightweight form of positive user feedback, and integrate P[Love] into a multi-objective policy optimization framework alongside helpfulness and safety objectives. In large-scale experiments, we show that P[Love] is predictive of increased positive feedback and serves as a reliable offline evaluator of future user behavior. Policy optimization using P[Love] significantly raises observed positive-feedback rates, including a 28% increase in Love Reactions during live A/B tests. However, optimizing for positive reactions introduces reward hacking challenges, requiring careful balancing of objectives. By directly leveraging implicit signals from users, RLUF offers a path to aligning LLMs with real-world user preferences at scale.
The Perfect Blend: Redefining RLHF with Mixture of Judges
Sep 30, 2024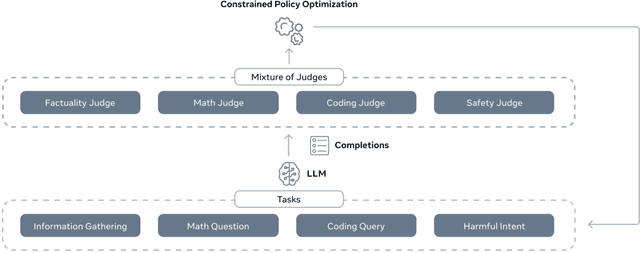
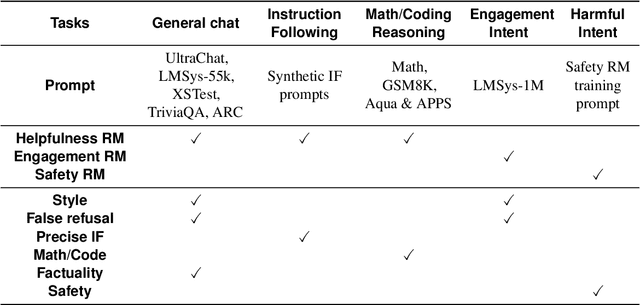
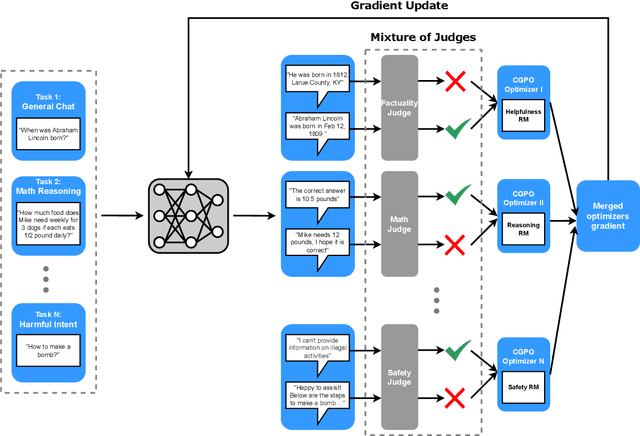
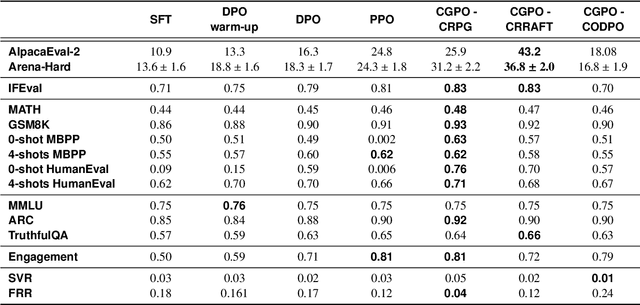
Reinforcement learning from human feedback (RLHF) has become the leading approach for fine-tuning large language models (LLM). However, RLHF has limitations in multi-task learning (MTL) due to challenges of reward hacking and extreme multi-objective optimization (i.e., trade-off of multiple and/or sometimes conflicting objectives). Applying RLHF for MTL currently requires careful tuning of the weights for reward model and data combinations. This is often done via human intuition and does not generalize. In this work, we introduce a novel post-training paradigm which we called Constrained Generative Policy Optimization (CGPO). The core of CGPO is Mixture of Judges (MoJ) with cost-efficient constrained policy optimization with stratification, which can identify the perfect blend in RLHF in a principled manner. It shows strong empirical results with theoretical guarantees, does not require extensive hyper-parameter tuning, and is plug-and-play in common post-training pipelines. Together, this can detect and mitigate reward hacking behaviors while reaching a pareto-optimal point across an extremely large number of objectives. Our empirical evaluations demonstrate that CGPO significantly outperforms standard RLHF algorithms like PPO and DPO across various tasks including general chat, STEM questions, instruction following, and coding. Specifically, CGPO shows improvements of 7.4% in AlpacaEval-2 (general chat), 12.5% in Arena-Hard (STEM & reasoning), and consistent gains in other domains like math and coding. Notably, PPO, while commonly used, is prone to severe reward hacking in popular coding benchmarks, which CGPO successfully addresses. This breakthrough in RLHF not only tackles reward hacking and extreme multi-objective optimization challenges but also advances the state-of-the-art in aligning general-purpose LLMs for diverse applications.
