 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOPE: Compress Mathematical Reasoning Steps for Efficient Automated Process Annotation
May 20, 2025



Process Reward Models (PRMs) have demonstrated promising results in mathematical reasoning, but existing process annotation approaches, whether through human annotations or Monte Carlo simulations, remain computationally expensive. In this paper, we introduce Step COmpression for Process Estimation (SCOPE), a novel compression-based approach that significantly reduces annotation costs. We first translate natural language reasoning steps into code and normalize them through Abstract Syntax Tree, then merge equivalent steps to construct a prefix tree. Unlike simulation-based methods that waste numerous samples on estimation, SCOPE leverages a compression-based prefix tree where each root-to-leaf path serves as a training sample, reducing the complexity from $O(NMK)$ to $O(N)$. We construct a large-scale dataset containing 196K samples with only 5% of the computational resources required by previous methods. Empirical results demonstrate that PRMs trained on our dataset consistently outperform existing automated annotation approaches on both Best-of-N strategy and ProcessBench.
Full-Step-DPO: Self-Supervised Preference Optimization with Step-wise Rewards for Mathematical Reasoning
Feb 20, 2025Direct Preference Optimization (DPO) often struggles with long-chain mathematical reasoning. Existing approaches, such as Step-DPO, typically improve this by focusing on the first erroneous step in the reasoning chain. However, they overlook all other steps and rely heavily on humans or GPT-4 to identify erroneous steps. To address these issues, we propose Full-Step-DPO, a novel DPO framework tailored for mathematical reasoning. Instead of optimizing only the first erroneous step, it leverages step-wise rewards from the entire reasoning chain. This is achieved by training a self-supervised process reward model, which automatically scores each step, providing rewards while avoiding reliance on external signals. Furthermore, we introduce a novel step-wise DPO loss, which dynamically updates gradients based on these step-wise rewards. This endows stronger reasoning capabilities to language models. Extensive evaluations on both in-domain and out-of-domain mathematical reasoning benchmarks across various base language models, demonstrate that Full-Step-DPO achieves superior performance compared to state-of-the-art baselines.
As Simple as Fine-tuning: LLM Alignment via Bidirectional Negative Feedback Loss
Oct 07, 2024



Direct Preference Optimization (DPO) has emerged as a more computationally efficient alternative to Reinforcement Learning from Human Feedback (RLHF) with Proximal Policy Optimization (PPO), eliminating the need for reward models and online sampling. Despite these benefits, DPO and its variants remain sensitive to hyper-parameters and prone to instability, particularly on mathematical datasets. We argue that these issues arise from the unidirectional likelihood-derivative negative feedback inherent in the log-likelihood loss function. To address this, we propose a novel LLM alignment loss that establishes a stable Bidirectional Negative Feedback (BNF) during optimization. Our proposed BNF loss eliminates the need for pairwise contrastive losses and does not require any extra tunable hyper-parameters or pairwise preference data, streamlining the alignment pipeline to be as simple as supervised fine-tuning. We conduct extensive experiments across two challenging QA benchmarks and four reasoning benchmarks. The experimental results show that BNF achieves comparable performance to the best methods on QA benchmarks, while its performance decrease on the four reasoning benchmarks is significantly lower compared to the best methods, thus striking a better balance between value alignment and reasoning ability. In addition, we further validate the performance of BNF on non-pairwise datasets, and conduct in-depth analysis of log-likelihood and logit shifts across different preference optimization methods.
Don't Forget Your Reward Values: Language Model Alignment via Value-based Calibration
Feb 25, 2024



While Reinforcement Learning from Human Feedback (RLHF) significantly enhances the generation quality of Large Language Models (LLMs), recent studies have raised concerns regarding the complexity and instability associated with the Proximal Policy Optimization (PPO) algorithm, proposing a series of order-based calibration methods as viable alternatives. This paper delves further into current order-based methods, examining their inefficiencies in utilizing reward values and addressing misalignment issues. Building upon these findings, we propose a novel \textbf{V}alue-based \textbf{C}ali\textbf{B}ration (VCB) method to better align LLMs with human preferences. Experimental results demonstrate that VCB surpasses existing alignment methods on AI assistant and summarization datasets, providing impressive generalizability, robustness, and stability in diverse settings.
