 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatexBlend: Scaling Multi-concept Customized Generation with Latent Textual Blending
Mar 10, 2025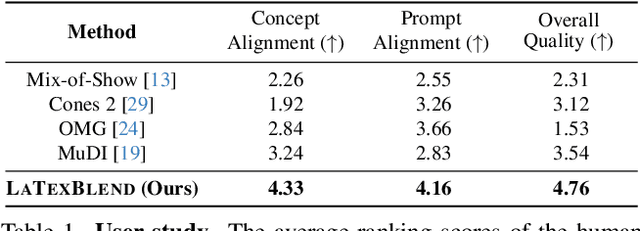
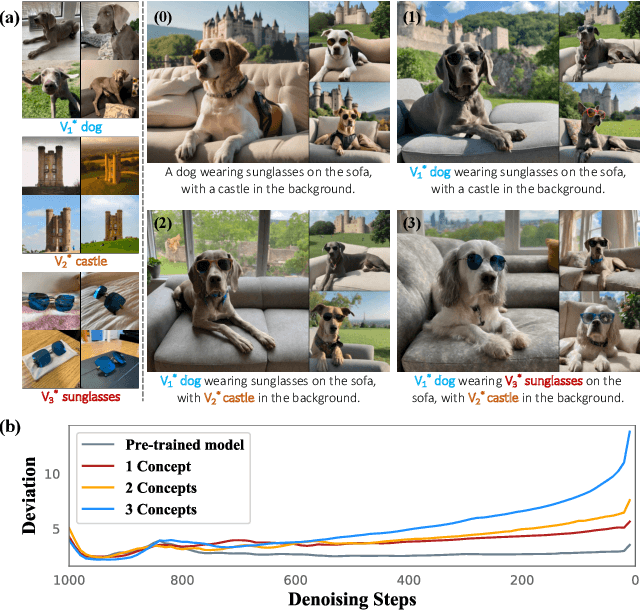
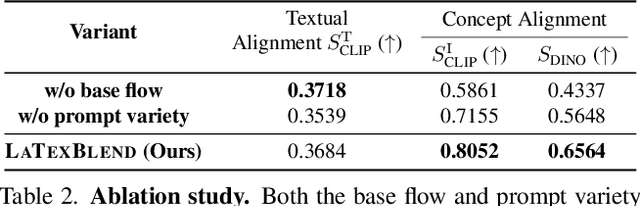
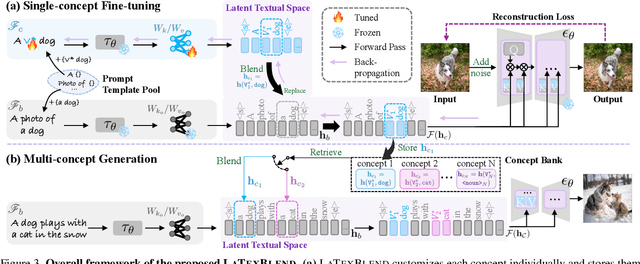
Customized text-to-image generation renders user-specified concepts into novel contexts based on textual prompts. Scaling the number of concepts in customized generation meets a broader demand for user creation, whereas existing methods face challenges with generation quality and computational efficiency. In this paper, we propose LaTexBlend, a novel framework for effectively and efficiently scaling multi-concept customized generation. The core idea of LaTexBlend is to represent single concepts and blend multiple concepts within a Latent Textual space, which is positioned after the text encoder and a linear projection. LaTexBlend customizes each concept individually, storing them in a concept bank with a compact representation of latent textual features that captures sufficient concept information to ensure high fidelity. At inference, concepts from the bank can be freely and seamlessly combined in the latent textual space, offering two key merits for multi-concept generation: 1) excellent scalability, and 2) significant reduction of denoising deviation, preserving coherent layouts. Extensive experiments demonstrate that LaTexBlend can flexibly integrate multiple customized concepts with harmonious structures and high subject fidelity, substantially outperforming baselines in both generation quality and computational efficiency. Our code will be publicly available.
Inferring Fluid Dynamics via Inverse Rendering
Apr 10, 2023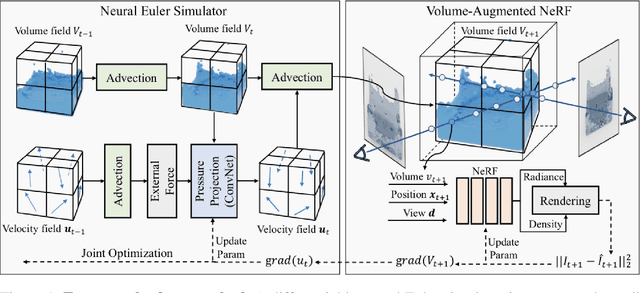


