 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring Fluid Dynamics via Inverse Rendering
Apr 10, 2023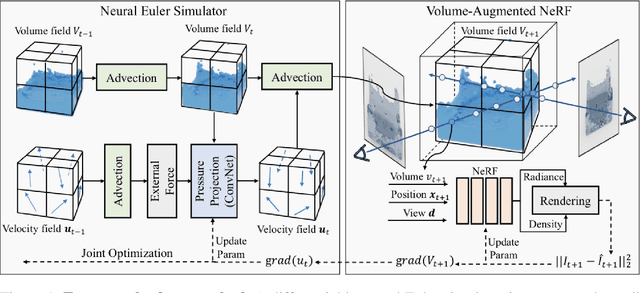


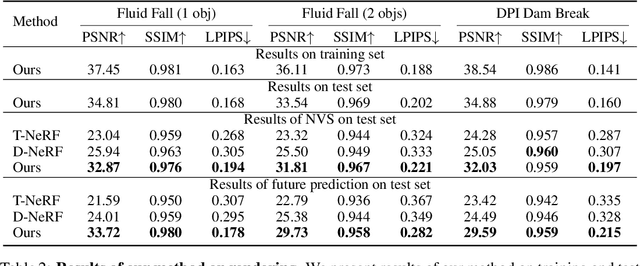
Humans have a strong intuitive understanding of physical processes such as fluid falling by just a glimpse of such a scene picture, i.e., quickly derived from our immersive visual experiences in memory. This work achieves such a photo-to-fluid-dynamics reconstruction functionality learned from unannotated videos, without any supervision of ground-truth fluid dynamics. In a nutshell, a differentiable Euler simulator modeled with a ConvNet-based pressure projection solver, is integrated with a volumetric renderer, supporting end-to-end/coherent differentiable dynamic simulation and rendering. By endowing each sampled point with a fluid volume value, we derive a NeRF-like differentiable renderer dedicated from fluid data; and thanks to this volume-augmented representation, fluid dynamics could be inversely inferred from the error signal between the rendered result and ground-truth video frame (i.e., inverse rendering). Experiments on our generated Fluid Fall datasets and DPI Dam Break dataset are conducted to demonstrate both effectiveness and generalization ability of our method.
AudioEar: Single-View Ear Reconstruction for Personalized Spatial Audio
Jan 30, 2023Spatial audio, which focuses on immersive 3D sound rendering, is widely applied in the acoustic industry. One of the key problems of current spatial audio rendering methods is the lack of personalization based on different anatomies of individuals, which is essential to produce accurate sound source positions. In this work, we address this problem from an interdisciplinary perspective. The rendering of spatial audio is strongly correlated with the 3D shape of human bodies, particularly ears. To this end, we propose to achieve personalized spatial audio by reconstructing 3D human ears with single-view images. First, to benchmark the ear reconstruction task, we introduce AudioEar3D, a high-quality 3D ear dataset consisting of 112 point cloud ear scans with RGB images. To self-supervisedly train a reconstruction model, we further collect a 2D ear dataset composed of 2,000 images, each one with manual annotation of occlusion and 55 landmarks, named AudioEar2D. To our knowledge, both datasets have the largest scale and best quality of their kinds for public use. Further, we propose AudioEarM, a reconstruction method guided by a depth estimation network that is trained on synthetic data, with two loss functions tailored for ear data. Lastly, to fill the gap between the vision and acoustics community, we develop a pipeline to integrate the reconstructed ear mesh with an off-the-shelf 3D human body and simulate a personalized Head-Related Transfer Function (HRTF), which is the core of spatial audio rendering. Code and data are publicly available at https://github.com/seanywang0408/AudioEar.
