 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Skewness-Based Criterion for Addressing Heteroscedastic Noise in Causal Discovery
Oct 08, 2024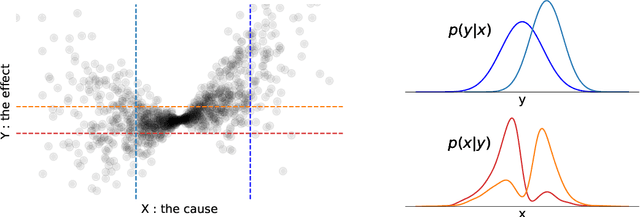

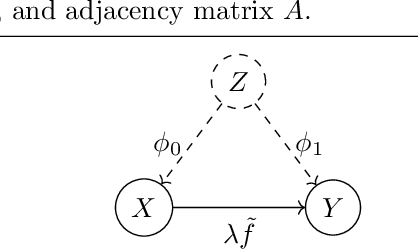

Real-world data often violates the equal-variance assumption (homoscedasticity), making it essential to account for heteroscedastic noise in causal discovery. In this work, we explore heteroscedastic symmetric noise models (HSNMs), where the effect $Y$ is modeled as $Y = f(X) + \sigma(X)N$, with $X$ as the cause and $N$ as independent noise following a symmetric distribution. We introduce a novel criterion for identifying HSNMs based on the skewness of the score (i.e., the gradient of the log density) of the data distribution. This criterion establishes a computationally tractable measurement that is zero in the causal direction but nonzero in the anticausal direction, enabling the causal direction discovery. We extend this skewness-based criterion to the multivariate setting and propose SkewScore, an algorithm that handles heteroscedastic noise without requiring the extraction of exogenous noise. We also conduct a case study on the robustness of SkewScore in a bivariate model with a latent confounder, providing theoretical insights into its performance. Empirical studies further validate the effectiveness of the proposed method.
VSFormer: Mining Correlations in Flexible View Set for Multi-view 3D Shape Understanding
Sep 14, 2024



