 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniMax-Speech: Intrinsic Zero-Shot Text-to-Speech with a Learnable Speaker Encoder
May 12, 2025We introduce MiniMax-Speech, an autoregressive Transformer-based Text-to-Speech (TTS) model that generates high-quality speech. A key innovation is our learnable speaker encoder, which extracts timbre features from a reference audio without requiring its transcription. This enables MiniMax-Speech to produce highly expressive speech with timbre consistent with the reference in a zero-shot manner, while also supporting one-shot voice cloning with exceptionally high similarity to the reference voice. In addition, the overall quality of the synthesized audio is enhanced through the proposed Flow-VAE. Our model supports 32 languages and demonstrates excellent performance across multiple objective and subjective evaluations metrics. Notably, it achieves state-of-the-art (SOTA) results on objective voice cloning metrics (Word Error Rate and Speaker Similarity) and has secured the top position on the public TTS Arena leaderboard. Another key strength of MiniMax-Speech, granted by the robust and disentangled representations from the speaker encoder, is its extensibility without modifying the base model, enabling various applications such as: arbitrary voice emotion control via LoRA; text to voice (T2V) by synthesizing timbre features directly from text description; and professional voice cloning (PVC) by fine-tuning timbre features with additional data. We encourage readers to visit https://minimax-ai.github.io/tts_tech_report for more examples.
EfficientMFD: Towards More Efficient Multimodal Synchronous Fusion Detection
Mar 14, 2024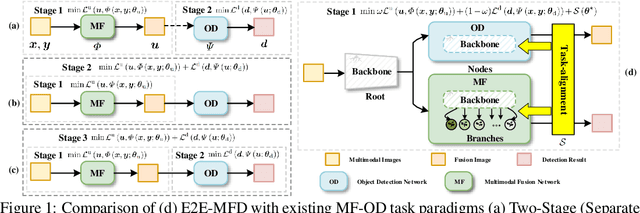
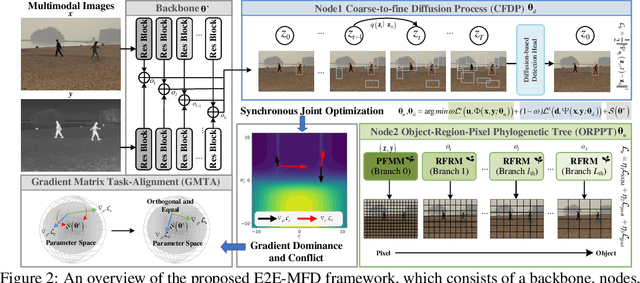
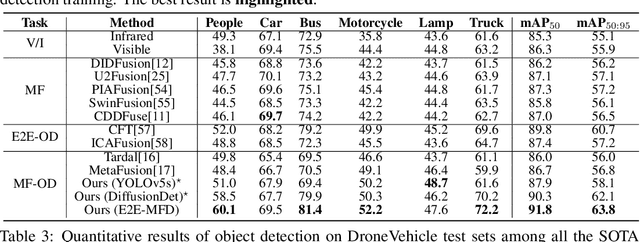

Multimodal image fusion and object detection play a vital role in autonomous driving. Current joint learning methods have made significant progress in the multimodal fusion detection task combining the texture detail and objective semantic information. However, the tedious training steps have limited its applications to wider real-world industrial deployment. To address this limitation, we propose a novel end-to-end multimodal fusion detection algorithm, named EfficientMFD, to simplify models that exhibit decent performance with only one training step. Synchronous joint optimization is utilized in an end-to-end manner between two components, thus not being affected by the local optimal solution of the individual task. Besides, a comprehensive optimization is established in the gradient matrix between the shared parameters for both tasks. It can converge to an optimal point with fusion detection weights. We extensively test it on several public datasets, demonstrating superior performance on not only visually appealing fusion but also favorable detection performance (e.g., 6.6% mAP50:95) over other state-of-the-art approaches.
