 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoTraces: Autoregressive Trajectory Forecasting via Multimodal Large Language Models
Mar 09, 2026We present AutoTraces, an autoregressive vision-language-trajectory model for robot trajectory forecasting in humam-populated environments, which harnesses the inherent reasoning capabilities of large language models (LLMs) to model complex human behaviors. In contrast to prior works that rely solely on textual representations, our key innovation lies in a novel trajectory tokenization scheme, which represents waypoints with point tokens as categorical and positional markers while encoding waypoint numerical values as corresponding point embeddings, seamlessly integrated into the LLM's space through a lightweight encoder-decoder architecture. This design preserves the LLM's native autoregressive generation mechanism while extending it to physical coordinate spaces, facilitates modeling of long-term interactions in trajectory data. We further introduce an automated chain-of-thought (CoT) generation mechanism that leverages a multimodal LLM to infer spatio-temporal relationships from visual observations and trajectory data, eliminating reliance on manual annotation. Through a two-stage training strategy, our AutoTraces achieves SOTA forecasting accuracy, particularly in long-horizon prediction, while exhibiting strong cross-scene generalization and supporting flexible-length forecasting.
Orientation Learning and Adaptation towards Simultaneous Incorporation of Multiple Local Constraints
Oct 09, 2025Orientation learning plays a pivotal role in many tasks. However, the rotation group SO(3) is a Riemannian manifold. As a result, the distortion caused by non-Euclidean geometric nature introduces difficulties to the incorporation of local constraints, especially for the simultaneous incorporation of multiple local constraints. To address this issue, we propose the Angle-Axis Space-based orientation representation method to solve several orientation learning problems, including orientation adaptation and minimization of angular acceleration. Specifically, we propose a weighted average mechanism in SO(3) based on the angle-axis representation method. Our main idea is to generate multiple trajectories by considering different local constraints at different basepoints. Then these multiple trajectories are fused to generate a smooth trajectory by our proposed weighted average mechanism, achieving the goal to incorporate multiple local constraints simultaneously. Compared with existing solution, ours can address the distortion issue and make the off-theshelf Euclidean learning algorithm be re-applicable in non-Euclidean space. Simulation and Experimental evaluations validate that our solution can not only adapt orientations towards arbitrary desired via-points and cope with angular acceleration constraints, but also incorporate multiple local constraints simultaneously to achieve extra benefits, e.g., achieving smaller acceleration costs.
The Developments and Challenges towards Dexterous and Embodied Robotic Manipulation: A Survey
Jul 16, 2025Achieving human-like dexterous robotic manipulation remains a central goal and a pivotal challenge in robotics. The development of Artificial Intelligence (AI) has allowed rapid progress in robotic manipulation. This survey summarizes the evolution of robotic manipulation from mechanical programming to embodied intelligence, alongside the transition from simple grippers to multi-fingered dexterous hands, outlining key characteristics and main challenges. Focusing on the current stage of embodied dexterous manipulation, we highlight recent advances in two critical areas: dexterous manipulation data collection (via simulation, human demonstrations, and teleoperation) and skill-learning frameworks (imitation and reinforcement learning). Then, based on the overview of the existing data collection paradigm and learning framework, three key challenges restricting the development of dexterous robotic manipulation are summarized and discussed.
Boundary Prompting: Elastic Urban Region Representation via Graph-based Spatial Tokenization
Mar 11, 2025Urban region representation is essential for various applications such as urban planning, resource allocation, and policy development. Traditional methods rely on fixed, predefined region boundaries, which fail to capture the dynamic and complex nature of real-world urban areas. In this paper, we propose the Boundary Prompting Urban Region Representation Framework (BPURF), a novel approach that allows for elastic urban region definitions. BPURF comprises two key components: (1) A spatial token dictionary, where urban entities are treated as tokens and integrated into a unified token graph, and (2) a region token set representation model which utilize token aggregation and a multi-channel model to embed token sets corresponding to region boundaries. Additionally, we propose fast token set extraction strategy to enable online token set extraction during training and prompting. This framework enables the definition of urban regions through boundary prompting, supporting varying region boundaries and adapting to different tasks. Extensive experiments demonstrate the effectiveness of BPURF in capturing the complex characteristics of urban regions.
