 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDV-Det: Efficient 3D Point Cloud Object Detection with Dynamic Voxelization
Jul 27, 2021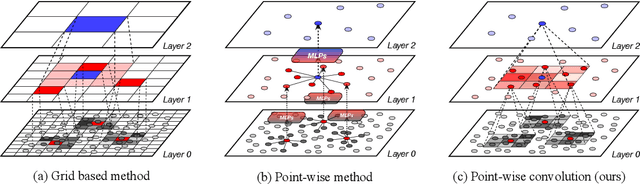
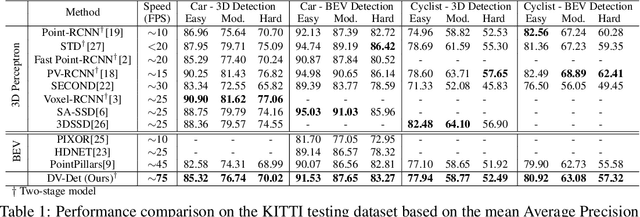
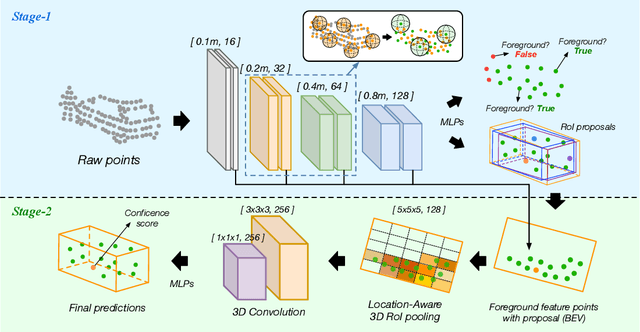

In this work, we propose a novel two-stage framework for the efficient 3D point cloud object detection. Instead of transforming point clouds into 2D bird eye view projections, we parse the raw point cloud data directly in the 3D space yet achieve impressive efficiency and accuracy. To achieve this goal, we propose dynamic voxelization, a method that voxellizes points at local scale on-the-fly. By doing so, we preserve the point cloud geometry with 3D voxels, and therefore waive the dependence on expensive MLPs to learn from point coordinates. On the other hand, we inherently still follow the same processing pattern as point-wise methods (e.g., PointNet) and no longer suffer from the quantization issue like conventional convolutions. For further speed optimization, we propose the grid-based downsampling and voxelization method, and provide different CUDA implementations to accommodate to the discrepant requirements during training and inference phases. We highlight our efficiency on KITTI 3D object detection dataset with 75 FPS and on Waymo Open dataset with 25 FPS inference speed with satisfactory accuracy.
DV-ConvNet: Fully Convolutional Deep Learning on Point Clouds with Dynamic Voxelization and 3D Group Convolution
Sep 07, 2020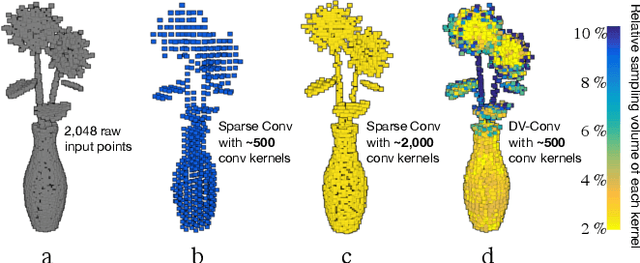
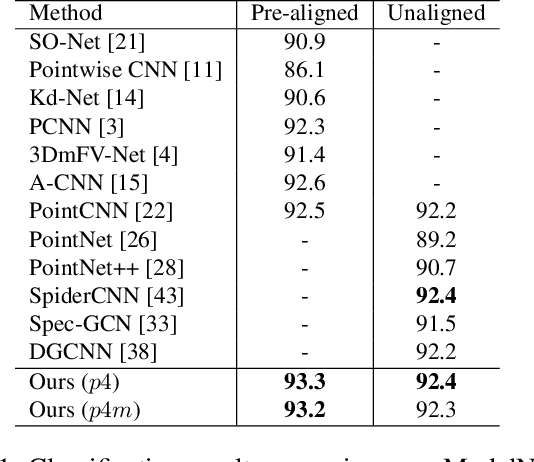
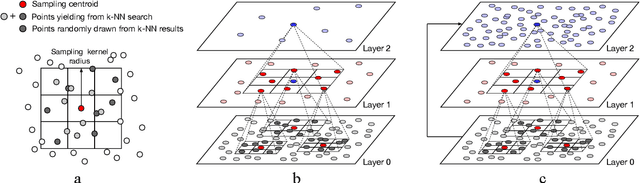
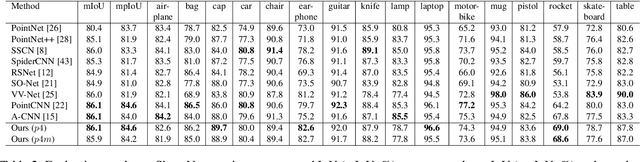
3D point cloud interpretation is a challenging task due to the randomness and sparsity of the component points. Many of the recently proposed methods like PointNet and PointCNN have been focusing on learning shape descriptions from point coordinates as point-wise input features, which usually involves complicated network architectures. In this work, we draw attention back to the standard 3D convolutions towards an efficient 3D point cloud interpretation. Instead of converting the entire point cloud into voxel representations like the other volumetric methods, we voxelize the sub-portions of the point cloud only at necessary locations within each convolution layer on-the-fly, using our dynamic voxelization operation with self-adaptive voxelization resolution. In