Multimodal Informative ViT: Information Aggregation and Distribution for Hyperspectral and LiDAR Classification
Jan 06, 2024In multimodal land cover classification (MLCC), a common challenge is the redundancy in data distribution, where irrelevant information from multiple modalities can hinder the effective integration of their unique features. To tackle this, we introduce the Multimodal Informative Vit (MIVit), a system with an innovative information aggregate-distributing mechanism. This approach redefines redundancy levels and integrates performance-aware elements into the fused representation, facilitating the learning of semantics in both forward and backward directions. MIVit stands out by significantly reducing redundancy in the empirical distribution of each modality's separate and fused features. It employs oriented attention fusion (OAF) for extracting shallow local features across modalities in horizontal and vertical dimensions, and a Transformer feature extractor for extracting deep global features through long-range attention. We also propose an information aggregation constraint (IAC) based on mutual information, designed to remove redundant information and preserve complementary information within embedded features. Additionally, the information distribution flow (IDF) in MIVit enhances performance-awareness by distributing global classification information across different modalities' feature maps. This architecture also addresses missing modality challenges with lightweight independent modality classifiers, reducing the computational load typically associated with Transformers. Our results show that MIVit's bidirectional aggregate-distributing mechanism between modalities is highly effective, achieving an average overall accuracy of 95.56% across three multimodal datasets. This performance surpasses current state-of-the-art methods in MLCC. The code for MIVit is accessible at https://github.com/icey-zhang/MIViT.
Hardware-in-the-Loop Simulation for Evaluating Communication Impacts on the Wireless-Network-Controlled Robots
Jul 14, 2022
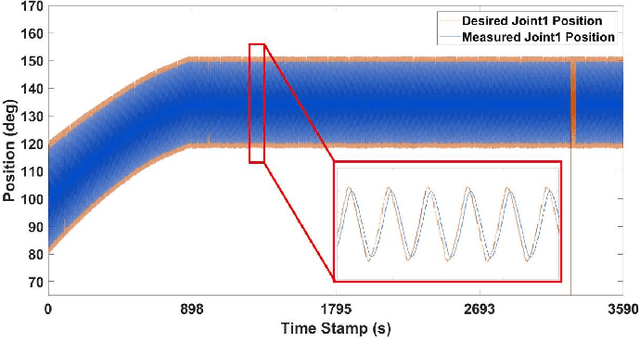

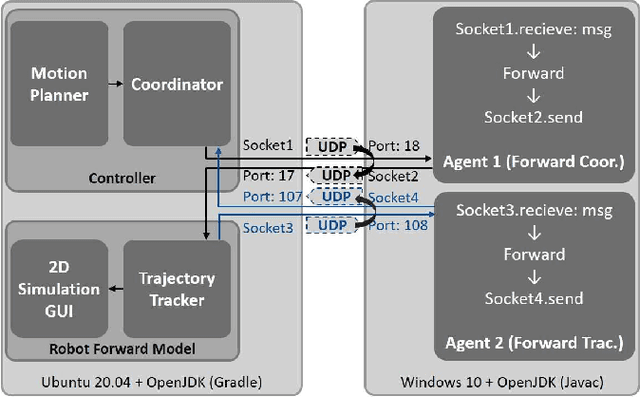
More and more robot automation applications have changed to wireless communication, and network performance has a growing impact on robotic systems. This study proposes a hardware-in-the-loop (HiL) simulation methodology for connecting the simulated robot platform to real network devices. This project seeks to provide robotic engineers and researchers with the capability to experiment without heavily modifying the original controller and get more realistic test results that correlate with actual network conditions. We deployed this HiL simulation system in two common cases for wireless-network-controlled robotic applications: (1) safe multi-robot coordination for mobile robots, and (2) human-motion-based teleoperation for manipulators. The HiL simulation system is deployed and tested under various network conditions in all circumstances. The experiment results are analyzed and compared with the previous simulation methods, demonstrating that the proposed HiL simulation methodology can identify a more reliable communication impact on robot systems.