 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOtter: Mitigating Background Distractions of Wide-Angle Few-Shot Action Recognition with Enhanced RWKV
Nov 11, 2025Wide-angle videos in few-shot action recognition (FSAR) effectively express actions within specific scenarios. However, without a global understanding of both subjects and background, recognizing actions in such samples remains challenging because of the background distractions. Receptance Weighted Key Value (RWKV), which learns interaction between various dimensions, shows promise for global modeling. While directly applying RWKV to wide-angle FSAR may fail to highlight subjects due to excessive background information. Additionally, temporal relation degraded by frames with similar backgrounds is difficult to reconstruct, further impacting performance. Therefore, we design the CompOund SegmenTation and Temporal REconstructing RWKV (Otter). Specifically, the Compound Segmentation Module~(CSM) is devised to segment and emphasize key patches in each frame, effectively highlighting subjects against background information. The Temporal Reconstruction Module (TRM) is incorporated into the temporal-enhanced prototype construction to enable bidirectional scanning, allowing better reconstruct temporal relation. Furthermore, a regular prototype is combined with the temporal-enhanced prototype to simultaneously enhance subject emphasis and temporal modeling, improving wide-angle FSAR performance. Extensive experiments on benchmarks such as SSv2, Kinetics, UCF101, and HMDB51 demonstrate that Otter achieves state-of-the-art performance. Extra evaluation on the VideoBadminton dataset further validates the superiority of Otter in wide-angle FSAR.
Generalizable Sensor-Based Activity Recognition via Categorical Concept Invariant Learning
Dec 18, 2024



Human Activity Recognition (HAR) aims to recognize activities by training models on massive sensor data. In real-world deployment, a crucial aspect of HAR that has been largely overlooked is that the test sets may have different distributions from training sets due to inter-subject variability including age, gender, behavioral habits, etc., which leads to poor generalization performance. One promising solution is to learn domain-invariant representations to enable a model to generalize on an unseen distribution. However, most existing methods only consider the feature-invariance of the penultimate layer for domain-invariant learning, which leads to suboptimal results. In this paper, we propose a Categorical Concept Invariant Learning (CCIL) framework for generalizable activity recognition, which introduces a concept matrix to regularize the model in the training stage by simultaneously concentrating on feature-invariance and logit-invariance. Our key idea is that the concept matrix for samples belonging to the same activity category should be similar. Extensive experiments on four public HAR benchmarks demonstrate that our CCIL substantially outperforms the state-of-the-art approaches under cross-person, cross-dataset, cross-position, and one-person-to-another settings.
Manta: Enhancing Mamba for Few-Shot Action Recognition of Long Sub-Sequence
Dec 10, 2024



In few-shot action recognition~(FSAR), long sub-sequences of video naturally express entire actions more effectively. However, the computational complexity of mainstream Transformer-based methods limits their application. Recent Mamba demonstrates efficiency in modeling long sequences, but directly applying Mamba to FSAR overlooks the importance of local feature modeling and alignment. Moreover, long sub-sequences within the same class accumulate intra-class variance, which adversely impacts FSAR performance. To solve these challenges, we propose a \underline{\textbf{M}}atryoshka M\underline{\textbf{A}}mba and Co\underline{\textbf{N}}tras\underline{\textbf{T}}ive Le\underline{\textbf{A}}rning framework~(\textbf{Manta}). Firstly, the Matryoshka Mamba introduces multiple Inner Modules to enhance local feature representation, rather than directly modeling global features. An Outer Module captures dependencies of timeline between these local features for implicit temporal alignment. Secondly, a hybrid contrastive learning paradigm, combining both supervised and unsupervised methods, is designed to mitigate the negative effects of intra-class variance accumulation. The Matryoshka Mamba and the hybrid contrastive learning paradigm operate in parallel branches within Manta, enhancing Mamba for FSAR of long sub-sequence. Manta achieves new state-of-the-art performance on prominent benchmarks, including SSv2, Kinetics, UCF101, and HMDB51. Extensive empirical studies prove that Manta significantly improves FSAR of long sub-sequence from multiple perspectives. The code is released at https://github.com/wenbohuang1002/Manta.
SOAP: Enhancing Spatio-Temporal Relation and Motion Information Capturing for Few-Shot Action Recognition
Jul 24, 2024