AMTSS: An Adaptive Multi-Teacher Single-Student Knowledge Distillation Framework For Multilingual Language Inference
May 13, 2023



Knowledge distillation is of key importance to launching multilingual pre-trained language models for real applications. To support cost-effective language inference in multilingual settings, we propose AMTSS, an adaptive multi-teacher single-student distillation framework, which allows distilling knowledge from multiple teachers to a single student. We first introduce an adaptive learning strategy and teacher importance weight, which enables a student to effectively learn from max-margin teachers and easily adapt to new languages. Moreover, we present a shared student encoder with different projection layers in support of multiple languages, which contributes to largely reducing development and machine cost. Experimental results show that AMTSS gains competitive results on the public XNLI dataset and the realistic industrial dataset AliExpress (AE) in the E-commerce scenario.
DictBERT: Dictionary Description Knowledge Enhanced Language Model Pre-training via Contrastive Learning
Aug 01, 2022
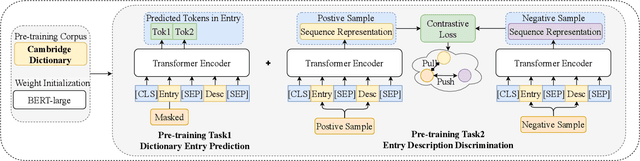

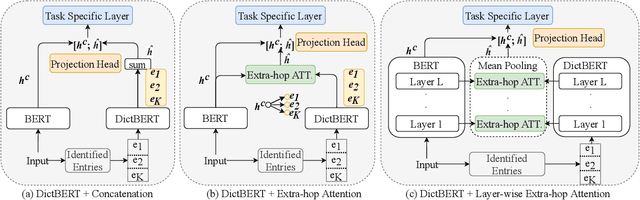
Although pre-trained language models (PLMs) have achieved state-of-the-art performance on various natural language processing (NLP) tasks, they are shown to be lacking in knowledge when dealing with knowledge driven tasks. Despite the many efforts made for injecting knowledge into PLMs, this problem remains open. To address the challenge, we propose \textbf{DictBERT}, a novel approach that enhances PLMs with dictionary knowledge which is easier to acquire than knowledge graph (KG). During pre-training, we present two novel pre-training tasks to inject dictionary knowledge into PLMs via contrastive learning: \textit{dictionary entry prediction} and \textit{entry description discrimination}. In fine-tuning, we use the pre-trained DictBERT as a plugin knowledge base (KB) to retrieve implicit knowledge for identified entries in an input sequence, and infuse the retrieved knowledge into the input to enhance its representation via a novel extra-hop attention mechanism. We evaluate our approach on a variety of knowledge driven and language understanding tasks, including NER, relation extraction, CommonsenseQA, OpenBookQA and GLUE. Experimental results demonstrate that our model can significantly improve typical PLMs: it gains a substantial improvement of 0.5\%, 2.9\%, 9.0\%, 7.1\% and 3.3\% on BERT-large respectively, and is also effective on RoBERTa-large.