Self-Prediction for Joint Instance and Semantic Segmentation of Point Clouds
Jul 27, 2020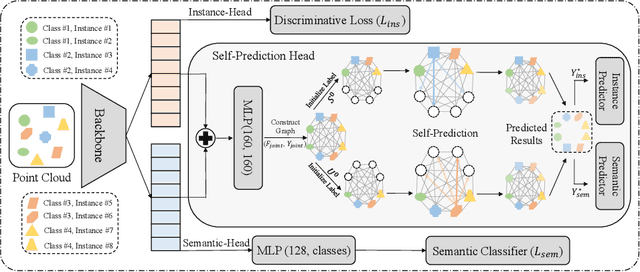
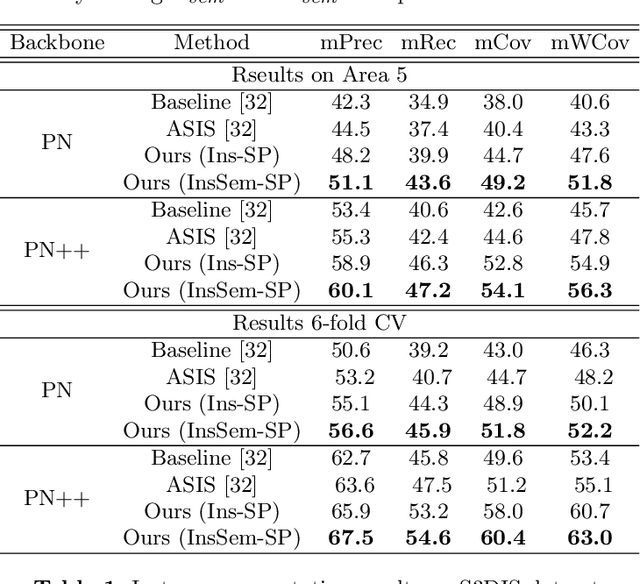
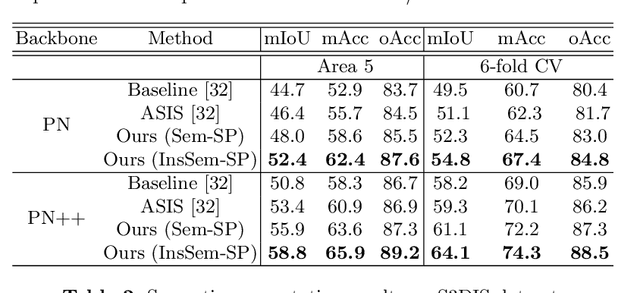
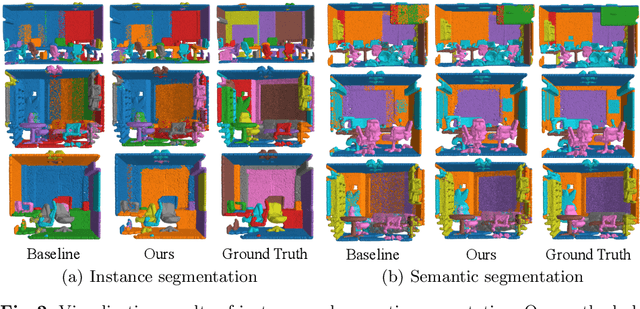
We develop a novel learning scheme named Self-Prediction for 3D instance and semantic segmentation of point clouds. Distinct from most existing methods that focus on designing convolutional operators, our method designs a new learning scheme to enhance point relation exploring for better segmentation. More specifically, we divide a point cloud sample into two subsets and construct a complete graph based on their representations. Then we use label propagation algorithm to predict labels of one subset when given labels of the other subset. By training with this Self-Prediction task, the backbone network is constrained to fully explore relational context/geometric/shape information and learn more discriminative features for segmentation. Moreover, a general associated framework equipped with our Self-Prediction scheme is designed for enhancing instance and semantic segmentation simultaneously, where instance and semantic representations are combined to perform Self-Prediction. Through this way, instance and semantic segmentation are collaborated and mutually reinforced. Significant performance improvements on instance and semantic segmentation compared with baseline are achieved on S3DIS and ShapeNet. Our method achieves state-of-the-art instance segmentation results on S3DIS and comparable semantic segmentation results compared with state-of-the-arts on S3DIS and ShapeNet when we only take PointNet++ as the backbone network.
