 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregation Queries over Unstructured Text: Benchmark and Agentic Method
Feb 03, 2026Aggregation query over free text is a long-standing yet underexplored problem. Unlike ordinary question answering, aggregate queries require exhaustive evidence collection and systems are required to "find all," not merely "find one." Existing paradigms such as Text-to-SQL and Retrieval-Augmented Generation fail to achieve this completeness. In this work, we formalize entity-level aggregation querying over text in a corpus-bounded setting with strict completeness requirement. To enable principled evaluation, we introduce AGGBench, a benchmark designed to evaluate completeness-oriented aggregation under realistic large-scale corpus. To accompany the benchmark, we propose DFA (Disambiguation--Filtering--Aggregation), a modular agentic baseline that decomposes aggregation querying into interpretable stages and exposes key failure modes related to ambiguity, filtering, and aggregation. Empirical results show that DFA consistently improves aggregation evidence coverage over strong RAG and agentic baselines. The data and code are available in \href{https://anonymous.4open.science/r/DFA-A4C1}.
Boundary Prompting: Elastic Urban Region Representation via Graph-based Spatial Tokenization
Mar 11, 2025Urban region representation is essential for various applications such as urban planning, resource allocation, and policy development. Traditional methods rely on fixed, predefined region boundaries, which fail to capture the dynamic and complex nature of real-world urban areas. In this paper, we propose the Boundary Prompting Urban Region Representation Framework (BPURF), a novel approach that allows for elastic urban region definitions. BPURF comprises two key components: (1) A spatial token dictionary, where urban entities are treated as tokens and integrated into a unified token graph, and (2) a region token set representation model which utilize token aggregation and a multi-channel model to embed token sets corresponding to region boundaries. Additionally, we propose fast token set extraction strategy to enable online token set extraction during training and prompting. This framework enables the definition of urban regions through boundary prompting, supporting varying region boundaries and adapting to different tasks. Extensive experiments demonstrate the effectiveness of BPURF in capturing the complex characteristics of urban regions.
Manta: Enhancing Mamba for Few-Shot Action Recognition of Long Sub-Sequence
Dec 10, 2024



In few-shot action recognition~(FSAR), long sub-sequences of video naturally express entire actions more effectively. However, the computational complexity of mainstream Transformer-based methods limits their application. Recent Mamba demonstrates efficiency in modeling long sequences, but directly applying Mamba to FSAR overlooks the importance of local feature modeling and alignment. Moreover, long sub-sequences within the same class accumulate intra-class variance, which adversely impacts FSAR performance. To solve these challenges, we propose a \underline{\textbf{M}}atryoshka M\underline{\textbf{A}}mba and Co\underline{\textbf{N}}tras\underline{\textbf{T}}ive Le\underline{\textbf{A}}rning framework~(\textbf{Manta}). Firstly, the Matryoshka Mamba introduces multiple Inner Modules to enhance local feature representation, rather than directly modeling global features. An Outer Module captures dependencies of timeline between these local features for implicit temporal alignment. Secondly, a hybrid contrastive learning paradigm, combining both supervised and unsupervised methods, is designed to mitigate the negative effects of intra-class variance accumulation. The Matryoshka Mamba and the hybrid contrastive learning paradigm operate in parallel branches within Manta, enhancing Mamba for FSAR of long sub-sequence. Manta achieves new state-of-the-art performance on prominent benchmarks, including SSv2, Kinetics, UCF101, and HMDB51. Extensive empirical studies prove that Manta significantly improves FSAR of long sub-sequence from multiple perspectives. The code is released at https://github.com/wenbohuang1002/Manta.
An Event-centric Framework for Predicting Crime Hotspots with Flexible Time Intervals
Nov 02, 2024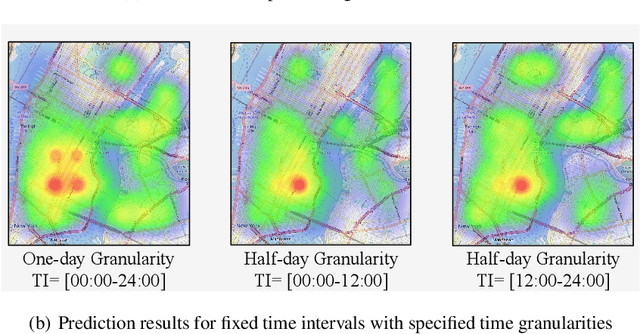