addition, we incorporate 3D group convolution into our dense convolution kernel implementation to further exploit the rotation invariant features of point cloud. Benefiting from its simple fully-convolutional architecture, our network is able to run and converge at a considerably fast speed, while yields on-par or even better performance compared with the state-of-the-art methods on several benchmark datasets.
Is Discriminator a Good Feature Extractor?
Jan 03, 2020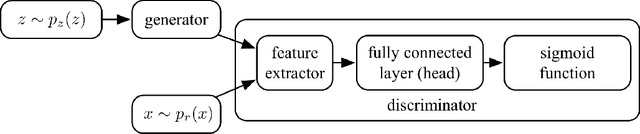
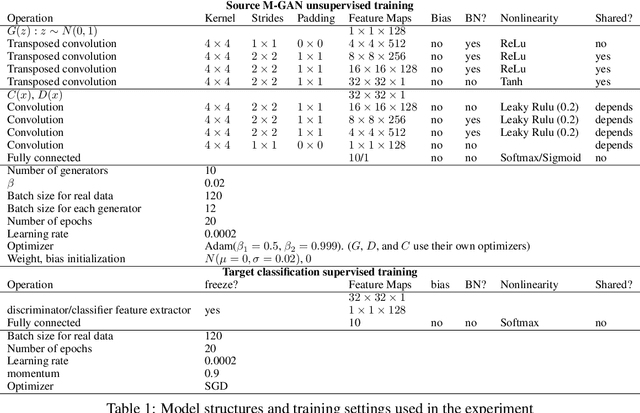
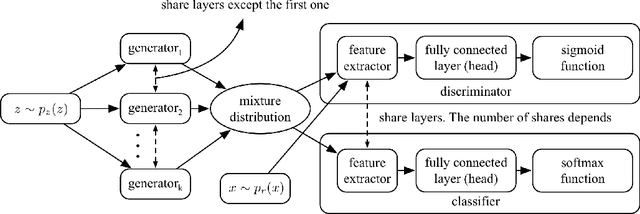

The discriminator from generative adversarial nets (GAN) has been used by researchers as a feature extractor in transfer learning and appeared worked well. However, there are also studies that believe this is the wrong research direction because intuitively the task of the discriminator focuses on separating the real samples from the generated ones, making features extracted in this way useless for most of the downstream tasks. To avoid this dilemma, we first conducted a thorough theoretical analysis of the relationship between the discriminator task and the features extracted. We found that the connection between the task of the discriminator and the feature is not as strong as was thought, for that the main factor restricting the feature learned by the discriminator is not the task, but is the need to prevent the entire GAN model from mode collapse during the training. From this perspective and combined with further analyses, we found that to avoid mode collapse, the features extracted by the discriminator are not guided to be different for the real samples, but divergence without noise is indeed allowed and occupies a large proportion of the feature space. This makes the features more robust and helps answer the question as to why the discriminator can succeed as a feature extractor in related research. Consequently, to expose the essence of the discriminator extractor as different from other extractors, we analyze the counterpart of the discriminator extractor, the classifier extractor that assigns the target samples to different categories. We found the performance of the discriminator extractor may be inferior to the classifier based extractor when the source classification task is similar to the target task, which is the common case, but the ability to avoid noise prevents the discriminator from being replaced by the classifier.