Modeling Point Clouds with Self-Attention and Gumbel Subset Sampling
Apr 06, 2019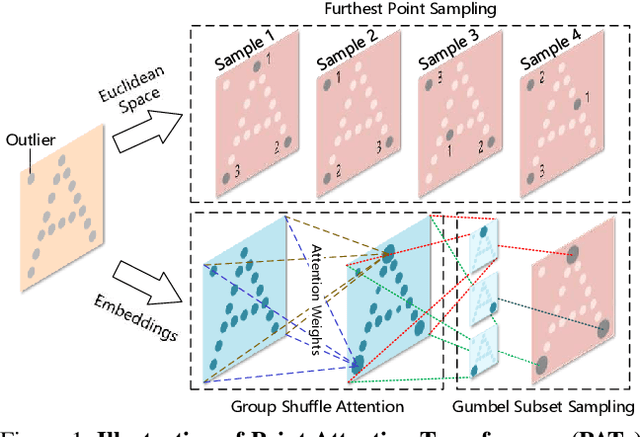
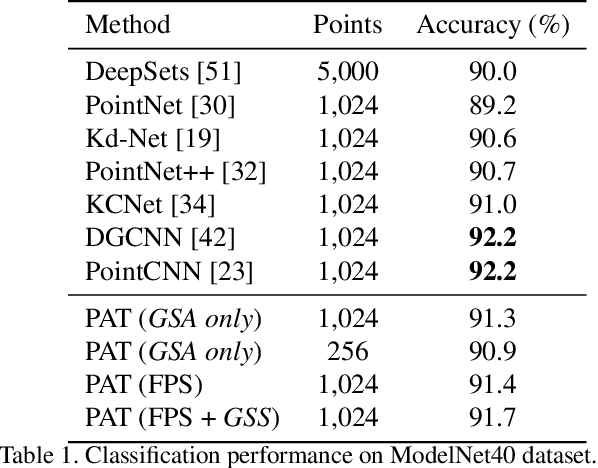
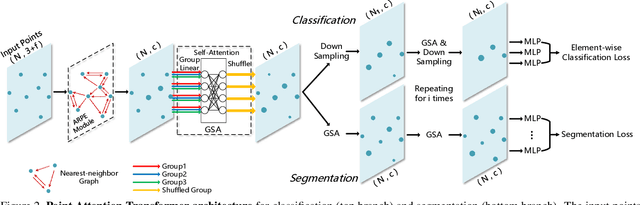
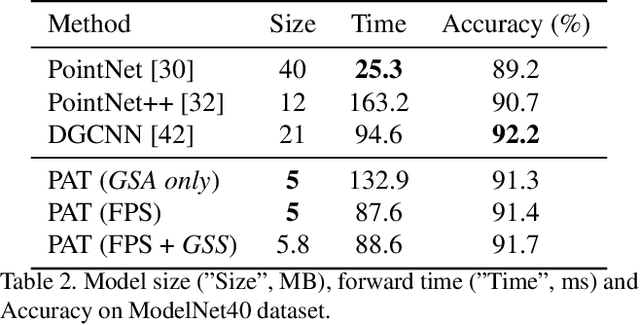
Geometric deep learning is increasingly important thanks to the popularity of 3D sensors. Inspired by the recent advances in NLP domain, the self-attention transformer is introduced to consume the point clouds. We develop Point Attention Transformers (PATs), using a parameter-efficient Group Shuffle Attention (GSA) to replace the costly Multi-Head Attention. We demonstrate its ability to process size-varying inputs, and prove its permutation equivariance. Besides, prior work uses heuristics dependence on the input data (e.g., Furthest Point Sampling) to hierarchically select subsets of input points. Thereby, we for the first time propose an end-to-end learnable and task-agnostic sampling operation, named Gumbel Subset Sampling (GSS), to select a representative subset of input points. Equipped with Gumbel-Softmax, it produces a "soft" continuous subset in training phase, and a "hard" discrete subset in test phase. By selecting representative subsets in a hierarchical fashion, the networks learn a stronger representation of the input sets with lower computation cost. Experiments on classification and segmentation benchmarks show the effectiveness and efficiency of our methods. Furthermore, we propose a novel application, to process event camera stream as point clouds, and achieve a state-of-the-art performance on DVS128 Gesture Dataset.
