 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDIM sampling for Generative AIBIM, a faster intelligent structural design framework
Dec 30, 2024


Generative AIBIM, a successful structural design pipeline, has proven its ability to intelligently generate high-quality, diverse, and creative shear wall designs that are tailored to specific physical conditions. However, the current module of Generative AIBIM that generates designs, known as the physics-based conditional diffusion model (PCDM), necessitates 1000 iterations for each generation due to its reliance on the denoising diffusion probabilistic model (DDPM) sampling process. This leads to a time-consuming and computationally demanding generation process. To address this issue, this study introduces the denoising diffusion implicit model (DDIM), an accelerated generation method that replaces the DDPM sampling process in PCDM. While the original DDIM was designed for DDPM and the optimization process of PCDM differs from that of DDPM, this paper designs "DDIM sampling for PCDM," which modifies the original DDIM formulations to adapt to the optimization process of PCDM. Experimental results demonstrate that DDIM sampling for PCDM can accelerate the generation process of the original PCDM by a factor of 100 while maintaining the same visual quality in the generated results. This study effectively showcases the effectiveness of DDIM sampling for PCDM in expediting intelligent structural design. Furthermore, this paper reorganizes the contents of DDIM, focusing on the practical usage of DDIM. This change is particularly meaningful for researchers who may not possess a strong background in machine learning theory but are interested in utilizing the tool effectively.
Mamba meets crack segmentation
Jul 22, 2024



Cracks pose safety risks to infrastructure and cannot be overlooked. The prevailing structures in existing crack segmentation networks predominantly consist of CNNs or Transformers. However, CNNs exhibit a deficiency in global modeling capability, hindering the representation to entire crack features. Transformers can capture long-range dependencies but suffer from high and quadratic complexity. Recently, Mamba has garnered extensive attention due to its linear spatial and computational complexity and its powerful global perception. This study explores the representation capabilities of Mamba to crack features. Specifically, this paper uncovers the connection between Mamba and the attention mechanism, providing a profound insight, an attention perspective, into interpreting Mamba and devising a novel Mamba module following the principles of attention blocks, namely CrackMamba. We compare CrackMamba with the most prominent visual Mamba modules, Vim and Vmamba, on two datasets comprising asphalt pavement and concrete pavement cracks, and steel cracks, respectively. The quantitative results show that CrackMamba stands out as the sole Mamba block consistently enhancing the baseline model's performance across all evaluation measures, while reducing its parameters and computational costs. Moreover, this paper substantiates that Mamba can achieve global receptive fields through both theoretical analysis and visual interpretability. The discoveries of this study offer a dual contribution. First, as a plug-and-play and simple yet effective Mamba module, CrackMamba exhibits immense potential for integration into various crack segmentation models. Second, the proposed innovative Mamba design concept, integrating Mamba with the attention mechanism, holds significant reference value for all Mamba-based computer vision models, not limited to crack segmentation networks, as investigated in this study.
Generative Structural Design Integrating BIM and Diffusion Model
Nov 07, 2023



