 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatexBlend: Scaling Multi-concept Customized Generation with Latent Textual Blending
Mar 10, 2025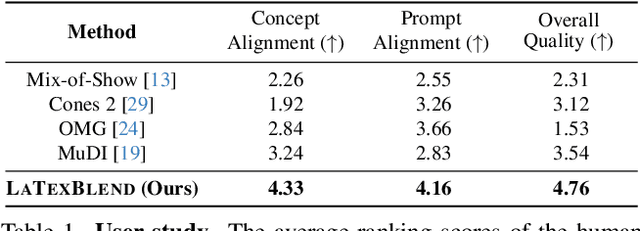
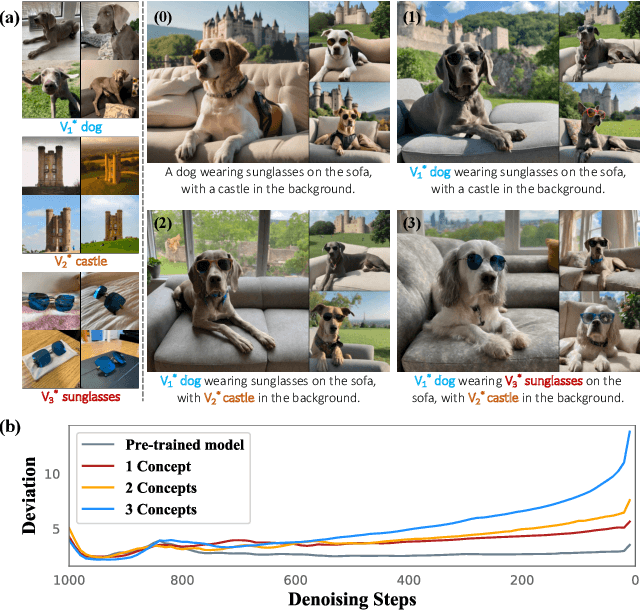
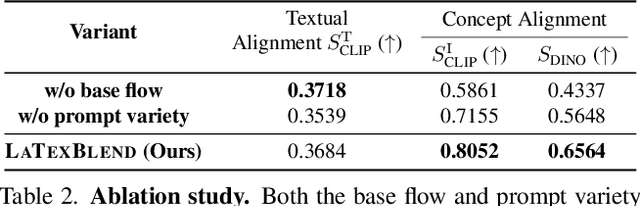
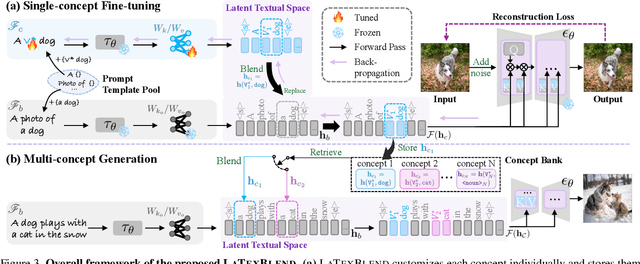
Customized text-to-image generation renders user-specified concepts into novel contexts based on textual prompts. Scaling the number of concepts in customized generation meets a broader demand for user creation, whereas existing methods face challenges with generation quality and computational efficiency. In this paper, we propose LaTexBlend, a novel framework for effectively and efficiently scaling multi-concept customized generation. The core idea of LaTexBlend is to represent single concepts and blend multiple concepts within a Latent Textual space, which is positioned after the text encoder and a linear projection. LaTexBlend customizes each concept individually, storing them in a concept bank with a compact representation of latent textual features that captures sufficient concept information to ensure high fidelity. At inference, concepts from the bank can be freely and seamlessly combined in the latent textual space, offering two key merits for multi-concept generation: 1) excellent scalability, and 2) significant reduction of denoising deviation, preserving coherent layouts. Extensive experiments demonstrate that LaTexBlend can flexibly integrate multiple customized concepts with harmonious structures and high subject fidelity, substantially outperforming baselines in both generation quality and computational efficiency. Our code will be publicly available.