ADSNet: Cross-Domain LTV Prediction with an Adaptive Siamese Network in Advertising
Jun 15, 2024



Advertising platforms have evolved in estimating Lifetime Value (LTV) to better align with advertisers' true performance metric. However, the sparsity of real-world LTV data presents a significant challenge to LTV predictive model(i.e., pLTV), severely limiting the their capabilities. Therefore, we propose to utilize external data, in addition to the internal data of advertising platform, to expand the size of purchase samples and enhance the LTV prediction model of the advertising platform. To tackle the issue of data distribution shift between internal and external platforms, we introduce an Adaptive Difference Siamese Network (ADSNet), which employs cross-domain transfer learning to prevent negative transfer. Specifically, ADSNet is designed to learn information that is beneficial to the target domain. We introduce a gain evaluation strategy to calculate information gain, aiding the model in learning helpful information for the target domain and providing the ability to reject noisy samples, thus avoiding negative transfer. Additionally, we also design a Domain Adaptation Module as a bridge to connect different domains, reduce the distribution distance between them, and enhance the consistency of representation space distribution. We conduct extensive offline experiments and online A/B tests on a real advertising platform. Our proposed ADSNet method outperforms other methods, improving GINI by 2$\%$. The ablation study highlights the importance of the gain evaluation strategy in negative gain sample rejection and improving model performance. Additionally, ADSNet significantly improves long-tail prediction. The online A/B tests confirm ADSNet's efficacy, increasing online LTV by 3.47$\%$ and GMV by 3.89$\%$.
K-AID: Enhancing Pre-trained Language Models with Domain Knowledge for Question Answering
Sep 22, 2021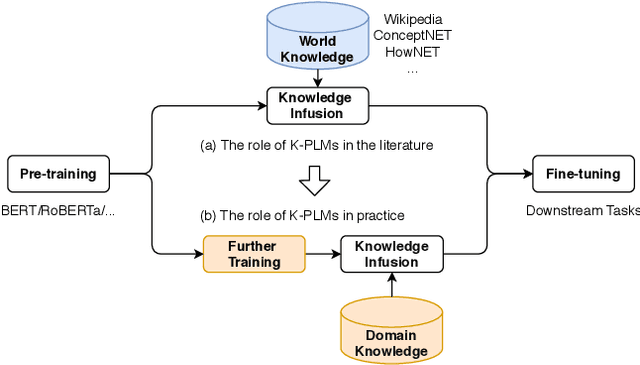

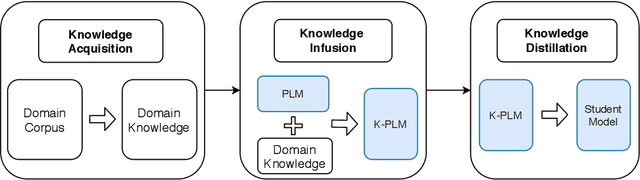
Knowledge enhanced pre-trained language models (K-PLMs) are shown to be effective for many public tasks in the literature but few of them have been successfully applied in practice. To address this problem, we propose K-AID, a systematic approach that includes a low-cost knowledge acquisition process for acquiring domain knowledge, an effective knowledge infusion module for improving model performance, and a knowledge distillation component for reducing the model size and deploying K-PLMs on resource-restricted devices (e.g., CPU) for real-world application. Importantly, instead of capturing entity knowledge like the majority of existing K-PLMs, our approach captures relational knowledge, which contributes to better-improving sentence-level text classification and text matching tasks that play a key role in question answering (QA). We conducted a set of experiments on five text classification tasks and three text matching tasks from three domains, namely E-commerce, Government, and Film&TV, and performed online A/B tests in E-commerce. Experimental results show that our approach is able to achieve substantial improvement on sentence-level question answering tasks and bring beneficial business value in industrial settings.