Intelligent structural design using AI can effectively reduce time overhead and increase efficiency. It has potential to become the new design paradigm in the future to assist and even replace engineers, and so it has become a research hotspot in the academic community. However, current methods have some limitations to be addressed, whether in terms of application scope, visual quality of generated results, or evaluation metrics of results. This study proposes a comprehensive solution. Firstly, we introduce building information modeling (BIM) into intelligent structural design and establishes a structural design pipeline integrating BIM and generative AI, which is a powerful supplement to the previous frameworks that only considered CAD drawings. In order to improve the perceptual quality and details of generations, this study makes 3 contributions. Firstly, in terms of generation framework, inspired by the process of human drawing, a novel 2-stage generation framework is proposed to replace the traditional end-to-end framework to reduce the generation difficulty for AI models. Secondly, in terms of generative AI tools adopted, diffusion models (DMs) are introduced to replace widely used generative adversarial network (GAN)-based models, and a novel physics-based conditional diffusion model (PCDM) is proposed to consider different design prerequisites. Thirdly, in terms of neural networks, an attention block (AB) consisting of a self-attention block (SAB) and a parallel cross-attention block (PCAB) is designed to facilitate cross-domain data fusion. The quantitative and qualitative results demonstrate the powerful generation and representation capabilities of PCDM. Necessary ablation studies are conducted to examine the validity of the methods. This study also shows that DMs have the potential to replace GANs and become the new benchmark for generative problems in civil engineering.
Infrastructure Crack Segmentation: Boundary Guidance Method and Benchmark Dataset
Jun 15, 2023Cracks provide an essential indicator of infrastructure performance degradation, and achieving high-precision pixel-level crack segmentation is an issue of concern. Unlike the common research paradigms that adopt novel artificial intelligence (AI) methods directly, this paper examines the inherent characteristics of cracks so as to introduce boundary features into crack identification and then builds a boundary guidance crack segmentation model (BGCrack) with targeted structures and modules, including a high frequency module, global information modeling module, joint optimization module, etc. Extensive experimental results verify the feasibility of the proposed designs and the effectiveness of the edge information in improving segmentation results. In addition, considering that notable open-source datasets mainly consist of asphalt pavement cracks because of ease of access, there is no standard and widely recognized dataset yet for steel structures, one of the primary structural forms in civil infrastructure. This paper provides a steel crack dataset that establishes a unified and fair benchmark for the identification of steel cracks.
DV-Det: Efficient 3D Point Cloud Object Detection with Dynamic Voxelization
Jul 27, 2021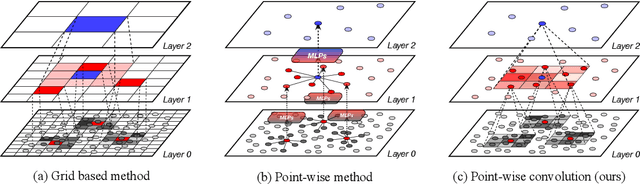
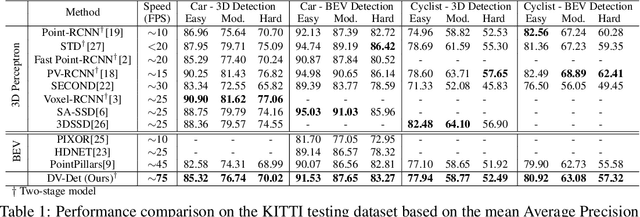
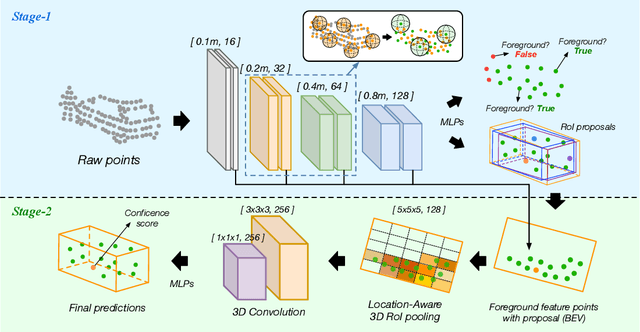