Customized Generation Reimagined: Fidelity and Editability Harmonized
Dec 06, 2024Customized generation aims to incorporate a novel concept into a pre-trained text-to-image model, enabling new generations of the concept in novel contexts guided by textual prompts. However, customized generation suffers from an inherent trade-off between concept fidelity and editability, i.e., between precisely modeling the concept and faithfully adhering to the prompts. Previous methods reluctantly seek a compromise and struggle to achieve both high concept fidelity and ideal prompt alignment simultaneously. In this paper, we propose a Divide, Conquer, then Integrate (DCI) framework, which performs a surgical adjustment in the early stage of denoising to liberate the fine-tuned model from the fidelity-editability trade-off at inference. The two conflicting components in the trade-off are decoupled and individually conquered by two collaborative branches, which are then selectively integrated to preserve high concept fidelity while achieving faithful prompt adherence. To obtain a better fine-tuned model, we introduce an Image-specific Context Optimization} (ICO) strategy for model customization. ICO replaces manual prompt templates with learnable image-specific contexts, providing an adaptive and precise fine-tuning direction to promote the overall performance. Extensive experiments demonstrate the effectiveness of our method in reconciling the fidelity-editability trade-off.
Register assisted aggregation for Visual Place Recognition
May 19, 2024Visual Place Recognition (VPR) refers to the process of using computer vision to recognize the position of the current query image. Due to the significant changes in appearance caused by season, lighting, and time spans between query images and database images for retrieval, these differences increase the difficulty of place recognition. Previous methods often discarded useless features (such as sky, road, vehicles) while uncontrolled discarding features that help improve recognition accuracy (such as buildings, trees). To preserve these useful features, we propose a new feature aggregation method to address this issue. Specifically, in order to obtain global and local features that contain discriminative place information, we added some registers on top of the original image tokens to assist in model training. After reallocating attention weights, these registers were discarded. The experimental results show that these registers surprisingly separate unstable features from the original image representation and outperform state-of-the-art methods.
Fast and Light-Weight Network for Single Frame Structured Illumination Microscopy Super-Resolution
Nov 17, 2021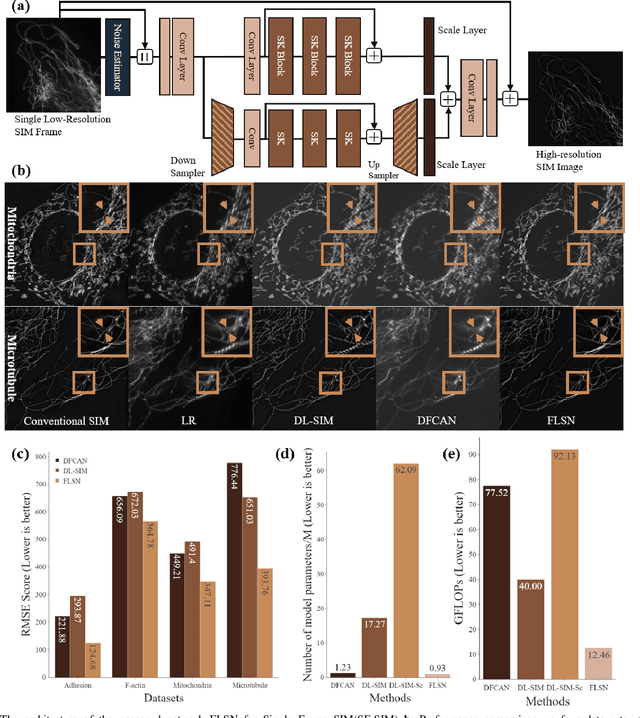
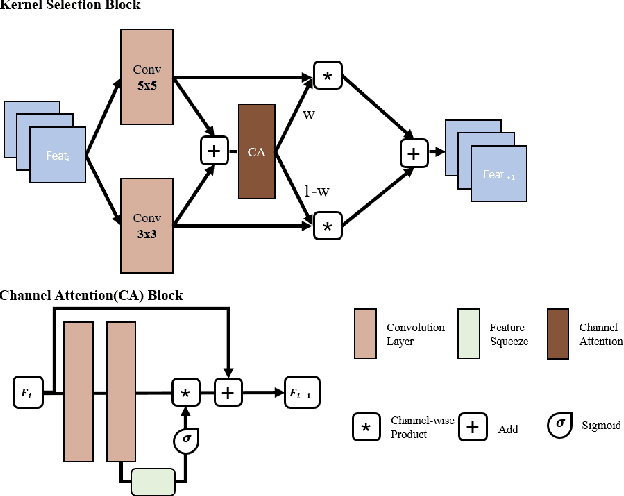
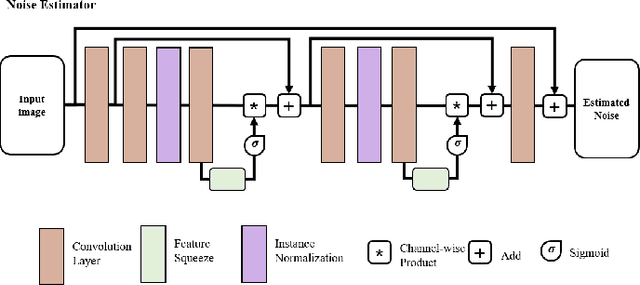