TCIC: Theme Concepts Learning Cross Language and Vision for Image Captioning
Jun 21, 2021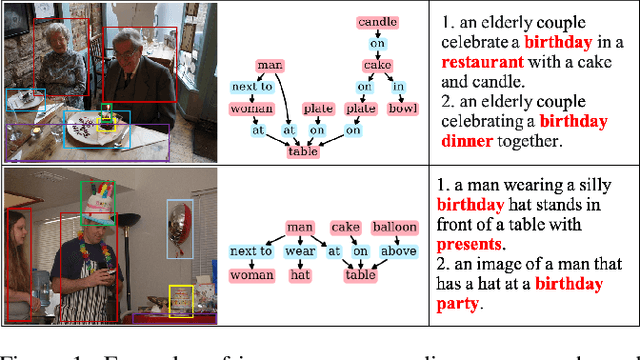
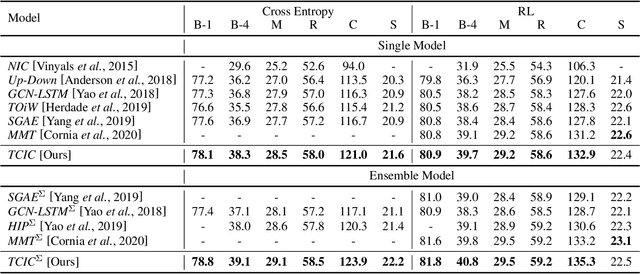
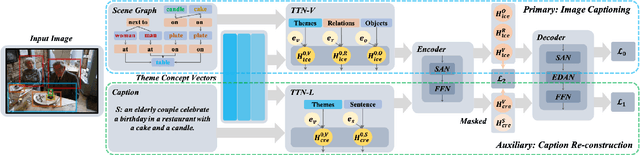
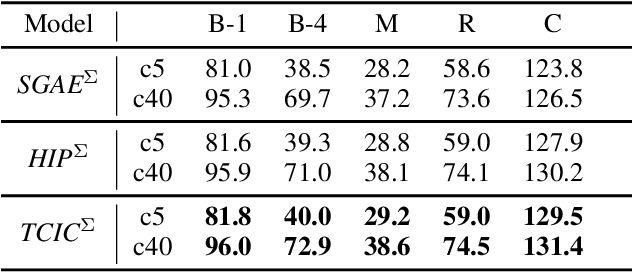
Existing research for image captioning usually represents an image using a scene graph with low-level facts (objects and relations) and fails to capture the high-level semantics. In this paper, we propose a Theme Concepts extended Image Captioning (TCIC) framework that incorporates theme concepts to represent high-level cross-modality semantics. In practice, we model theme concepts as memory vectors and propose Transformer with Theme Nodes (TTN) to incorporate those vectors for image captioning. Considering that theme concepts can be learned from both images and captions, we propose two settings for their representations learning based on TTN. On the vision side, TTN is configured to take both scene graph based features and theme concepts as input for visual representation learning. On the language side, TTN is configured to take both captions and theme concepts as input for text representation re-construction. Both settings aim to generate target captions with the same transformer-based decoder. During the training, we further align representations of theme concepts learned from images and corresponding captions to enforce the cross-modality learning. Experimental results on MS COCO show the effectiveness of our approach compared to some state-of-the-art models.
Neural Deepfake Detection with Factual Structure of Text
Oct 15, 2020
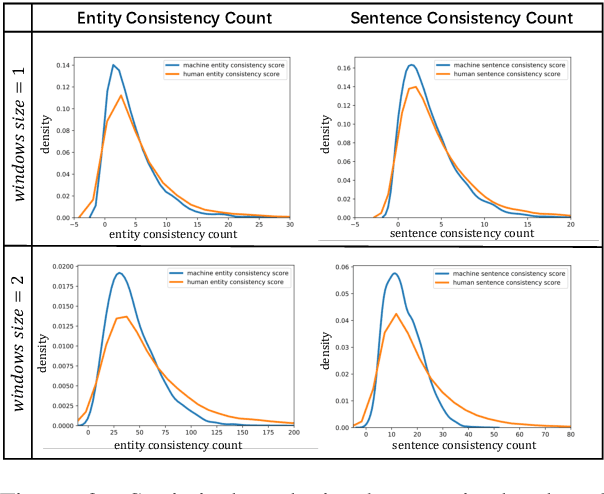
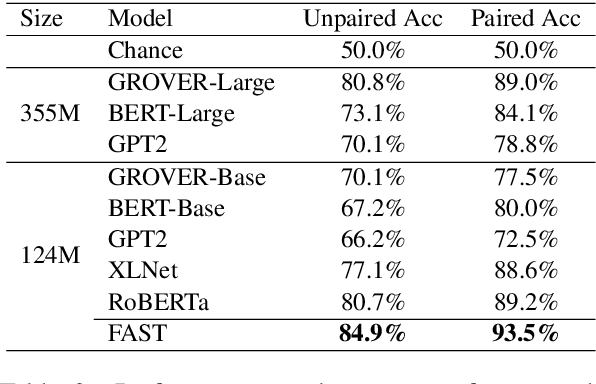
Deepfake detection, the task of automatically discriminating machine-generated text, is increasingly critical with recent advances in natural language generative models. Existing approaches to deepfake detection typically represent documents with coarse-grained representations. However, they struggle to capture factual structures of documents, which is a discriminative factor between machine-generated and human-written text according to our statistical analysis. To address this, we propose a graph-based model that utilizes the factual structure of a document for deepfake detection of text. Our approach represents the factual structure of a given document as an entity graph, which is further utilized to learn sentence representations with a graph neural network. Sentence representations are then composed to a document representation for making predictions, where consistent relations between neighboring sentences are sequentially modeled. Results of experiments on two public deepfake datasets show that our approach significantly improves strong base models built with RoBERTa. Model analysis further indicates that our model can distinguish the difference in the factual structure between machine-generated text and human-written text.