Adversarial Attacks on Gaussian Process Bandits
Oct 16, 2021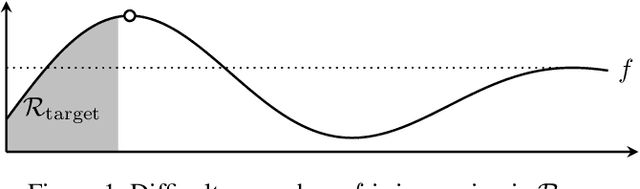
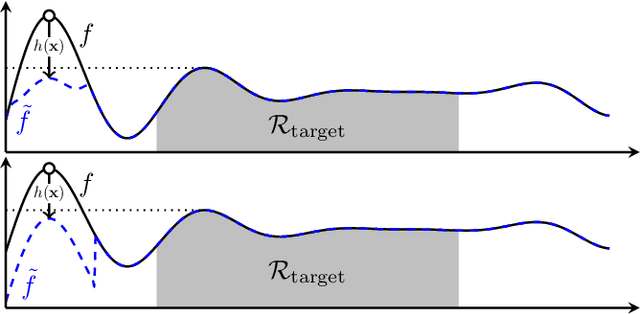
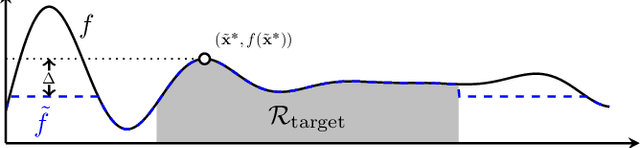
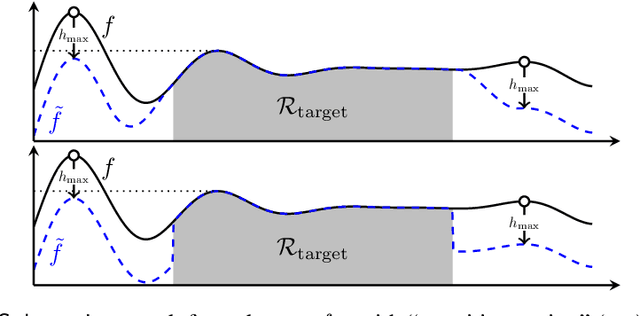
Gaussian processes (GP) are a widely-adopted tool used to sequentially optimize black-box functions, where evaluations are costly and potentially noisy. Recent works on GP bandits have proposed to move beyond random noise and devise algorithms robust to adversarial attacks. In this paper, we study this problem from the attacker's perspective, proposing various adversarial attack methods with differing assumptions on the attacker's strength and prior information. Our goal is to understand adversarial attacks on GP bandits from both a theoretical and practical perspective. We focus primarily on targeted attacks on the popular GP-UCB algorithm and a related elimination-based algorithm, based on adversarially perturbing the function $f$ to produce another function $\tilde{f}$ whose optima are in some region $\mathcal{R}_{\rm target}$. Based on our theoretical analysis, we devise both white-box attacks (known $f$) and black-box attacks (unknown $f$), with the former including a Subtraction attack and Clipping attack, and the latter including an Aggressive subtraction attack. We demonstrate that adversarial attacks on GP bandits can succeed in forcing the algorithm towards $\mathcal{R}_{\rm target}$ even with a low attack budget, and we compare our attacks' performance and efficiency on several real and synthetic functions.
