 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMake Tracking Easy: Neural Motion Retargeting for Humanoid Whole-body Control
Mar 23, 2026Humanoid robots require diverse motor skills to integrate into complex environments, but bridging the kinematic and dynamic embodiment gap from human data remains a major bottleneck. We demonstrate through Hessian analysis that traditional optimization-based retargeting is inherently non-convex and prone to local optima, leading to physical artifacts like joint jumps and self-penetration. To address this, we reformulate the targeting problem as learning data distribution rather than optimizing optimal solutions, where we propose NMR, a Neural Motion Retargeting framework that transforms static geometric mapping into a dynamics-aware learned process. We first propose Clustered-Expert Physics Refinement (CEPR), a hierarchical data pipeline that leverages VAE-based motion clustering to group heterogeneous movements into latent motifs. This strategy significantly reduces the computational overhead of massively parallel reinforcement learning experts, which project and repair noisy human demonstrations onto the robot's feasible motion manifold. The resulting high-fidelity data supervises a non-autoregressive CNN-Transformer architecture that reasons over global temporal context to suppress reconstruction noise and bypass geometric traps. Experiments on the Unitree G1 humanoid across diverse dynamic tasks (e.g., martial arts, dancing) show that NMR eliminates joint jumps and significantly reduces self-collisions compared to state-of-the-art baselines. Furthermore, NMR-generated references accelerate the convergence of downstream whole-body control policies, establishing a scalable path for bridging the human-robot embodiment gap.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
MiniMax-Speech: Intrinsic Zero-Shot Text-to-Speech with a Learnable Speaker Encoder
May 12, 2025We introduce MiniMax-Speech, an autoregressive Transformer-based Text-to-Speech (TTS) model that generates high-quality speech. A key innovation is our learnable speaker encoder, which extracts timbre features from a reference audio without requiring its transcription. This enables MiniMax-Speech to produce highly expressive speech with timbre consistent with the reference in a zero-shot manner, while also supporting one-shot voice cloning with exceptionally high similarity to the reference voice. In addition, the overall quality of the synthesized audio is enhanced through the proposed Flow-VAE. Our model supports 32 languages and demonstrates excellent performance across multiple objective and subjective evaluations metrics. Notably, it achieves state-of-the-art (SOTA) results on objective voice cloning metrics (Word Error Rate and Speaker Similarity) and has secured the top position on the public TTS Arena leaderboard. Another key strength of MiniMax-Speech, granted by the robust and disentangled representations from the speaker encoder, is its extensibility without modifying the base model, enabling various applications such as: arbitrary voice emotion control via LoRA; text to voice (T2V) by synthesizing timbre features directly from text description; and professional voice cloning (PVC) by fine-tuning timbre features with additional data. We encourage readers to visit https://minimax-ai.github.io/tts_tech_report for more examples.
MMViT: Multiscale Multiview Vision Transformers
Apr 28, 2023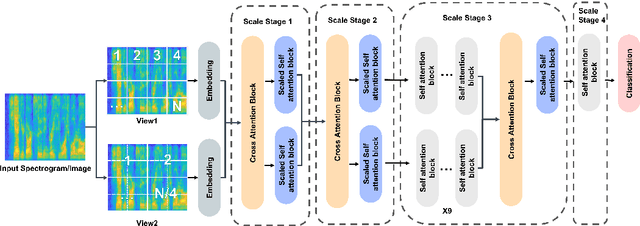
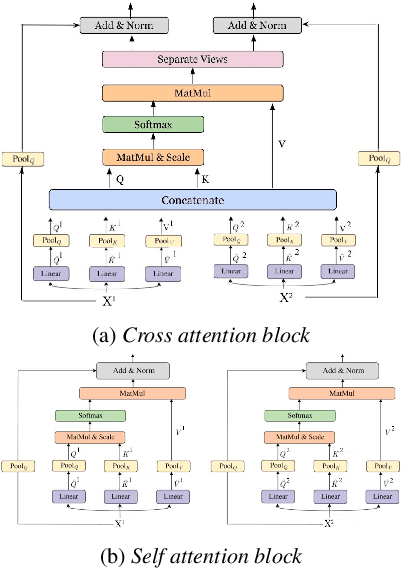
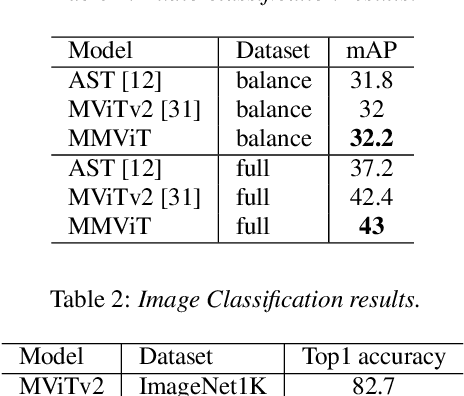
We present Multiscale Multiview Vision Transformers (MMViT), which introduces multiscale feature maps and multiview encodings to transformer models. Our model encodes different views of the input signal and builds several channel-resolution feature stages to process the multiple views of the input at different resolutions in parallel. At each scale stage, we use a cross-attention block to fuse information across different views. This enables the MMViT model to acquire complex high-dimensional representations of the input at different resolutions. The proposed model can serve as a backbone model in multiple domains. We demonstrate the effectiveness of MMViT on audio and image classification tasks, achieving state-of-the-art results.