View-based methods have demonstrated promising performance in 3D shape understanding. However, they tend to make strong assumptions about the relations between views or learn the multi-view correlations indirectly, which limits the flexibility of exploring inter-view correlations and the effectiveness of target tasks. To overcome the above problems, this paper investigates flexible organization and explicit correlation learning for multiple views. In particular, we propose to incorporate different views of a 3D shape into a permutation-invariant set, referred to as \emph{View Set}, which removes rigid relation assumptions and facilitates adequate information exchange and fusion among views. Based on that, we devise a nimble Transformer model, named \emph{VSFormer}, to explicitly capture pairwise and higher-order correlations of all elements in the set. Meanwhile, we theoretically reveal a natural correspondence between the Cartesian product of a view set and the correlation matrix in the attention mechanism, which supports our model design. Comprehensive experiments suggest that VSFormer has better flexibility, efficient inference efficiency and superior performance. Notably, VSFormer reaches state-of-the-art results on various 3d recognition datasets, including ModelNet40, ScanObjectNN and RGBD. It also establishes new records on the SHREC'17 retrieval benchmark. The code and datasets are available at \url{https://github.com/auniquesun/VSFormer}.
Parameter-efficient Prompt Learning for 3D Point Cloud Understanding
Feb 24, 2024This paper presents a parameter-efficient prompt tuning method, named PPT, to adapt a large multi-modal model for 3D point cloud understanding. Existing strategies are quite expensive in computation and storage, and depend on time-consuming prompt engineering. We address the problems from three aspects. Firstly, a PromptLearner module is devised to replace hand-crafted prompts with learnable contexts to automate the prompt tuning process. Then, we lock the pre-trained backbone instead of adopting the full fine-tuning paradigm to substantially improve the parameter efficiency. Finally, a lightweight PointAdapter module is arranged near target tasks to enhance prompt tuning for 3D point cloud understanding. Comprehensive experiments are conducted to demonstrate the superior parameter and data efficiency of the proposed method.Meanwhile, we obtain new records on 4 public datasets and multiple 3D tasks, i.e., point cloud recognition, few-shot learning, and part segmentation. The implementation is available at https://github.com/auniquesun/PPT.
Graph-Skeleton: ~1% Nodes are Sufficient to Represent Billion-Scale Graph
Feb 14, 2024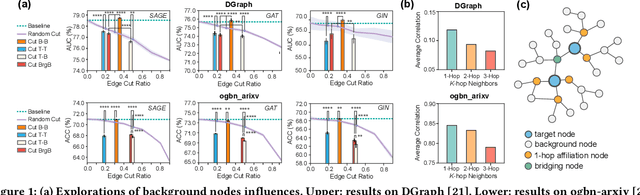
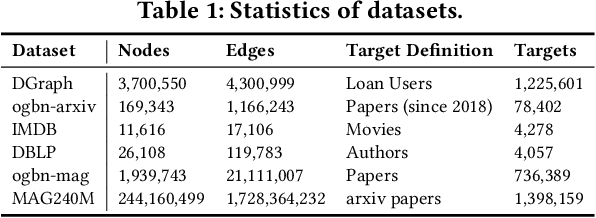
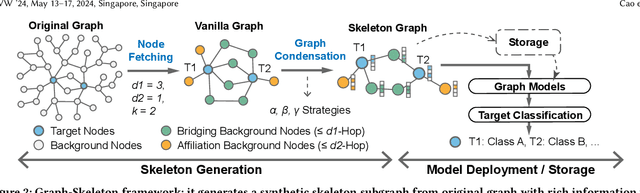
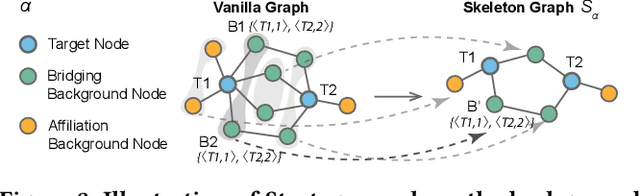
Due to the ubiquity of graph data on the web, web graph mining has become a hot research spot. Nonetheless, the prevalence of large-scale web graphs in real applications poses significant challenges to storage, computational capacity and graph model design. Despite numerous studies to enhance the scalability of graph models, a noticeable gap remains between academic research and practical web graph mining applications. One major cause is that in most industrial scenarios, only a small part of nodes in a web graph are actually required to be analyzed, where we term these nodes as target nodes, while others as background nodes. In this paper, we argue that properly fetching and condensing the background nodes from massive web graph data might be a more economical shortcut to tackle the obstacles fundamentally. To this end, we make the first attempt to study the problem of massive background nodes compression for target nodes classification. Through extensive experiments, we reveal two critical roles played by the background nodes in target node classification: enhancing structural connectivity between target nodes, and feature correlation with target nodes. Followingthis, we propose a novel Graph-Skeleton1 model, which properly fetches the background nodes, and further condenses the semantic and topological information of background nodes within similar target-background local structures. Extensive experiments on various web graph datasets demonstrate the effectiveness and efficiency of the proposed method. In particular, for MAG240M dataset with 0.24 billion nodes, our generated skeleton graph achieves highly comparable performance while only containing 1.8% nodes of the original graph.
Accelerating Dynamic Network Embedding with Billions of Parameter Updates to Milliseconds
Jun 15, 2023
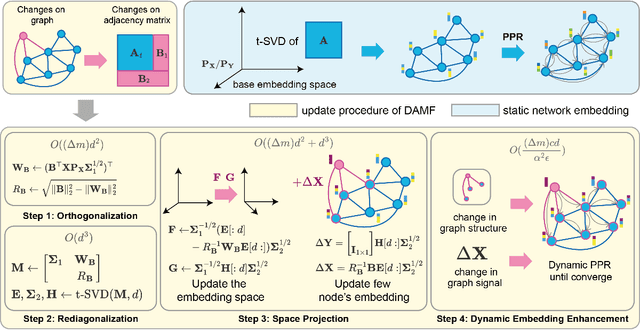
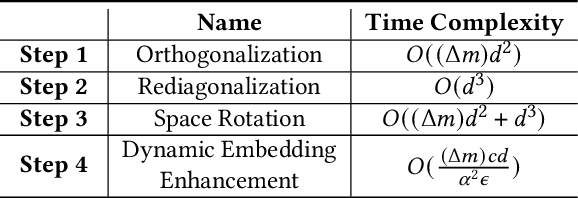
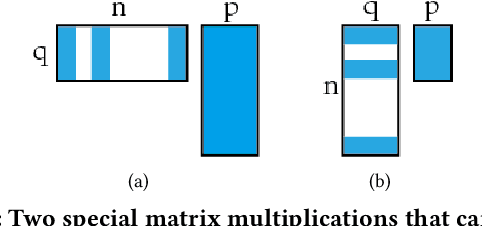
Network embedding, a graph representation learning method illustrating network topology by mapping nodes into lower-dimension vectors, is challenging to accommodate the ever-changing dynamic graphs in practice. Existing research is mainly based on node-by-node embedding modifications, which falls into the dilemma of efficient calculation and accuracy. Observing that the embedding dimensions are usually much smaller than the number of nodes, we break this dilemma with a novel dynamic network embedding paradigm that rotates and scales the axes of embedding space instead of a node-by-node update. Specifically, we propose the Dynamic Adjacency Matrix Factorization (DAMF) algorithm, which achieves an efficient and accurate dynamic network embedding by rotating and scaling the coordinate system where the network embedding resides with no more than the number of edge modifications changes of node embeddings. Moreover, a dynamic Personalized PageRank is applied to the obtained network embeddings to enhance node embeddings and capture higher-order neighbor information dynamically. Experiments of node classification, link prediction, and graph reconstruction on different-sized dynamic graphs suggest that DAMF advances dynamic network embedding. Further, we unprecedentedly expand dynamic network embedding experiments to billion-edge graphs, where DAMF updates billion-level parameters in less than 10ms.
Relational Learning between Multiple Pulmonary Nodules via Deep Set Attention Transformers
Apr 12, 2020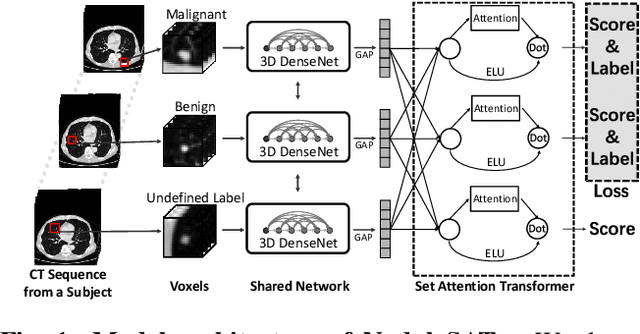


