 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-AID: Enhancing Pre-trained Language Models with Domain Knowledge for Question Answering
Paper and Code
Sep 22, 2021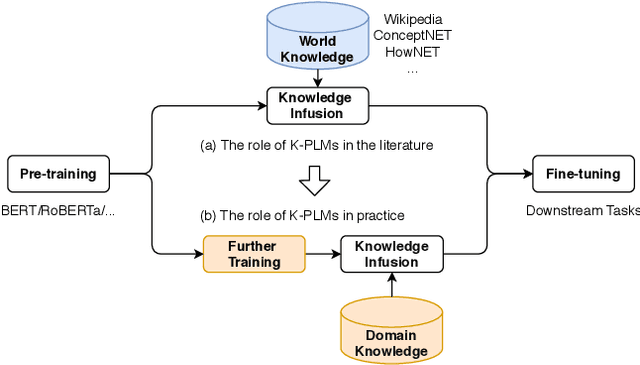

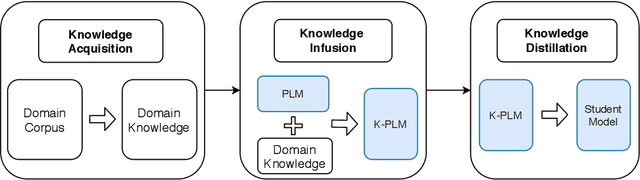
Knowledge enhanced pre-trained language models (K-PLMs) are shown to be effective for many public tasks in the literature but few of them have been successfully applied in practice. To address this problem, we propose K-AID, a systematic approach that includes a low-cost knowledge acquisition process for acquiring domain knowledge, an effective knowledge infusion module for improving model performance, and a knowledge distillation component for reducing the model size and deploying K-PLMs on resource-restricted devices (e.g., CPU) for real-world application. Importantly, instead of capturing entity knowledge like the majority of existing K-PLMs, our approach captures relational knowledge, which contributes to better-improving sentence-level text classification and text matching tasks that play a key role in question answering (QA). We conducted a set of experiments on five text classification tasks and three text matching tasks from three domains, namely E-commerce, Government, and Film&TV, and performed online A/B tests in E-commerce. Experimental results show that our approach is able to achieve substantial improvement on sentence-level question answering tasks and bring beneficial business value in industrial settings.