K-AID: Enhancing Pre-trained Language Models with Domain Knowledge for Question Answering
Sep 22, 2021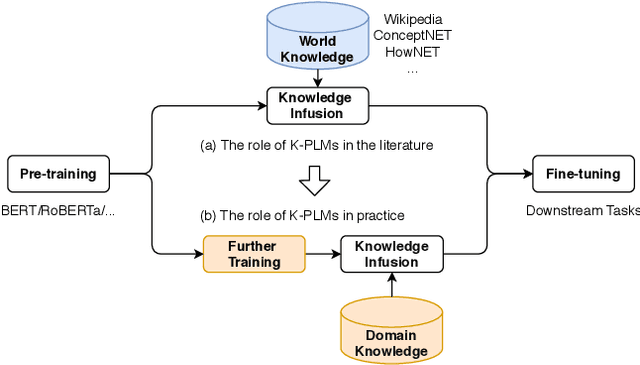

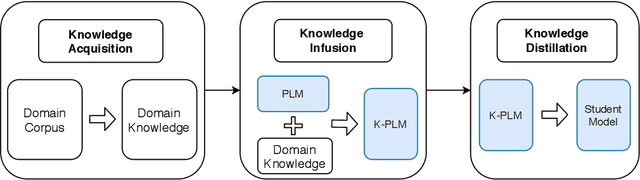
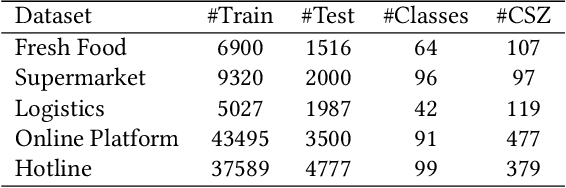
Knowledge enhanced pre-trained language models (K-PLMs) are shown to be effective for many public tasks in the literature but few of them have been successfully applied in practice. To address this problem, we propose K-AID, a systematic approach that includes a low-cost knowledge acquisition process for acquiring domain knowledge, an effective knowledge infusion module for improving model performance, and a knowledge distillation component for reducing the model size and deploying K-PLMs on resource-restricted devices (e.g., CPU) for real-world application. Importantly, instead of capturing entity knowledge like the majority of existing K-PLMs, our approach captures relational knowledge, which contributes to better-improving sentence-level text classification and text matching tasks that play a key role in question answering (QA). We conducted a set of experiments on five text classification tasks and three text matching tasks from three domains, namely E-commerce, Government, and Film&TV, and performed online A/B tests in E-commerce. Experimental results show that our approach is able to achieve substantial improvement on sentence-level question answering tasks and bring beneficial business value in industrial settings.
AliMe MKG: A Multi-modal Knowledge Graph for Live-streaming E-commerce
Sep 13, 2021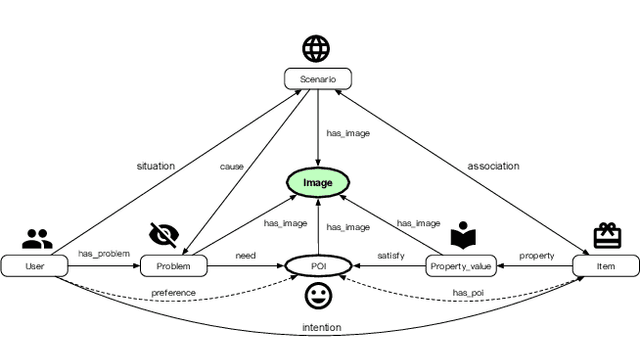
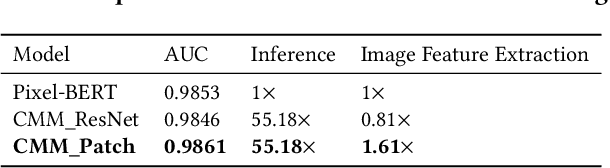
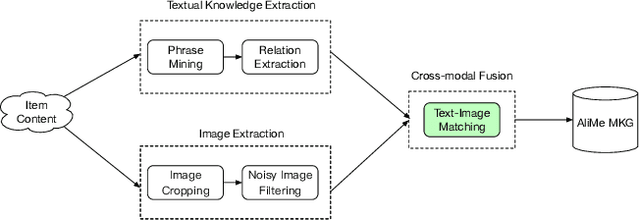
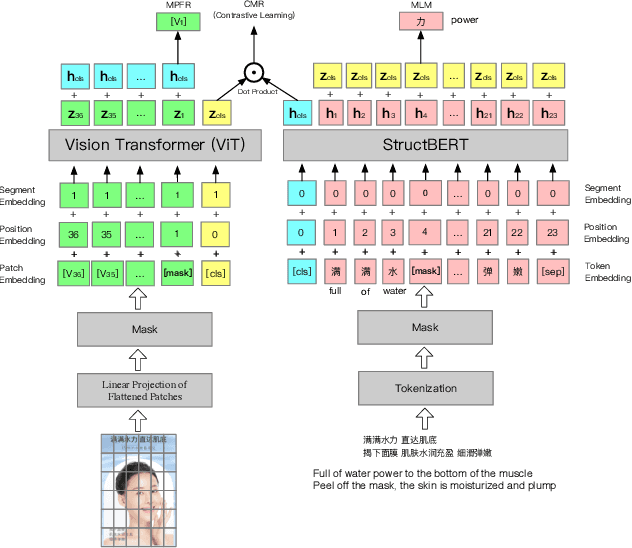