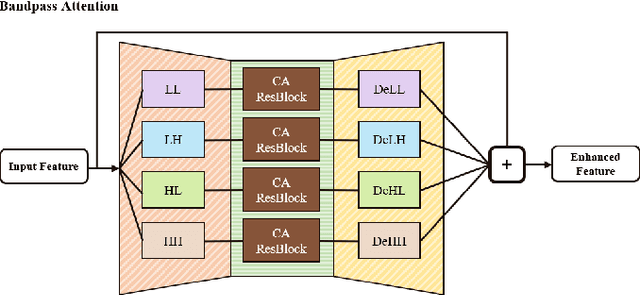
Structured illumination microscopy (SIM) is an important super-resolution based microscopy technique that breaks the diffraction limit and enhances optical microscopy systems. With the development of biology and medical engineering, there is a high demand for real-time and robust SIM imaging under extreme low light and short exposure environments. Existing SIM techniques typically require multiple structured illumination frames to produce a high-resolution image. In this paper, we propose a single-frame structured illumination microscopy (SF-SIM) based on deep learning. Our SF-SIM only needs one shot of a structured illumination frame and generates similar results compared with the traditional SIM systems that typically require 15 shots. In our SF-SIM, we propose a noise estimator which can effectively suppress the noise in the image and enable our method to work under the low light and short exposure environment, without the need for stacking multiple frames for non-local denoising. We also design a bandpass attention module that makes our deep network more sensitive to the change of frequency and enhances the imaging quality. Our proposed SF-SIM is almost 14 times faster than traditional SIM methods when achieving similar results. Therefore, our method is significantly valuable for the development of microbiology and medicine.
Contrastive Embedding for Generalized Zero-Shot Learning
Mar 30, 2021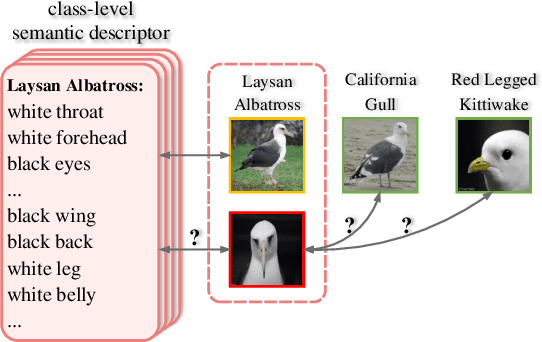
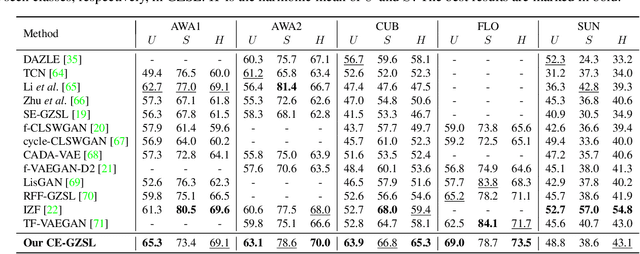

Generalized zero-shot learning (GZSL) aims to recognize objects from both seen and unseen classes, when only the labeled examples from seen classes are provided. Recent feature generation methods learn a generative model that can synthesize the missing visual features of unseen classes to mitigate the data-imbalance problem in GZSL. However, the original visual feature space is suboptimal for GZSL classification since it lacks discriminative information. To tackle this issue, we propose to integrate the generation model with the embedding model, yielding a hybrid GZSL framework. The hybrid GZSL approach maps both the real and the synthetic samples produced by the generation model into an embedding space, where we perform the final GZSL classification. Specifically, we propose a contrastive embedding (CE) for our hybrid GZSL framework. The proposed contrastive embedding can leverage not only the class-wise supervision but also the instance-wise supervision, where the latter is usually neglected by existing GZSL researches. We evaluate our proposed hybrid GZSL framework with contrastive embedding, named CE-GZSL, on five benchmark datasets. The results show that our CEGZSL method can outperform the state-of-the-arts by a significant margin on three datasets. Our codes are available on https://github.com/Hanzy1996/CE-GZSL.
