 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocialOmni: Benchmarking Audio-Visual Social Interactivity in Omni Models
Mar 17, 2026Omni-modal large language models (OLMs) redefine human-machine interaction by natively integrating audio, vision, and text. However, existing OLM benchmarks remain anchored to static, accuracy-centric tasks, leaving a critical gap in assessing social interactivity, the fundamental capacity to navigate dynamic cues in natural dialogues. To this end, we propose SocialOmni, a comprehensive benchmark that operationalizes the evaluation of this conversational interactivity across three core dimensions: (i) speaker separation and identification (who is speaking), (ii) interruption timing control (when to interject), and (iii) natural interruption generation (how to phrase the interruption). SocialOmni features 2,000 perception samples and a quality-controlled diagnostic set of 209 interaction-generation instances with strict temporal and contextual constraints, complemented by controlled audio-visual inconsistency scenarios to test model robustness. We benchmarked 12 leading OLMs, which uncovers significant variance in their social-interaction capabilities across models. Furthermore, our analysis reveals a pronounced decoupling between a model's perceptual accuracy and its ability to generate contextually appropriate interruptions, indicating that understanding-centric metrics alone are insufficient to characterize conversational social competence. More encouragingly, these diagnostics from SocialOmni yield actionable signals for bridging the perception-interaction divide in future OLMs.
Event-Anchored Frame Selection for Effective Long-Video Understanding
Mar 01, 2026Massive frame redundancy and limited context window make efficient frame selection crucial for long-video understanding with large vision-language models (LVLMs). Prevailing approaches, however, adopt a flat sampling paradigm which treats the video as an unstructured collection of frames. In this paper, we introduce Event-Anchored Frame Selection (EFS), a hierarchical, event-aware pipeline. Leveraging self-supervised DINO embeddings, EFS first partitions the video stream into visually homogeneous temporal segments, which serve as proxies for semantic events. Within each event, it then selects the most query-relevant frame as an anchor. These anchors act as structural priors that guide a global refinement stage using an adaptive Maximal Marginal Relevance (MMR) scheme. This pipeline ensures the final keyframe set jointly optimizes for event coverage, query relevance, and visual diversity. As a training-free, plug-and-play module, EFS can be seamlessly integrated into off-the-shelf LVLMs, yielding substantial gains on challenging video understanding benchmarks. Specifically, when applied to LLaVA-Video-7B, EFS improves accuracy by 4.7%, 4.9%, and 8.8% on VideoMME, LongVideoBench, and MLVU, respectively.
Wavelet-based Frame Selection by Detecting Semantic Boundary for Long Video Understanding
Feb 28, 2026Frame selection is crucial due to high frame redundancy and limited context windows when applying Large Vision-Language Models (LVLMs) to long videos. Current methods typically select frames with high relevance to a given query, resulting in a disjointed set of frames that disregard the narrative structure of video. In this paper, we introduce Wavelet-based Frame Selection by Detecting Semantic Boundary (WFS-SB), a training-free framework that presents a new perspective: effective video understanding hinges not only on high relevance but, more importantly, on capturing semantic shifts - pivotal moments of narrative change that are essential to comprehending the holistic storyline of video. However, direct detection of abrupt changes in the query-frame similarity signal is often unreliable due to high-frequency noise arising from model uncertainty and transient visual variations. To address this, we leverage the wavelet transform, which provides an ideal solution through its multi-resolution analysis in both time and frequency domains. By applying this transform, we decompose the noisy signal into multiple scales and extract a clean semantic change signal from the coarsest scale. We identify the local extrema of this signal as semantic boundaries, which segment the video into coherent clips. Building on this, WFS-SB comprises a two-stage strategy: first, adaptively allocating a frame budget to each clip based on a composite importance score; and second, within each clip, employing the Maximal Marginal Relevance approach to select a diverse yet relevant set of frames. Extensive experiments show that WFS-SB significantly boosts LVLM performance, e.g., improving accuracy by 5.5% on VideoMME, 9.5% on MLVU, and 6.2% on LongVideoBench, consistently outperforming state-of-the-art methods.
PEAfowl: Perception-Enhanced Multi-View Vision-Language-Action for Bimanual Manipulation
Jan 25, 2026Bimanual manipulation in cluttered scenes requires policies that remain stable under occlusions, viewpoint and scene variations. Existing vision-language-action models often fail to generalize because (i) multi-view features are fused via view-agnostic token concatenation, yielding weak 3D-consistent spatial understanding, and (ii) language is injected as global conditioning, resulting in coarse instruction grounding. In this paper, we introduce PEAfowl, a perception-enhanced multi-view VLA policy for bimanual manipulation. For spatial reasoning, PEAfowl predicts per-token depth distributions, performs differentiable 3D lifting, and aggregates local cross-view neighbors to form geometrically grounded, cross-view consistent representations. For instruction grounding, we propose to replace global conditioning with a Perceiver-style text-aware readout over frozen CLIP visual features, enabling iterative evidence accumulation. To overcome noisy and incomplete commodity depth without adding inference overhead, we apply training-only depth distillation from a pretrained depth teacher to supervise the depth-distribution head, providing perception front-end with geometry-aware priors. On RoboTwin 2.0 under domain-randomized setting, PEAfowl improves the strongest baseline by 23.0 pp in success rate, and real-robot experiments further demonstrate reliable sim-to-real transfer and consistent improvements from depth distillation. Project website: https://peafowlvla.github.io/.