Live streaming is becoming an increasingly popular trend of sales in E-commerce. The core of live-streaming sales is to encourage customers to purchase in an online broadcasting room. To enable customers to better understand a product without jumping out, we propose AliMe MKG, a multi-modal knowledge graph that aims at providing a cognitive profile for products, through which customers are able to seek information about and understand a product. Based on the MKG, we build an online live assistant that highlights product search, product exhibition and question answering, allowing customers to skim over item list, view item details, and ask item-related questions. Our system has been launched online in the Taobao app, and currently serves hundreds of thousands of customers per day.
REPT: Bridging Language Models and Machine Reading Comprehension via Retrieval-Based Pre-training
May 18, 2021
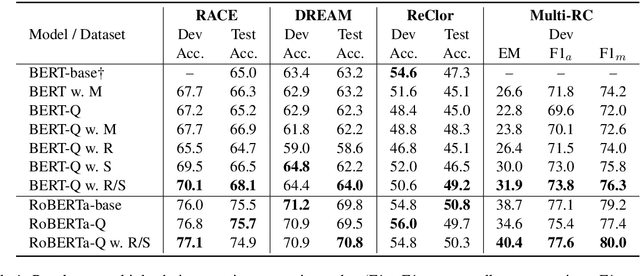
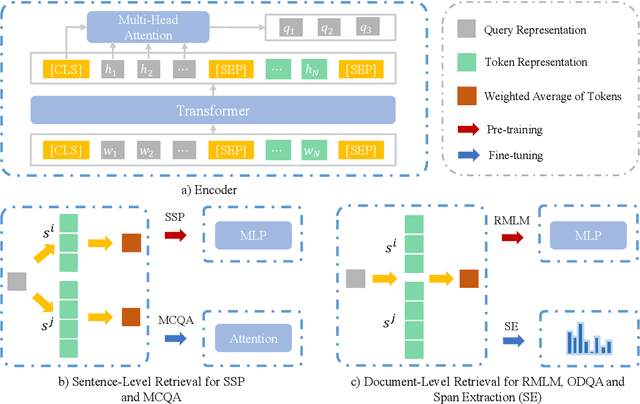
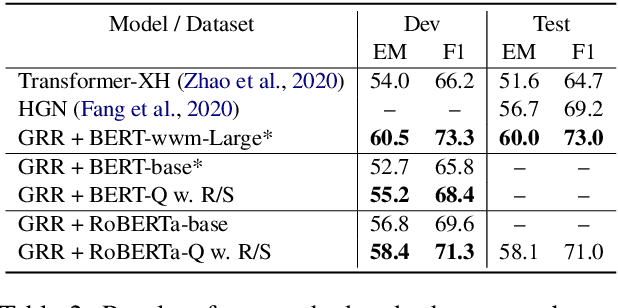
Pre-trained Language Models (PLMs) have achieved great success on Machine Reading Comprehension (MRC) over the past few years. Although the general language representation learned from large-scale corpora does benefit MRC, the poor support in evidence extraction which requires reasoning across multiple sentences hinders PLMs from further advancing MRC. To bridge the gap between general PLMs and MRC, we present REPT, a REtrieval-based Pre-Training approach. In particular, we introduce two self-supervised tasks to strengthen evidence extraction during pre-training, which is further inherited by downstream MRC tasks through the consistent retrieval operation and model architecture. To evaluate our proposed method, we conduct extensive experiments on five MRC datasets that require collecting evidence from and reasoning across multiple sentences. Experimental results demonstrate the effectiveness of our pre-training approach. Moreover, further analysis shows that our approach is able to enhance the capacity of evidence extraction without explicit supervision.
