 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation-Agnostic Shape Fields
Mar 19, 2022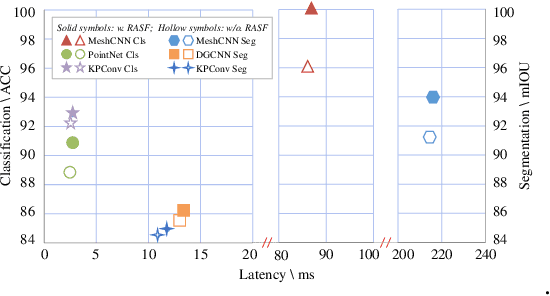
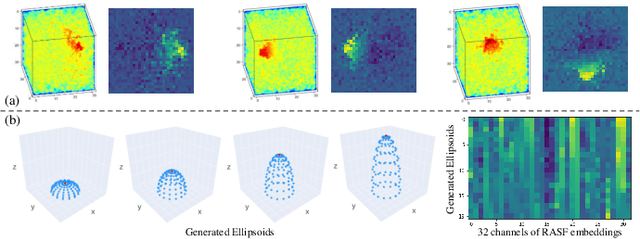
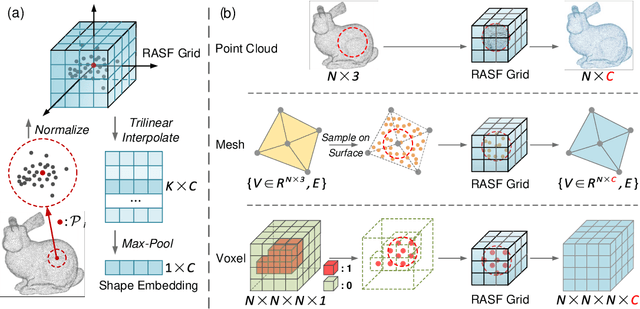

3D shape analysis has been widely explored in the era of deep learning. Numerous models have been developed for various 3D data representation formats, e.g., MeshCNN for meshes, PointNet for point clouds and VoxNet for voxels. In this study, we present Representation-Agnostic Shape Fields (RASF), a generalizable and computation-efficient shape embedding module for 3D deep learning. RASF is implemented with a learnable 3D grid with multiple channels to store local geometry. Based on RASF, shape embeddings for various 3D shape representations (point clouds, meshes and voxels) are retrieved by coordinate indexing. While there are multiple ways to optimize the learnable parameters of RASF, we provide two effective schemes among all in this paper for RASF pre-training: shape reconstruction and normal estimation. Once trained, RASF becomes a plug-and-play performance booster with negligible cost. Extensive experiments on diverse 3D representation formats, networks and applications, validate the universal effectiveness of the proposed RASF. Code and pre-trained models are publicly available https://github.com/seanywang0408/RASF
* The Tenth International Conference on Learning Representations (ICLR 2022). Code is available at https://github.com/seanywang0408/RASF
3D Human Action Representation Learning via Cross-View Consistency Pursuit
May 01, 2021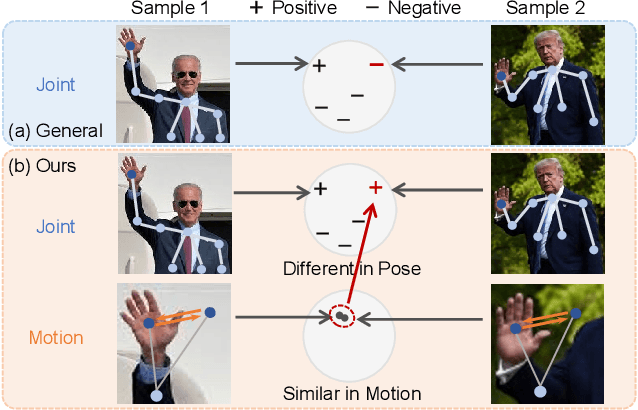
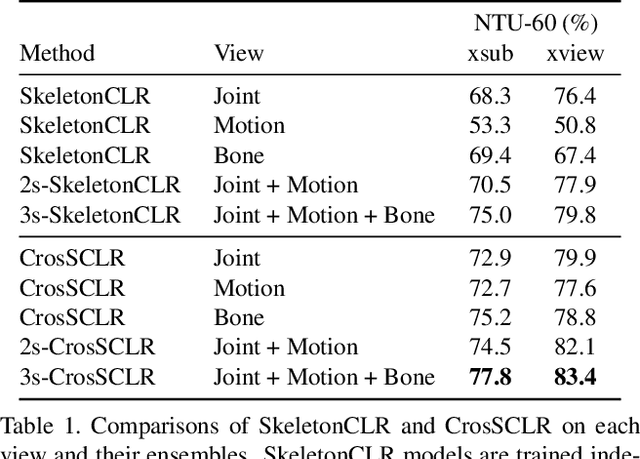
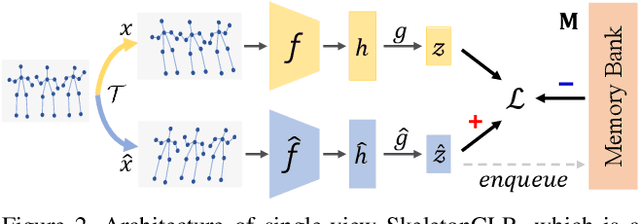
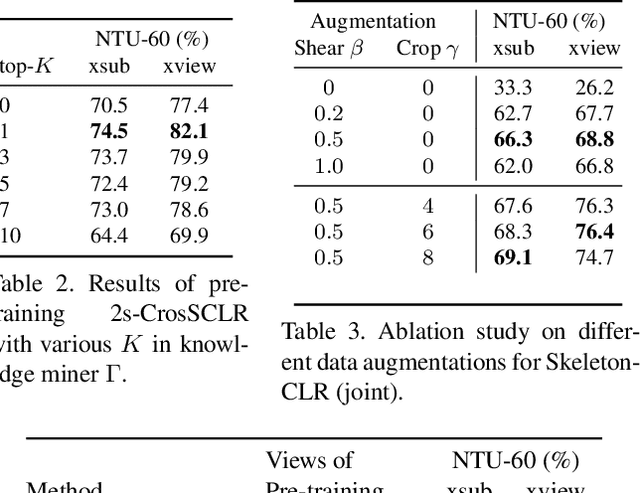