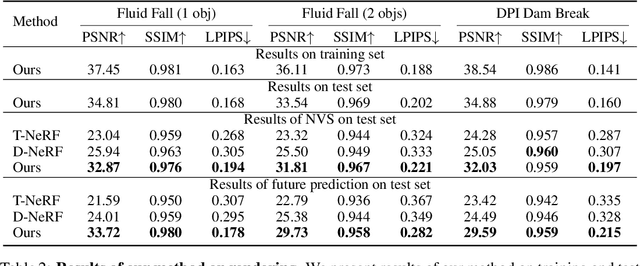
Humans have a strong intuitive understanding of physical processes such as fluid falling by just a glimpse of such a scene picture, i.e., quickly derived from our immersive visual experiences in memory. This work achieves such a photo-to-fluid-dynamics reconstruction functionality learned from unannotated videos, without any supervision of ground-truth fluid dynamics. In a nutshell, a differentiable Euler simulator modeled with a ConvNet-based pressure projection solver, is integrated with a volumetric renderer, supporting end-to-end/coherent differentiable dynamic simulation and rendering. By endowing each sampled point with a fluid volume value, we derive a NeRF-like differentiable renderer dedicated from fluid data; and thanks to this volume-augmented representation, fluid dynamics could be inversely inferred from the error signal between the rendered result and ground-truth video frame (i.e., inverse rendering). Experiments on our generated Fluid Fall datasets and DPI Dam Break dataset are conducted to demonstrate both effectiveness and generalization ability of our method.
Skeleton2Humanoid: Animating Simulated Characters for Physically-plausible Motion In-betweening
Oct 09, 2022
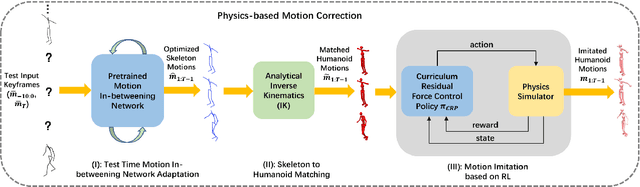

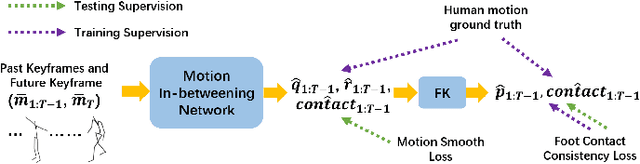
Human motion synthesis is a long-standing problem with various applications in digital twins and the Metaverse. However, modern deep learning based motion synthesis approaches barely consider the physical plausibility of synthesized motions and consequently they usually produce unrealistic human motions. In order to solve this problem, we propose a system ``Skeleton2Humanoid'' which performs physics-oriented motion correction at test time by regularizing synthesized skeleton motions in a physics simulator. Concretely, our system consists of three sequential stages: (I) test time motion synthesis network adaptation, (II) skeleton to humanoid matching and (III) motion imitation based on reinforcement learning (RL). Stage I introduces a test time adaptation strategy, which improves the physical plausibility of synthesized human skeleton motions by optimizing skeleton joint locations. Stage II performs an analytical inverse kinematics strategy, which converts the optimized human skeleton motions to humanoid robot motions in a physics simulator, then the converted humanoid robot motions can be served as reference motions for the RL policy to imitate. Stage III introduces a curriculum residual force control policy, which drives the humanoid robot to mimic complex converted reference motions in accordance with the physical law. We verify our system on a typical human motion synthesis task, motion-in-betweening. Experiments on the challenging LaFAN1 dataset show our system can outperform prior methods significantly in terms of both physical plausibility and accuracy. Code will be released for research purposes at: https://github.com/michaelliyunhao/Skeleton2Humanoid
Object Wake-up: 3-D Object Reconstruction, Animation, and in-situ Rendering from a Single Image
Aug 05, 2021

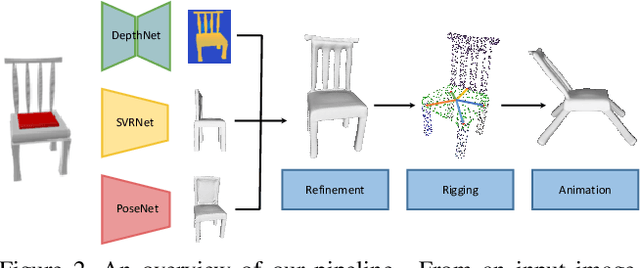
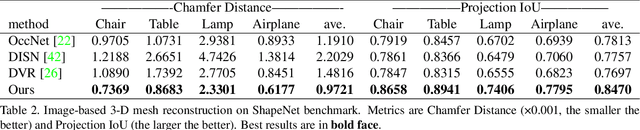
Given a picture of a chair, could we extract the 3-D shape of the chair, animate its plausible articulations and motions, and render in-situ in its original image space? The above question prompts us to devise an automated approach to extract and manipulate articulated objects in single images. Comparing with previous efforts on object manipulation, our work goes beyond 2-D manipulation and focuses on articulable objects, thus introduces greater flexibility for possible object deformations. The pipeline of our approach starts by reconstructing and refining a 3-D mesh representation of the object of interest from an input image; its control joints are predicted by exploiting the semantic part segmentation information; the obtained object 3-D mesh is then rigged \& animated by non-rigid deformation, and rendered to perform in-situ motions in its original image space. Quantitative evaluations are carried out on 3-D reconstruction from single images, an established task that is related to our pipeline, where our results surpass those of the SOTAs by a noticeable margin. Extensive visual results also demonstrate the applicability of our approach.