Look, Listen, and Attend: Co-Attention Network for Self-Supervised Audio-Visual Representation Learning
Aug 13, 2020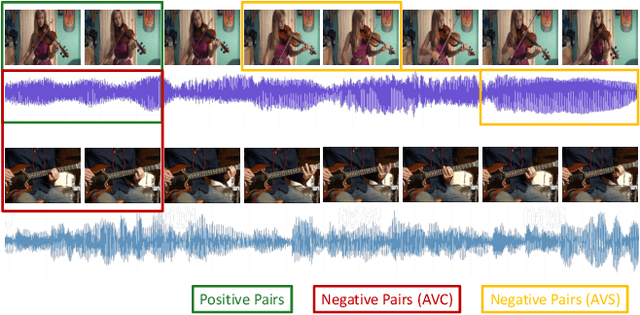
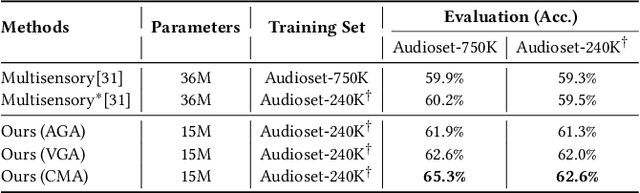
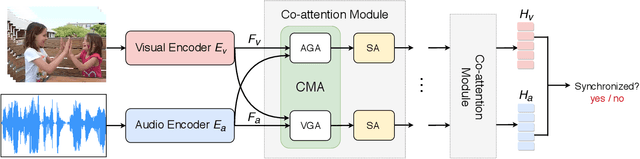
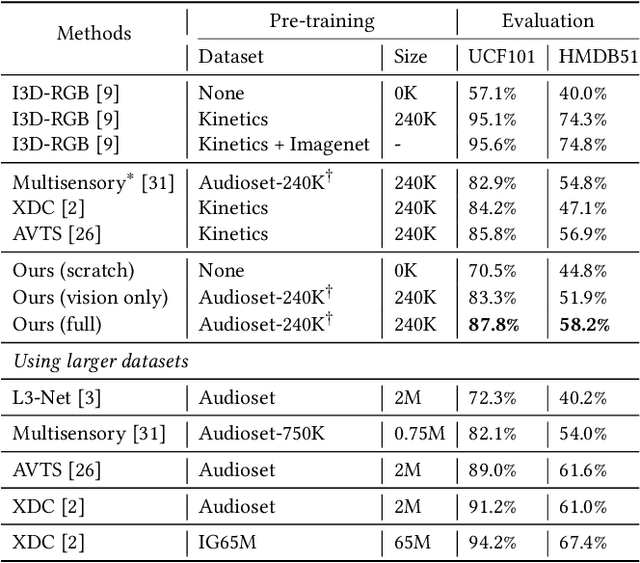
When watching videos, the occurrence of a visual event is often accompanied by an audio event, e.g., the voice of lip motion, the music of playing instruments. There is an underlying correlation between audio and visual events, which can be utilized as free supervised information to train a neural network by solving the pretext task of audio-visual synchronization. In this paper, we propose a novel self-supervised framework with co-attention mechanism to learn generic cross-modal representations from unlabelled videos in the wild, and further benefit downstream tasks. Specifically, we explore three different co-attention modules to focus on discriminative visual regions correlated to the sounds and introduce the interactions between them. Experiments show that our model achieves state-of-the-art performance on the pretext task while having fewer parameters compared with existing methods. To further evaluate the generalizability and transferability of our approach, we apply the pre-trained model on two downstream tasks, i.e., sound source localization and action recognition. Extensive experiments demonstrate that our model provides competitive results with other self-supervised methods, and also indicate that our approach can tackle the challenging scenes which contain multiple sound sources.