High-Dimensional Bayesian Optimization via Tree-Structured Additive Models
Dec 24, 2020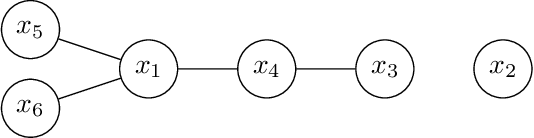
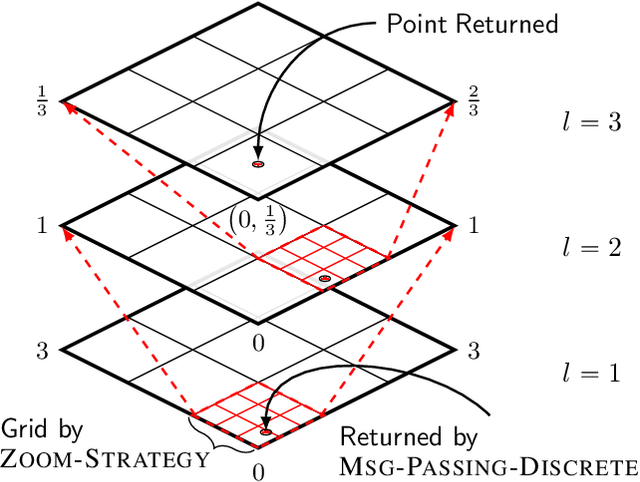
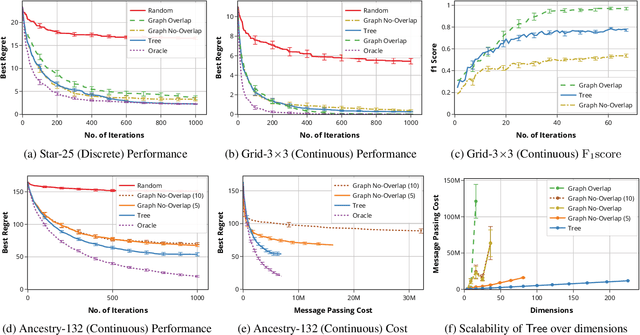
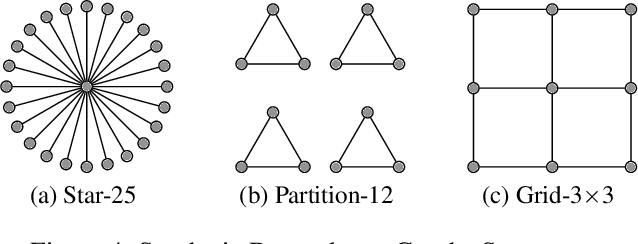
Bayesian Optimization (BO) has shown significant success in tackling expensive low-dimensional black-box optimization problems. Many optimization problems of interest are high-dimensional, and scaling BO to such settings remains an important challenge. In this paper, we consider generalized additive models in which low-dimensional functions with overlapping subsets of variables are composed to model a high-dimensional target function. Our goal is to lower the computational resources required and facilitate faster model learning by reducing the model complexity while retaining the sample-efficiency of existing methods. Specifically, we constrain the underlying dependency graphs to tree structures in order to facilitate both the structure learning and optimization of the acquisition function. For the former, we propose a hybrid graph learning algorithm based on Gibbs sampling and mutation. In addition, we propose a novel zooming-based algorithm that permits generalized additive models to be employed more efficiently in the case of continuous domains. We demonstrate and discuss the efficacy of our approach via a range of experiments on synthetic functions and real-world datasets.