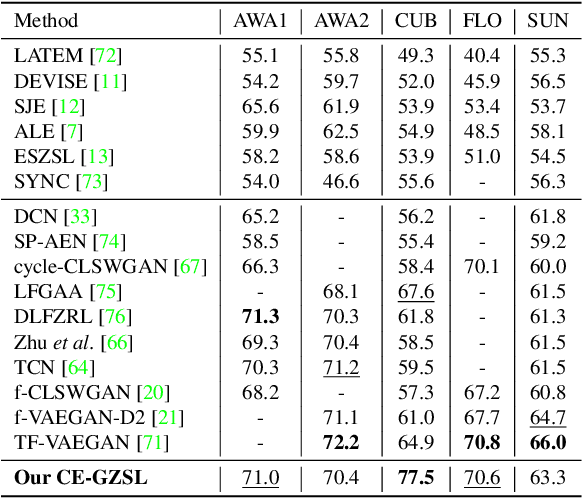
Learning the Redundancy-free Features for Generalized Zero-Shot Object Recognition
Jun 16, 2020
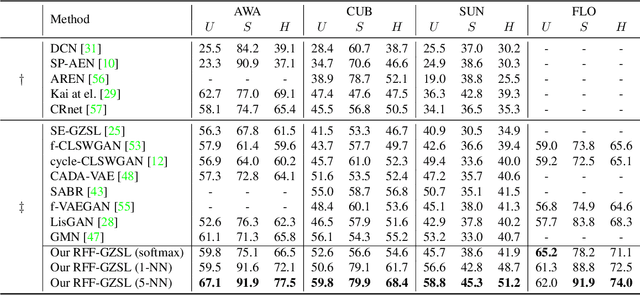

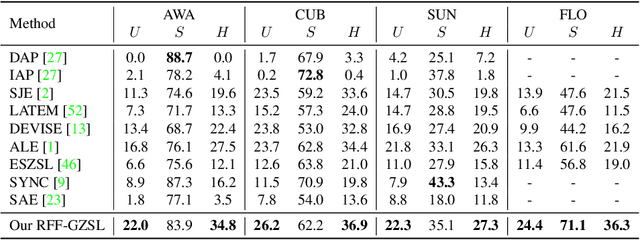
Zero-shot object recognition or zero-shot learning aims to transfer the object recognition ability among the semantically related categories, such as fine-grained animal or bird species. However, the images of different fine-grained objects tend to merely exhibit subtle differences in appearance, which will severely deteriorate zero-shot object recognition. To reduce the superfluous information in the fine-grained objects, in this paper, we propose to learn the redundancy-free features for generalized zero-shot learning. We achieve our motivation by projecting the original visual features into a new (redundancy-free) feature space and then restricting the statistical dependence between these two feature spaces. Furthermore, we require the projected features to keep and even strengthen the category relationship in the redundancy-free feature space. In this way, we can remove the redundant information from the visual features without losing the discriminative information. We extensively evaluate the performance on four benchmark datasets. The results show that our redundancy-free feature based generalized zero-shot learning (RFF-GZSL) approach can outperform the state-of-the-arts often by a large margin. Our code is available.
NTIRE 2020 Challenge on Image Demoireing: Methods and Results
May 06, 2020



This paper reviews the Challenge on Image Demoireing that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2020. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. The challenge was divided into two tracks. Track 1 targeted the single image demoireing problem, which seeks to remove moire patterns from a single image. Track 2 focused on the burst demoireing problem, where a set of degraded moire images of the same scene were provided as input, with the goal of producing a single demoired image as output. The methods were ranked in terms of their fidelity, measured using the peak signal-to-noise ratio (PSNR) between the ground truth clean images and the restored images produced by the participants' methods. The tracks had 142 and 99 registered participants, respectively, with a total of 14 and 6 submissions in the final testing stage. The entries span the current state-of-the-art in image and burst image demoireing problems.