Adversarial Attack and Defense on Point Sets
Feb 28, 2019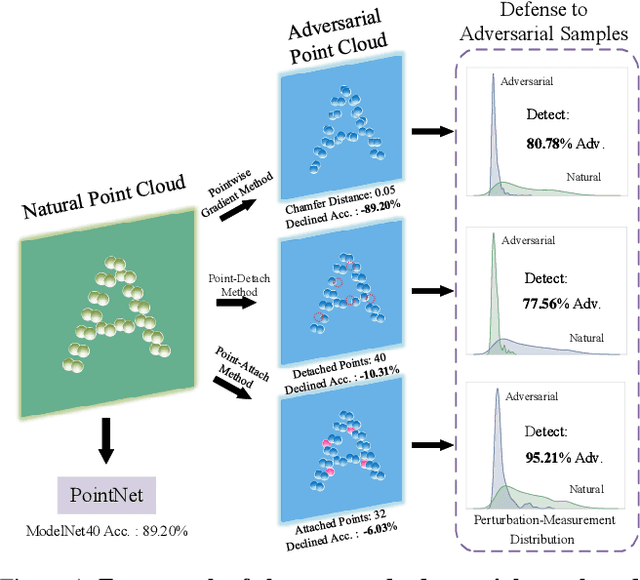
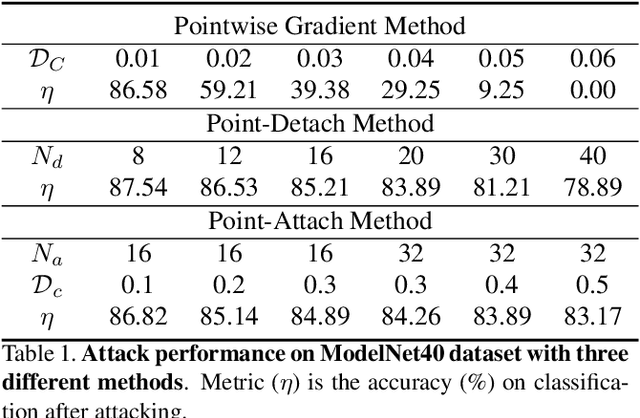
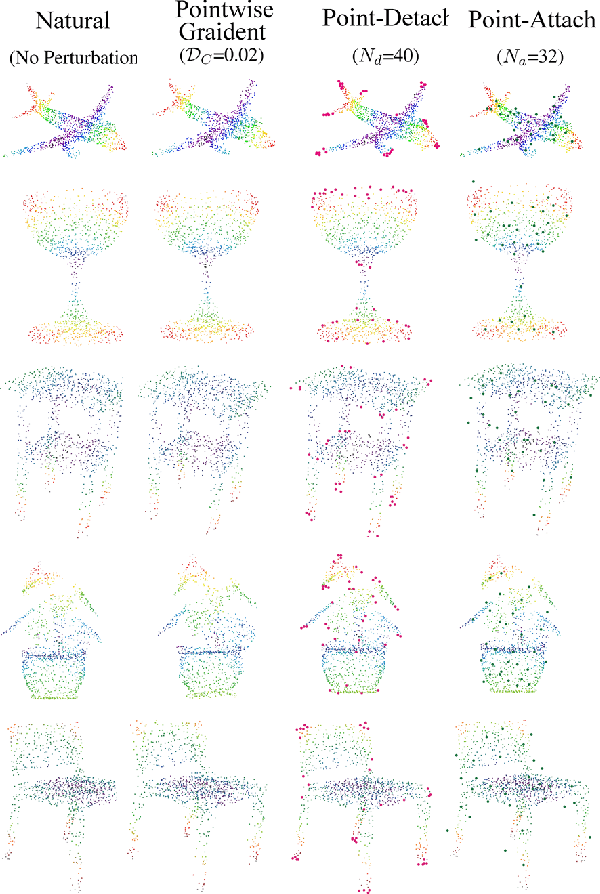

Emergence of the utility of 3D point cloud data in critical vision tasks (e.g., ADAS) urges researchers to pay more attention to the robustness of 3D representations and deep networks. To this end, we develop an attack and defense scheme, dedicated to 3D point cloud data, for preventing 3D point clouds from manipulated as well as pursuing noise-tolerable 3D representation. A set of novel 3D point cloud attack operations are proposed via pointwise gradient perturbation and adversarial point attachment / detachment. We then develop a flexible perturbation-measurement scheme for 3D point cloud data to detect potential attack data or noisy sensing data. Extensive experimental results on common point cloud benchmarks demonstrate the validity of the proposed 3D attack and defense framework.