High frame-rate (HFR) videos of action recognition improve fine-grained expression while reducing the spatio-temporal relation and motion information density. Thus, large amounts of video samples are continuously required for traditional data-driven training. However, samples are not always sufficient in real-world scenarios, promoting few-shot action recognition (FSAR) research. We observe that most recent FSAR works build spatio-temporal relation of video samples via temporal alignment after spatial feature extraction, cutting apart spatial and temporal features within samples. They also capture motion information via narrow perspectives between adjacent frames without considering density, leading to insufficient motion information capturing. Therefore, we propose a novel plug-and-play architecture for FSAR called Spatio-tempOral frAme tuPle enhancer (SOAP) in this paper. The model we designed with such architecture refers to SOAP-Net. Temporal connections between different feature channels and spatio-temporal relation of features are considered instead of simple feature extraction. Comprehensive motion information is also captured, using frame tuples with multiple frames containing more motion information than adjacent frames. Combining frame tuples of diverse frame counts further provides a broader perspective. SOAP-Net achieves new state-of-the-art performance across well-known benchmarks such as SthSthV2, Kinetics, UCF101, and HMDB51. Extensive empirical evaluations underscore the competitiveness, pluggability, generalization, and robustness of SOAP. The code is released at https://github.com/wenbohuang1002/SOAP.
EfficientMFD: Towards More Efficient Multimodal Synchronous Fusion Detection
Mar 14, 2024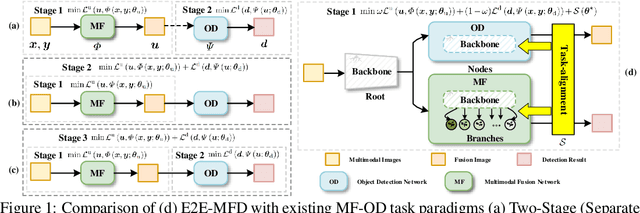
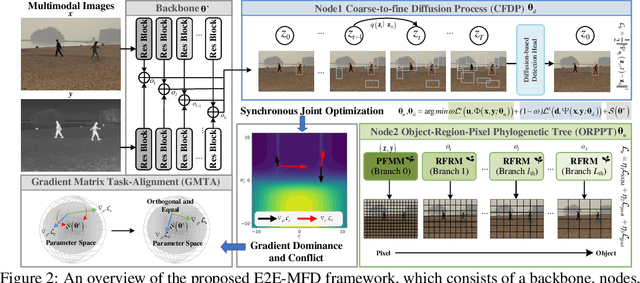
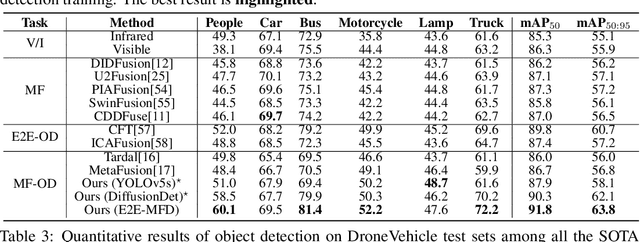

Multimodal image fusion and object detection play a vital role in autonomous driving. Current joint learning methods have made significant progress in the multimodal fusion detection task combining the texture detail and objective semantic information. However, the tedious training steps have limited its applications to wider real-world industrial deployment. To address this limitation, we propose a novel end-to-end multimodal fusion detection algorithm, named EfficientMFD, to simplify models that exhibit decent performance with only one training step. Synchronous joint optimization is utilized in an end-to-end manner between two components, thus not being affected by the local optimal solution of the individual task. Besides, a comprehensive optimization is established in the gradient matrix between the shared parameters for both tasks. It can converge to an optimal point with fusion detection weights. We extensively test it on several public datasets, demonstrating superior performance on not only visually appealing fusion but also favorable detection performance (e.g., 6.6% mAP50:95) over other state-of-the-art approaches.