In this work, we propose a Cross-view Contrastive Learning framework for unsupervised 3D skeleton-based action Representation (CrosSCLR), by leveraging multi-view complementary supervision signal. CrosSCLR consists of both single-view contrastive learning (SkeletonCLR) and cross-view consistent knowledge mining (CVC-KM) modules, integrated in a collaborative learning manner. It is noted that CVC-KM works in such a way that high-confidence positive/negative samples and their distributions are exchanged among views according to their embedding similarity, ensuring cross-view consistency in terms of contrastive context, i.e., similar distributions. Extensive experiments show that CrosSCLR achieves remarkable action recognition results on NTU-60 and NTU-120 datasets under unsupervised settings, with observed higher-quality action representations. Our code is available at https://github.com/LinguoLi/CrosSCLR.
Probabilistic Radiomics: Ambiguous Diagnosis with Controllable Shape Analysis
Oct 20, 2019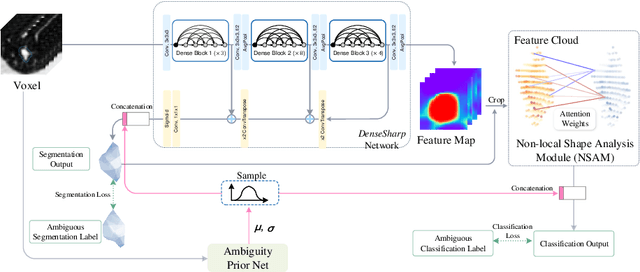
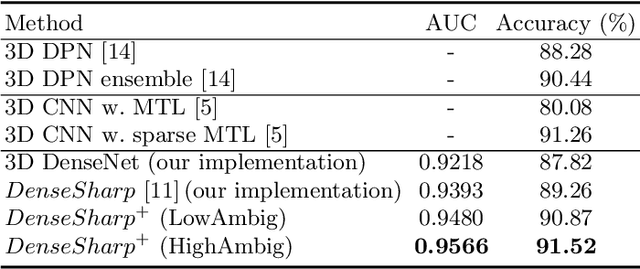
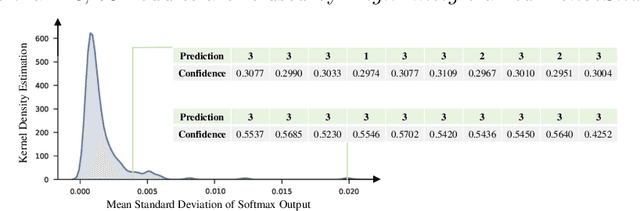
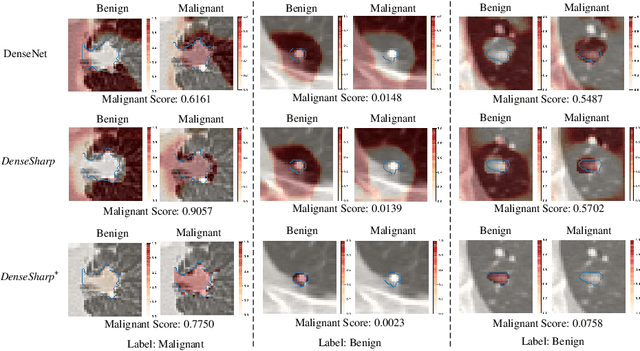
Radiomics analysis has achieved great success in recent years. However, conventional Radiomics analysis suffers from insufficiently expressive hand-crafted features. Recently, emerging deep learning techniques, e.g., convolutional neural networks (CNNs), dominate recent research in Computer-Aided Diagnosis (CADx). Unfortunately, as black-box predictors, we argue that CNNs are "diagnosing" voxels (or pixels), rather than lesions; in other words, visual saliency from a trained CNN is not necessarily concentrated on the lesions. On the other hand, classification in clinical applications suffers from inherent ambiguities: radiologists may produce diverse diagnosis on challenging cases. To this end, we propose a controllable and explainable {\em Probabilistic Radiomics} framework, by combining the Radiomics analysis and probabilistic deep learning. In our framework, 3D CNN feature