Diagnosis and treatment of multiple pulmonary nodules are clinically important but challenging. Prior studies on nodule characterization use solitary-nodule approaches on multiple nodular patients, which ignores the relations between nodules. In this study, we propose a multiple instance learning (MIL) approach and empirically prove the benefit to learn the relations between multiple nodules. By treating the multiple nodules from a same patient as a whole, critical relational information between solitary-nodule voxels is extracted. To our knowledge, it is the first study to learn the relations between multiple pulmonary nodules. Inspired by recent advances in natural language processing (NLP) domain, we introduce a self-attention transformer equipped with 3D CNN, named {NoduleSAT}, to replace typical pooling-based aggregation in multiple instance learning. Extensive experiments on lung nodule false positive reduction on LUNA16 database, and malignancy classification on LIDC-IDRI database, validate the effectiveness of the proposed method.
Evaluating and Boosting Uncertainty Quantification in Classification
Sep 16, 2019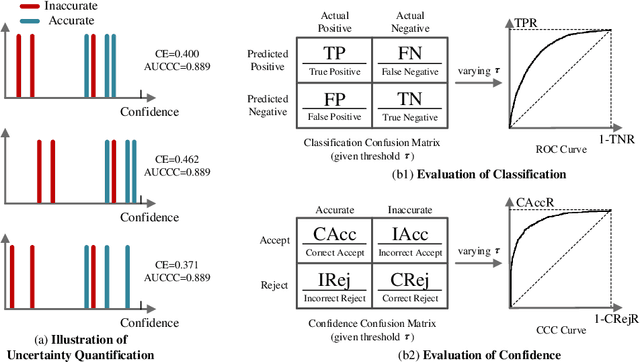

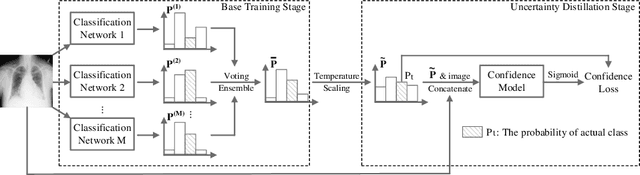

Emergence of artificial intelligence techniques in biomedical applications urges the researchers to pay more attention on the uncertainty quantification (UQ) in machine-assisted medical decision making. For classification tasks, prior studies on UQ are difficult to compare with each other, due to the lack of a unified quantitative evaluation metric. Considering that well-performing UQ models ought to know when the classification models act incorrectly, we design a new evaluation metric, area under Confidence-Classification Characteristic curves (AUCCC), to quantitatively evaluate the performance of the UQ models. AUCCC is threshold-free, robust to perturbation, and insensitive to the classification performance. We evaluate several UQ methods (e.g., max softmax output) with AUCCC to validate its effectiveness. Furthermore, a simple scheme, named Uncertainty Distillation (UDist), is developed to boost the UQ performance, where a confidence model is distilling the confidence estimated by deep ensembles. The proposed method is easy to implement; it consistently outperforms strong baselines on natural and medical image datasets in our experiments.
Exploiting Channel Similarity for Accelerating Deep Convolutional Neural Networks
Aug 06, 2019



To address the limitations of existing magnitude-based pruning algorithms in cases where model weights or activations are of large and similar magnitude, we propose a novel perspective to discover parameter redundancy among channels and accelerate deep CNNs via channel pruning. Precisely, we argue that channels revealing similar feature information have functional overlap and that most channels within each such similarity group can be removed without compromising model's representational power. After deriving an effective metric for evaluating channel similarity through probabilistic modeling, we introduce a pruning algorithm via hierarchical clustering of channels. In particular, the proposed algorithm does not rely on sparsity training techniques or complex data-driven optimization and can be directly applied to pre-trained models. Extensive experiments on benchmark datasets strongly demonstrate the superior acceleration performance of our approach over prior arts. On ImageNet, our pruned ResNet-50 with 30% FLOPs reduced outperforms the baseline model.