AIM 2019 Challenge on Image Demoireing: Methods and Results
Nov 08, 2019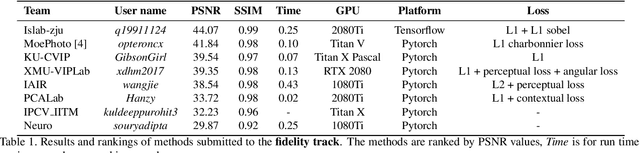
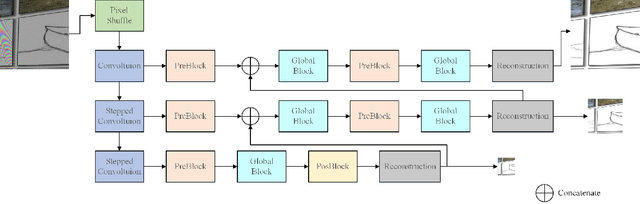
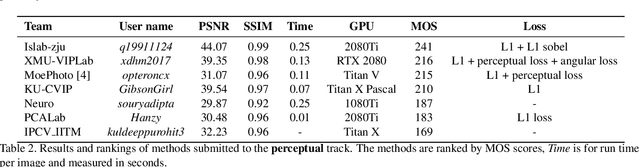
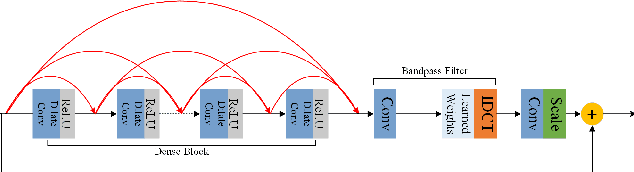
This paper reviews the first-ever image demoireing challenge that was part of the Advances in Image Manipulation (AIM) workshop, held in conjunction with ICCV 2019. This paper describes the challenge, and focuses on the proposed solutions and their results. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. A new dataset, called LCDMoire was created for this challenge, and consists of 10,200 synthetically generated image pairs (moire and clean ground truth). The challenge was divided into 2 tracks. Track 1 targeted fidelity, measuring the ability of demoire methods to obtain a moire-free image compared with the ground truth, while Track 2 examined the perceptual quality of demoire methods. The tracks had 60 and 39 registered participants, respectively. A total of eight teams competed in the final testing phase. The entries span the current the state-of-the-art in the image demoireing problem.
Multi-scale Dynamic Feature Encoding Network for Image Demoireing
Sep 26, 2019



The prevalence of digital sensors, such as digital cameras and mobile phones, simplifies the acquisition of photos. Digital sensors, however, suffer from producing Moire when photographing objects having complex textures, which deteriorates the quality of photos. Moire spreads across various frequency bands of images and is a dynamic texture with varying colors and shapes, which pose two main challenges in demoireing---an important task in image restoration. In this paper, towards addressing the first challenge, we design a multi-scale network to process images at different spatial resolutions, obtaining features in different frequency bands, and thus our method can jointly remove moire in different frequency bands. Towards solving the second challenge, we propose a dynamic feature encoding module (DFE), embedded in each scale, for dynamic texture. Moire pattern can be eliminated more effectively via DFE.Our proposed method, termed Multi-scale convolutional network with Dynamic feature encoding for image DeMoireing (MDDM), can outperform the state of the arts in fidelity as well as perceptual on benchmarks.
Pairwise Constraint Propagation: A Survey
Feb 19, 2015As one of the most important types of (weaker) supervised information in machine learning and pattern recognition, pairwise constraint, which specifies whether a pair of data points occur together, has recently received significant attention, especially the problem of pairwise constraint propagation. At least two reasons account for this trend: the first is that compared to the data label, pairwise constraints are more general and easily to collect, and the second is that since the available pairwise constraints are usually limited, the constraint propagation problem is thus important. This paper provides an up-to-date critical survey of pairwise constraint propagation research. There are two underlying motivations for us to write this survey paper: the first is to provide an up-to-date review of the existing literature, and the second is to offer some insights into the studies of pairwise constraint propagation. To provide a comprehensive survey, we not only categorize existing propagation techniques but also present detailed descriptions of representative methods within each category.