is extracted upon lesion region only, then encoded into lesion representation, by a controllable Non-local Shape Analysis Module (NSAM) based on self-attention. Inspired from variational auto-encoders (VAEs), an Ambiguity PriorNet is used to approximate the ambiguity distribution over human experts. The final diagnosis is obtained by combining the ambiguity prior sample and lesion representation, and the whole network named $DenseSharp^{+}$ is end-to-end trainable. We apply the proposed method on lung nodule diagnosis on LIDC-IDRI database to validate its effectiveness.
Evaluating and Boosting Uncertainty Quantification in Classification
Sep 16, 2019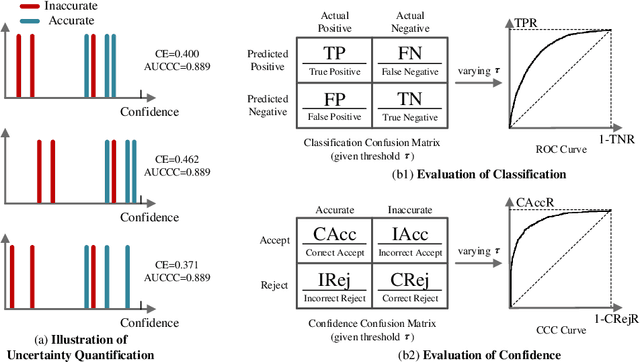

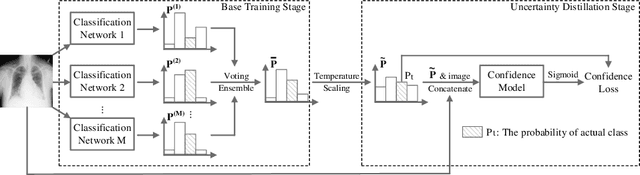

Emergence of artificial intelligence techniques in biomedical applications urges the researchers to pay more attention on the uncertainty quantification (UQ) in machine-assisted medical decision making. For classification tasks, prior studies on UQ are difficult to compare with each other, due to the lack of a unified quantitative evaluation metric. Considering that well-performing UQ models ought to know when the classification models act incorrectly, we design a new evaluation metric, area under Confidence-Classification Characteristic curves (AUCCC), to quantitatively evaluate the performance of the UQ models. AUCCC is threshold-free, robust to perturbation, and insensitive to the classification performance. We evaluate several UQ methods (e.g., max softmax output) with AUCCC to validate its effectiveness. Furthermore, a simple scheme, named Uncertainty Distillation (UDist), is developed to boost the UQ performance, where a confidence model is distilling the confidence estimated by deep ensembles. The proposed method is easy to implement; it consistently outperforms strong baselines on natural and medical image datasets in our experiments.