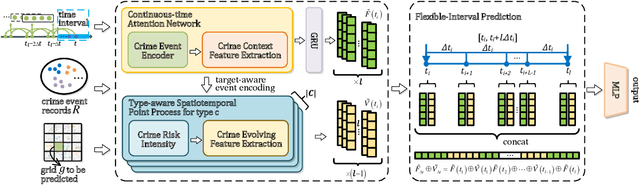

Predicting crime hotspots in a city is a complex and critical task with significant societal implications. Numerous spatiotemporal correlations and irregularities pose substantial challenges to this endeavor. Existing methods commonly employ fixed-time granularities and sequence prediction models. However, determining appropriate time granularities is difficult, leading to inaccurate predictions for specific time windows. For example, users might ask: What are the crime hotspots during 12:00-20:00? To address this issue, we introduce FlexiCrime, a novel event-centric framework for predicting crime hotspots with flexible time intervals. FlexiCrime incorporates a continuous-time attention network to capture correlations between crime events, which learns crime context features, representing general crime patterns across time points and locations. Furthermore, we introduce a type-aware spatiotemporal point process that learns crime-evolving features, measuring the risk of specific crime types at a given time and location by considering the frequency of past crime events. The crime context and evolving features together allow us to predict whether an urban area is a crime hotspot given a future time interval. To evaluate FlexiCrime's effectiveness, we conducted experiments using real-world datasets from two cities, covering twelve crime types. The results show that our model outperforms baseline techniques in predicting crime hotspots over flexible time intervals.
Urban Region Pre-training and Prompting: A Graph-based Approach
Aug 12, 2024



Urban region representation is crucial for various urban downstream tasks. However, despite the proliferation of methods and their success, acquiring general urban region knowledge and adapting to different tasks remains challenging. Previous work often neglects the spatial structures and functional layouts between entities, limiting their ability to capture transferable knowledge across regions. Further, these methods struggle to adapt effectively to specific downstream tasks, as they do not adequately address the unique features and relationships required for different downstream tasks. In this paper, we propose a $\textbf{G}$raph-based $\textbf{U}$rban $\textbf{R}$egion $\textbf{P}$re-training and $\textbf{P}$rompting framework ($\textbf{GURPP}$) for region representation learning. Specifically, we first construct an urban region graph that integrates detailed spatial entity data for more effective urban region representation. Then, we develop a subgraph-centric urban region pre-training model to capture the heterogeneous and transferable patterns of interactions among entities. To further enhance the adaptability of these embeddings to different tasks, we design two graph-based prompting methods to incorporate explicit/hidden task knowledge. Extensive experiments on various urban region prediction tasks and different cities demonstrate the superior performance of our GURPP framework. The implementation is available at this repository: https://anonymous.4open.science/r/GURPP.
Real-Time Network-Level Traffic Signal Control: An Explicit Multiagent Coordination Method
Jun 15, 2023Efficient traffic signal control (TSC) has been one of the most useful ways for reducing urban road congestion. Key to the challenge of TSC includes 1) the essential of real-time signal decision, 2) the complexity in traffic dynamics, and 3) the network-level coordination. Recent efforts that applied reinforcement learning (RL) methods can query policies by mapping the traffic state to the signal decision in real-time, however, is inadequate for unexpected traffic flows. By observing real traffic information, online planning methods can compute the signal decisions in a responsive manner. We propose an explicit multiagent coordination (EMC)-based online planning methods that can satisfy adaptive, real-time and network-level TSC. By multiagent, we model each intersection as an autonomous agent, and the coordination efficiency is modeled by a cost (i.e., congestion index) function between neighbor intersections. By network-level coordination, each agent exchanges messages with respect to cost function with its neighbors in a fully decentralized manner. By real-time, the message passing procedure can interrupt at any time when the real time limit is reached and agents select the optimal signal decisions according to the current message. Moreover, we prove our EMC method can guarantee network stability by borrowing ideas from transportation domain. Finally, we test our EMC method in both synthetic and real road network datasets. Experimental results are encouraging: compared to RL and conventional transportation baselines, our EMC method performs reasonably well in terms of adapting to real-time traffic dynamics, minimizing vehicle travel time and scalability to city-scale road networks.
Label Information Enhanced Fraud Detection against Low Homophily in Graphs
Feb 21, 2023



Node classification is a substantial problem in graph-based fraud detection. Many existing works adopt Graph Neural Networks (GNNs) to enhance fraud detectors. While promising, currently most GNN-based fraud detectors fail to generalize to the low homophily setting. Besides, label utilization has been proved to be significant factor for node classification problem. But we find they are less effective in fraud detection tasks due to the low homophily in graphs. In this work, we propose GAGA, a novel Group AGgregation enhanced TrAnsformer, to tackle the above challenges. Specifically, the group aggregation provides a portable method to cope with the low homophily issue. Such an aggregation explicitly integrates the label information to generate distinguishable neighborhood information. Along with group aggregation, an attempt towards end-to-end trainable group encoding is proposed which augments the original feature space with the class labels. Meanwhile, we devise two additional learnable encodings to recognize the structural and relational context. Then, we combine the group aggregation and the learnable encodings into a Transformer encoder to capture the semantic information. Experimental results clearly show that GAGA outperforms other competitive graph-based fraud detectors by up to 24.39% on two trending public datasets and a real-world industrial dataset from Anonymous. Even more, the group aggregation is demonstrated to outperform other label utilization methods (e.g., C&S, BoT/UniMP) in the low homophily setting.