In this work, we propose a novel two-stage framework for the efficient 3D point cloud object detection. Instead of transforming point clouds into 2D bird eye view projections, we parse the raw point cloud data directly in the 3D space yet achieve impressive efficiency and accuracy. To achieve this goal, we propose dynamic voxelization, a method that voxellizes points at local scale on-the-fly. By doing so, we preserve the point cloud geometry with 3D voxels, and therefore waive the dependence on expensive MLPs to learn from point coordinates. On the other hand, we inherently still follow the same processing pattern as point-wise methods (e.g., PointNet) and no longer suffer from the quantization issue like conventional convolutions. For further speed optimization, we propose the grid-based downsampling and voxelization method, and provide different CUDA implementations to accommodate to the discrepant requirements during training and inference phases. We highlight our efficiency on KITTI 3D object detection dataset with 75 FPS and on Waymo Open dataset with 25 FPS inference speed with satisfactory accuracy.
DV-ConvNet: Fully Convolutional Deep Learning on Point Clouds with Dynamic Voxelization and 3D Group Convolution
Sep 07, 2020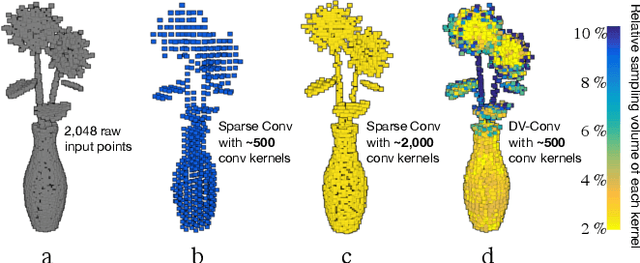
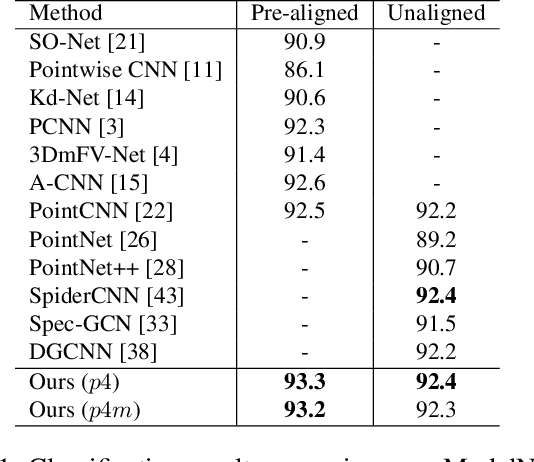
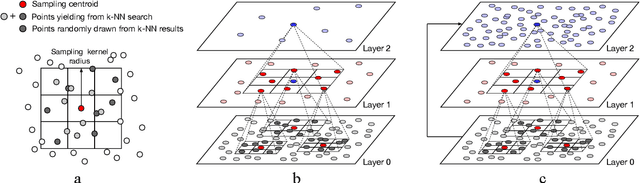
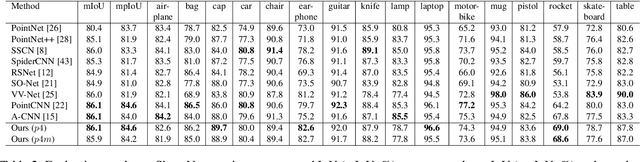
3D point cloud interpretation is a challenging task due to the randomness and sparsity of the component points. Many of the recently proposed methods like PointNet and PointCNN have been focusing on learning shape descriptions from point coordinates as point-wise input features, which usually involves complicated network architectures. In this work, we draw attention back to the standard 3D convolutions towards an efficient 3D point cloud interpretation. Instead of converting the entire point cloud into voxel representations like the other volumetric methods, we voxelize the sub-portions of the point cloud only at necessary locations within each convolution layer on-the-fly, using our dynamic voxelization operation with self-adaptive voxelization resolution. In addition, we incorporate 3D group convolution into our dense convolution kernel implementation to further exploit the rotation invariant features of point cloud. Benefiting from its simple fully-convolutional architecture, our network is able to run and converge at a considerably fast speed, while yields on-par or even better performance compared with the state-of-the-art methods on several benchmark datasets.
Is Discriminator a Good Feature Extractor?
Jan 03, 2020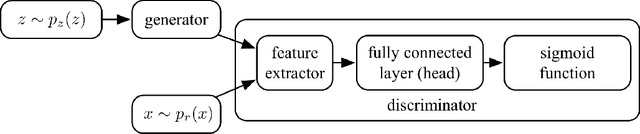
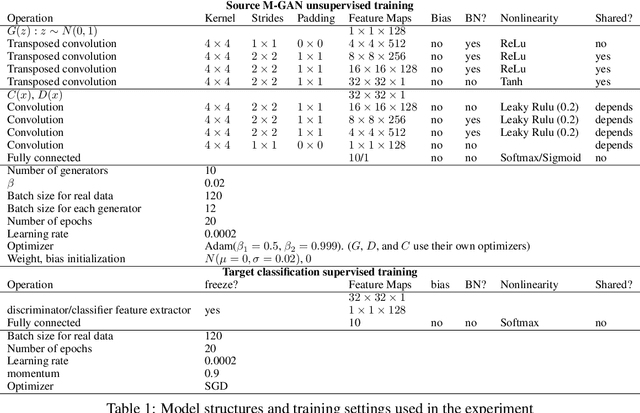
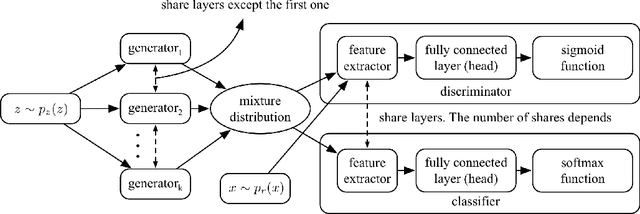

The discriminator from generative adversarial nets (GAN) has been used by researchers as a feature extractor in transfer learning and appeared worked well. However, there are also studies that believe this is the wrong research direction because intuitively the task of the discriminator focuses on separating the real samples from the generated ones, making features extracted in this way useless for most of the downstream tasks. To avoid this dilemma, we first conducted a thorough theoretical analysis of the relationship between the discriminator task and the features extracted. We found that the connection between the task of the discriminator and the feature is not as strong as was thought, for that the main factor restricting the feature learned by the discriminator is not the task, but is the need to prevent the entire GAN model from mode collapse during the training. From this perspective and combined with further analyses, we found that to avoid mode collapse, the features extracted by the discriminator are not guided to be different for the real samples, but divergence without noise is indeed allowed and occupies a large proportion of the feature space. This makes the features more robust and helps answer the question as to why the discriminator can succeed as a feature extractor in related research. Consequently, to expose the essence of the discriminator extractor as different from other extractors, we analyze the counterpart of the discriminator extractor, the classifier extractor that assigns the target samples to different categories. We found the performance of the discriminator extractor may be inferior to the classifier based extractor when the source classification task is similar to the target task, which is the common case, but the ability to avoid noise prevents the discriminator from being replaced by the classifier.