Modeling Point Clouds with Self-Attention and Gumbel Subset Sampling
Apr 06, 2019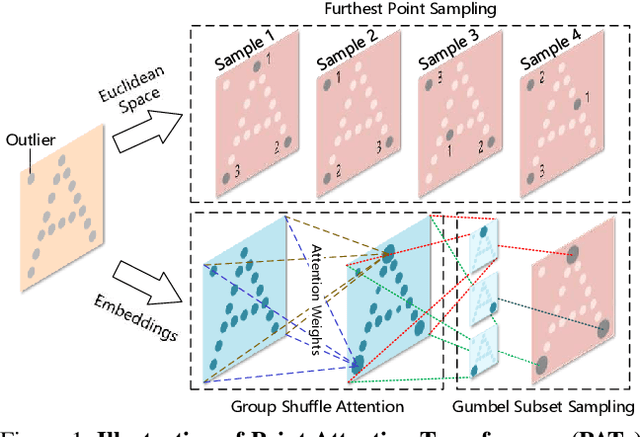
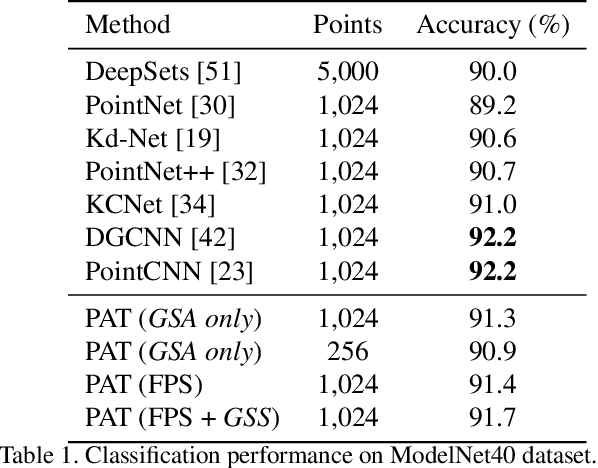
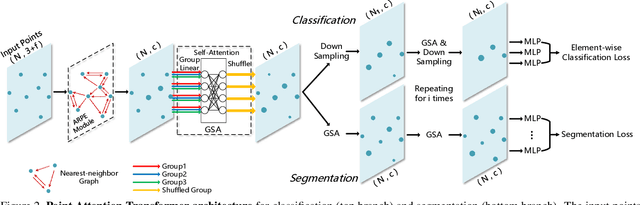
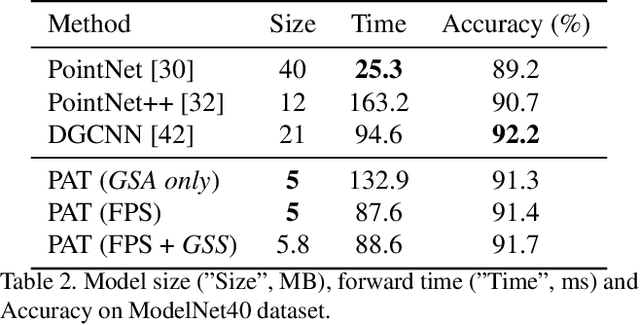
Geometric deep learning is increasingly important thanks to the popularity of 3D sensors. Inspired by the recent advances in NLP domain, the self-attention transformer is introduced to consume the point clouds. We develop Point Attention Transformers (PATs), using a parameter-efficient Group Shuffle Attention (GSA) to replace the costly Multi-Head Attention. We demonstrate its ability to process size-varying inputs, and prove its permutation equivariance. Besides, prior work uses heuristics dependence on the input data (e.g., Furthest Point Sampling) to hierarchically select subsets of input points. Thereby, we for the first time propose an end-to-end learnable and task-agnostic sampling operation, named Gumbel Subset Sampling (GSS), to select a representative subset of input points. Equipped with Gumbel-Softmax, it produces a "soft" continuous subset in training phase, and a "hard" discrete subset in test phase. By selecting representative subsets in a hierarchical fashion, the networks learn a stronger representation of the input sets with lower computation cost. Experiments on classification and segmentation benchmarks show the effectiveness and efficiency of our methods. Furthermore, we propose a novel application, to process event camera stream as point clouds, and achieve a state-of-the-art performance on DVS128 Gesture Dataset.