Decide Then Retrieve: A Training-Free Framework with Uncertainty-Guided Triggering and Dual-Path Retrieval
Jan 07, 2026Retrieval-augmented generation (RAG) enhances large language models (LLMs) by incorporating external knowledge, but existing approaches indiscriminately trigger retrieval and rely on single-path evidence construction, often introducing noise and limiting performance gains. In this work, we propose Decide Then Retrieve (DTR), a training-free framework that adaptively determines when retrieval is necessary and how external information should be selected. DTR leverages generation uncertainty to guide retrieval triggering and introduces a dual-path retrieval mechanism with adaptive information selection to better handle sparse and ambiguous queries. Extensive experiments across five open-domain QA benchmarks, multiple model scales, and different retrievers demonstrate that DTR consistently improves EM and F1 over standard RAG and strong retrieval-enhanced baselines, while reducing unnecessary retrievals. The code and data used in this paper are available at https://github.com/ChenWangHKU/DTR.
Low Rank Support Quaternion Matrix Machine
Dec 09, 2025Input features are conventionally represented as vectors, matrices, or third order tensors in the real field, for color image classification. Inspired by the success of quaternion data modeling for color images in image recovery and denoising tasks, we propose a novel classification method for color image classification, named as the Low-rank Support Quaternion Matrix Machine (LSQMM), in which the RGB channels are treated as pure quaternions to effectively preserve the intrinsic coupling relationships among channels via the quaternion algebra. For the purpose of promoting low-rank structures resulting from strongly correlated color channels, a quaternion nuclear norm regularization term, serving as a natural extension of the conventional matrix nuclear norm to the quaternion domain, is added to the hinge loss in our LSQMM model. An Alternating Direction Method of Multipliers (ADMM)-based iterative algorithm is designed to effectively resolve the proposed quaternion optimization model. Experimental results on multiple color image classification datasets demonstrate that our proposed classification approach exhibits advantages in classification accuracy, robustness and computational efficiency, compared to several state-of-the-art methods using support vector machines, support matrix machines, and support tensor machines.
BBox DocVQA: A Large Scale Bounding Box Grounded Dataset for Enhancing Reasoning in Document Visual Question Answer
Nov 19, 2025Document Visual Question Answering (DocVQA) is a fundamental task for multimodal document understanding and a key testbed for vision language reasoning. However, most existing DocVQA datasets are limited to the page level and lack fine grained spatial grounding, constraining the interpretability and reasoning capability of Vision Language Models (VLMs). To address this gap, we introduce BBox DocVQA a large scale, bounding box grounded dataset designed to enhance spatial reasoning and evidence localization in visual documents. We further present an automated construction pipeline, Segment Judge and Generate, which integrates a segment model for region segmentation, a VLM for semantic judgment, and another advanced VLM for question answer generation, followed by human verification for quality assurance. The resulting dataset contains 3.6 K diverse documents and 32 K QA pairs, encompassing single and multi region as well as single and multi page scenarios. Each QA instance is grounded on explicit bounding boxes, enabling fine grained evaluation of spatial semantic alignment. Benchmarking multiple state of the art VLMs (e.g., GPT 5, Qwen2.5 VL, and InternVL) on BBox DocVQA reveals persistent challenges in spatial grounding and reasoning accuracy. Furthermore, fine tuning on BBox DocVQA substantially improves both bounding box localization and answer generation, validating its effectiveness for enhancing the reasoning ability of VLMs. Our dataset and code will be publicly released to advance research on interpretable and spatially grounded vision language reasoning.
SMART: Scalable Multi-Agent Reasoning and Trajectory Planning in Dense Environments
Sep 19, 2025Multi-vehicle trajectory planning is a non-convex problem that becomes increasingly difficult in dense environments due to the rapid growth of collision constraints. Efficient exploration of feasible behaviors and resolution of tight interactions are essential for real-time, large-scale coordination. This paper introduces SMART, Scalable Multi-Agent Reasoning and Trajectory Planning, a hierarchical framework that combines priority-based search with distributed optimization to achieve efficient and feasible multi-vehicle planning. The upper layer explores diverse interaction modes using reinforcement learning-based priority estimation and large-step hybrid A* search, while the lower layer refines solutions via parallelizable convex optimization. By partitioning space among neighboring vehicles and constructing robust feasible corridors, the method decouples the joint non-convex problem into convex subproblems solved efficiently in parallel. This design alleviates the step-size trade-off while ensuring kinematic feasibility and collision avoidance. Experiments show that SMART consistently outperforms baselines. On 50 m x 50 m maps, it sustains over 90% success within 1 s up to 25 vehicles, while baselines often drop below 50%. On 100 m x 100 m maps, SMART achieves above 95% success up to 50 vehicles and remains feasible up to 90 vehicles, with runtimes more than an order of magnitude faster than optimization-only approaches. Built on vehicle-to-everything communication, SMART incorporates vehicle-infrastructure cooperation through roadside sensing and agent coordination, improving scalability and safety. Real-world experiments further validate this design, achieving planning times as low as 0.014 s while preserving cooperative behaviors.