Leveraging Declarative Knowledge in Text and First-Order Logic for Fine-Grained Propaganda Detection
Apr 29, 2020
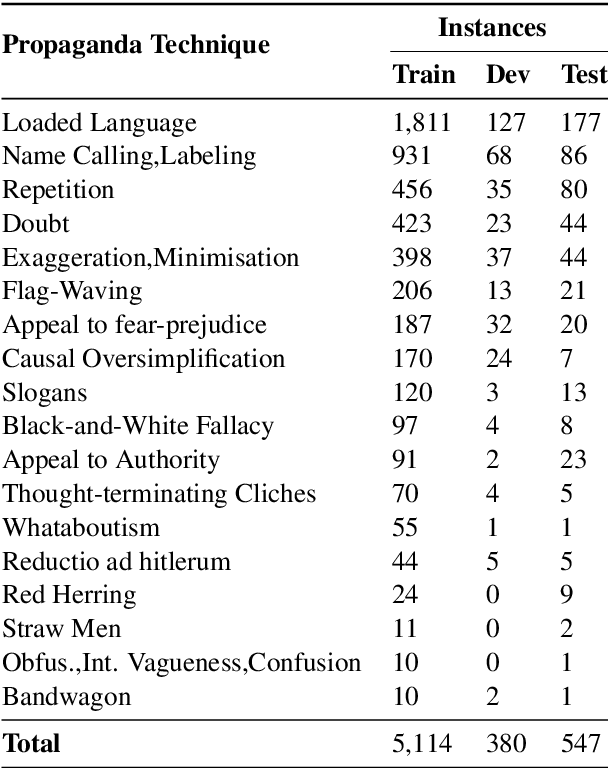
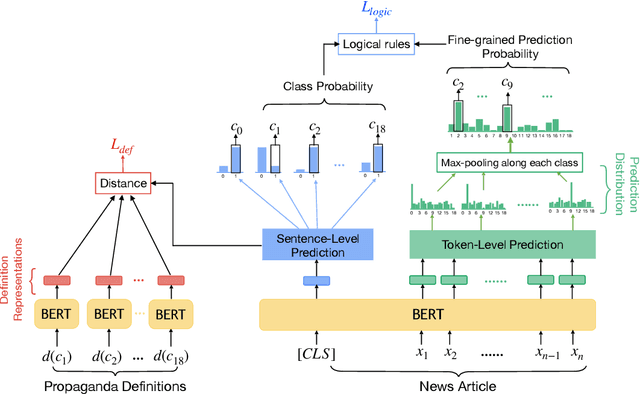
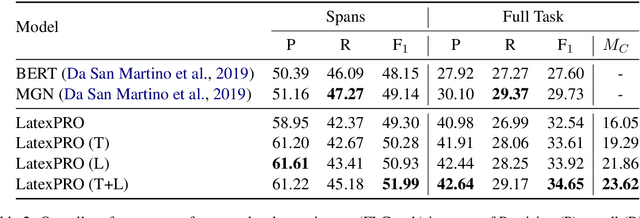
We study the detection of propagandistic text fragments in news articles. Instead of merely learning from input-output datapoints in training data, we introduce an approach to inject declarative knowledge of fine-grained propaganda techniques. We leverage declarative knowledge expressed in both natural language and first-order logic. The former refers to the literal definition of each propaganda technique, which is utilized to get class representations for regularizing the model parameters. The latter refers to logical consistency between coarse- and fine- grained predictions, which is used to regularize the training process with propositional Boolean expressions. We conduct experiments on Propaganda Techniques Corpus, a large manually annotated dataset for fine-grained propaganda detection. Experiments show that our method achieves superior performance, demonstrating that injecting declarative knowledge expressed in both natural language and first-order logic can help the model to make more accurate predictions.