AliMe KG: Domain Knowledge Graph Construction and Application in E-commerce
Sep 24, 2020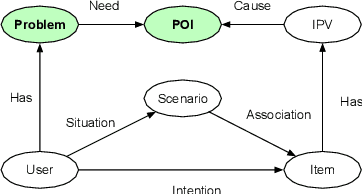
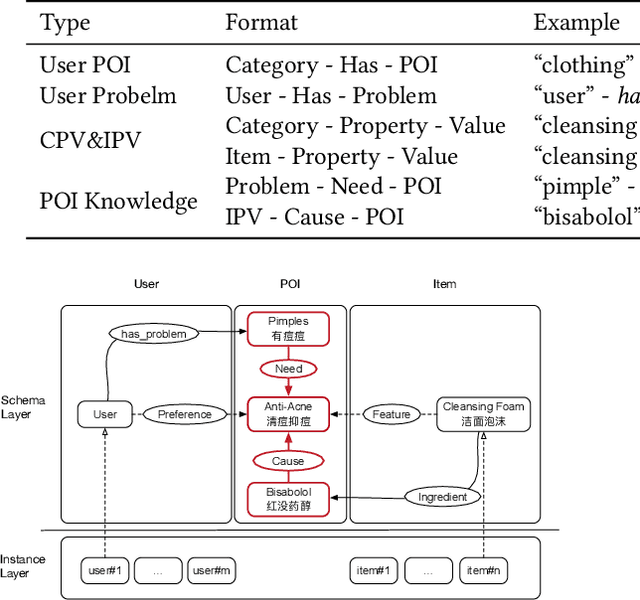
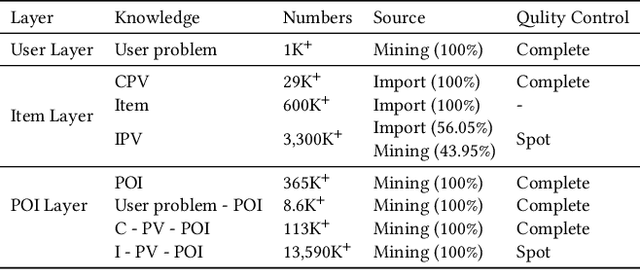
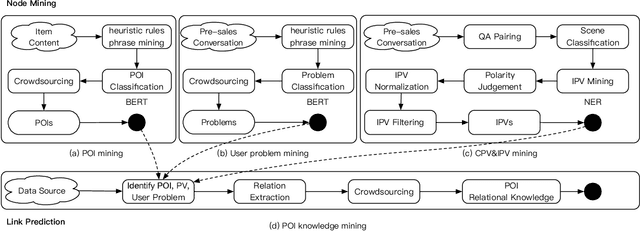
Pre-sales customer service is of importance to E-commerce platforms as it contributes to optimizing customers' buying process. To better serve users, we propose AliMe KG, a domain knowledge graph in E-commerce that captures user problems, points of interests (POI), item information and relations thereof. It helps to understand user needs, answer pre-sales questions and generate explanation texts. We applied AliMe KG to several online business scenarios such as shopping guide, question answering over properties and recommendation reason generation, and gained positive results. In the paper, we systematically introduce how we construct domain knowledge graph from free text, and demonstrate its business value with several applications. Our experience shows that mining structured knowledge from free text in vertical domain is practicable, and can be of substantial value in industrial settings.