PAIRS: Parametric-Verified Adaptive Information Retrieval and Selection for Efficient RAG
Aug 06, 2025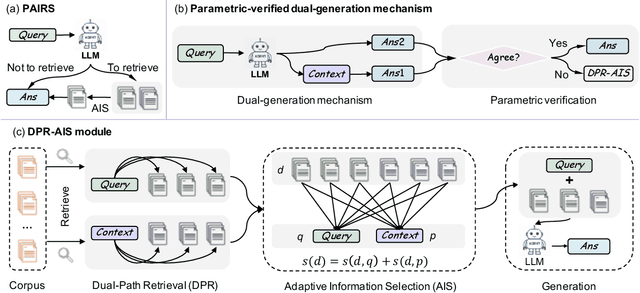
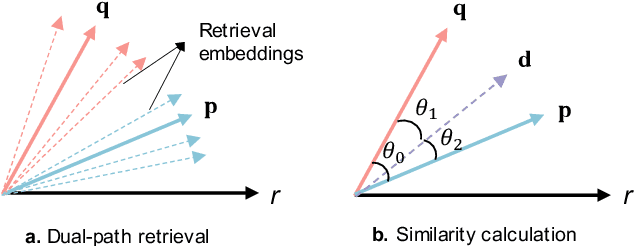
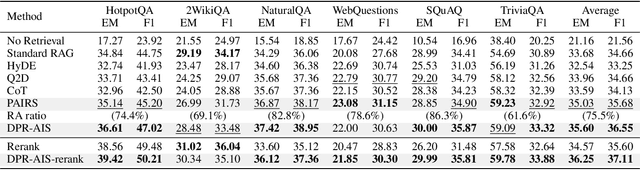
Retrieval-Augmented Generation (RAG) has become a cornerstone technique for enhancing large language models (LLMs) with external knowledge. However, current RAG systems face two critical limitations: (1) they inefficiently retrieve information for every query, including simple questions that could be resolved using the LLM's parametric knowledge alone, and (2) they risk retrieving irrelevant documents when queries contain sparse information signals. To address these gaps, we introduce Parametric-verified Adaptive Information Retrieval and Selection (PAIRS), a training-free framework that integrates parametric and retrieved knowledge to adaptively determine whether to retrieve and how to select external information. Specifically, PAIRS employs a dual-path generation mechanism: First, the LLM produces both a direct answer and a context-augmented answer using self-generated pseudo-context. When these outputs converge, PAIRS bypasses external retrieval entirely, dramatically improving the RAG system's efficiency. For divergent cases, PAIRS activates a dual-path retrieval (DPR) process guided by both the original query and self-generated contextual signals, followed by an Adaptive Information Selection (AIS) module that filters documents through weighted similarity to both sources. This simple yet effective approach can not only enhance efficiency by eliminating unnecessary retrievals but also improve accuracy through contextually guided retrieval and adaptive information selection. Experimental results on six question-answering (QA) benchmarks show that PAIRS reduces retrieval costs by around 25% (triggering for only 75% of queries) while still improving accuracy-achieving +1.1% EM and +1.0% F1 over prior baselines on average.
SCOPE: Compress Mathematical Reasoning Steps for Efficient Automated Process Annotation
May 20, 2025



Process Reward Models (PRMs) have demonstrated promising results in mathematical reasoning, but existing process annotation approaches, whether through human annotations or Monte Carlo simulations, remain computationally expensive. In this paper, we introduce Step COmpression for Process Estimation (SCOPE), a novel compression-based approach that significantly reduces annotation costs. We first translate natural language reasoning steps into code and normalize them through Abstract Syntax Tree, then merge equivalent steps to construct a prefix tree. Unlike simulation-based methods that waste numerous samples on estimation, SCOPE leverages a compression-based prefix tree where each root-to-leaf path serves as a training sample, reducing the complexity from $O(NMK)$ to $O(N)$. We construct a large-scale dataset containing 196K samples with only 5% of the computational resources required by previous methods. Empirical results demonstrate that PRMs trained on our dataset consistently outperform existing automated annotation approaches on both Best-of-N strategy and ProcessBench.