 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Learning Expression Deformations for Data-Efficient Gaussian Avatars
Jun 04, 2026Modeling dynamic facial expressions using 3D Gaussian representations remains challenging due to their unstructured nature. Conventional Gaussian avatar pipelines require extensive multiview and sequential expression data, limiting scalability and accessibility. In this work, we introduce Self-Adaptive Gaussian Expression (SAGE), a framework for self-learning expression-induced Gaussian deformations that enables high-fidelity, animatable avatars from minimal input data. Our method jointly optimizes 2D Gaussian surfels and a Signed Distance Field (SDF) to enforce compact, surface-aligned Gaussian distributions, while a self-supervised expression learning phase replaces long training sequences with geometric and appearance consistency constraints. This design allows flexible deployment across multiple reconstruction regimes: in the multiview setting, only a single frame (timestep) is required instead of thousands; in the monocular setting, only head rotations are needed without expression sequences; and in the one-shot setting, no pretraining or priors are necessary. Experiments demonstrate that our approach achieves reconstruction and animation quality comparable to state-of-the-art methods, while reducing data requirements by several orders of magnitude. Our results highlight the potential of self-supervised Gaussian deformation learning as a step toward accessible, data-efficient avatar creation.
ProtoPathway: Biologically Structured Prototype-Pathway Fusion for Multimodal Cancer Survival Prediction
May 20, 2026We introduce ProtoPathway, an interpretable-by-design multimodal framework for cancer survival prediction that unifies whole slide imaging and transcriptomics through encoders producing biologically grounded representations on both sides of the fusion. On the histopathology side, $K$ learnable morphological prototypes, trained end-to-end with the survival objective, serve as the slide representation itself: patches flow into prototype tokens via soft assignment, compressing variable-length patch sets into fixed task-adaptive tokens. On the genomic side, a bipartite graph neural network encodes gene expression within the Reactome pathway hierarchy, producing pathway embeddings that reflect both constituent genes and their broader biological context through bidirectional message passing over a shared gene--pathway graph. Cross-modal attention then operates over a compact prototype $\times$ pathway matrix in which prototypes query pathways, modeling the biological direction in which molecular programs give rise to tissue morphology. Because both axes carry stable task-learned identity, the attention matrix is itself an interpretability output, yielding native inference-time attribution across the full biological hierarchy, from genes through pathways and prototypes to spatial tissue maps. We evaluate on five TCGA cancer cohorts, demonstrating competitive or superior survival prediction with substantially improved biological interpretability and reduced computational cost, with interpretability claims validated through fold-stratified rank-based population-level analysis. Our source code, model weights, and Reactome pathways, together with a unified codebase reimplementing all multimodal survival baselines under identical preprocessing and evaluation, are available at: https://github.com/AmayaGS/ProtoPathway.
CoLoRSMamba: Conditional LoRA-Steered Mamba for Supervised Multimodal Violence Detection
Apr 02, 2026Violence detection benefits from audio, but real-world soundscapes can be noisy or weakly related to the visible scene. We present CoLoRSMamba, a directional Video to Audio multimodal architecture that couples VideoMamba and AudioMamba through CLS-guided conditional LoRA. At each layer, the VideoMamba CLS token produces a channel-wise modulation vector and a stabilization gate that adapt the AudioMamba projections responsible for the selective state-space parameters (Delta, B, C), including the step-size pathway, yielding scene-aware audio dynamics without token-level cross-attention. Training combines binary classification with a symmetric AV-InfoNCE objective that aligns clip-level audio and video embeddings. To support fair multimodal evaluation, we curate audio-filtered clip level subsets of the NTU-CCTV and DVD datasets from temporal annotations, retaining only clips with available audio. On these subsets, CoLoRSMamba outperforms representative audio-only, video-only, and multimodal baselines, achieving 88.63% accuracy / 86.24% F1-V on NTU-CCTV and 75.77% accuracy / 72.94% F1-V on DVD. It further offers a favorable accuracy-efficiency tradeoff, surpassing several larger models with fewer parameters and FLOPs.
OpenUS: A Fully Open-Source Foundation Model for Ultrasound Image Analysis via Self-Adaptive Masked Contrastive Learning
Nov 14, 2025Ultrasound (US) is one of the most widely used medical imaging modalities, thanks to its low cost, portability, real-time feedback, and absence of ionizing radiation. However, US image interpretation remains highly operator-dependent and varies significantly across anatomical regions, acquisition protocols, and device types. These variations, along with unique challenges such as speckle, low contrast, and limited standardized annotations, hinder the development of generalizable, label-efficient ultrasound AI models. In this paper, we propose OpenUS, the first reproducible, open-source ultrasound foundation model built on a large collection of public data. OpenUS employs a vision Mamba backbone, capturing both local and global long-range dependencies across the image. To extract rich features during pre-training, we introduce a novel self-adaptive masking framework that combines contrastive learning with masked image modeling. This strategy integrates the teacher's attention map with student reconstruction loss, adaptively refining clinically-relevant masking to enhance pre-training effectiveness. OpenUS also applies a dynamic learning schedule to progressively adjust the difficulty of the pre-training process. To develop the foundation model, we compile the largest to-date public ultrasound dataset comprising over 308K images from 42 publicly available datasets, covering diverse anatomical regions, institutions, imaging devices, and disease types. Our pre-trained OpenUS model can be easily adapted to specific downstream tasks by serving as a backbone for label-efficient fine-tuning. Code is available at https://github.com/XZheng0427/OpenUS.
ViDAR: Video Diffusion-Aware 4D Reconstruction From Monocular Inputs
Jun 23, 2025

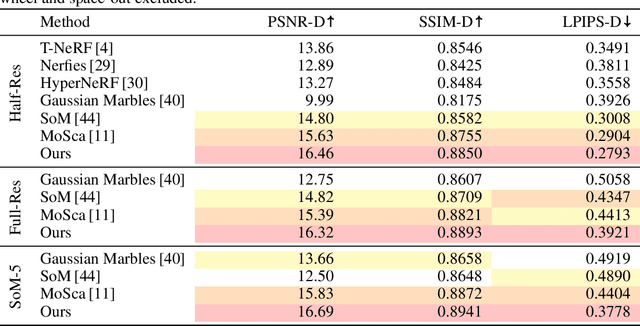

Dynamic Novel View Synthesis aims to generate photorealistic views of moving subjects from arbitrary viewpoints. This task is particularly challenging when relying on monocular video, where disentangling structure from motion is ill-posed and supervision is scarce. We introduce Video Diffusion-Aware Reconstruction (ViDAR), a novel 4D reconstruction framework that leverages personalised diffusion models to synthesise a pseudo multi-view supervision signal for training a Gaussian splatting representation. By conditioning on scene-specific features, ViDAR recovers fine-grained appearance details while mitigating artefacts introduced by monocular ambiguity. To address the spatio-temporal inconsistency of diffusion-based supervision, we propose a diffusion-aware loss function and a camera pose optimisation strategy that aligns synthetic views with the underlying scene geometry. Experiments on DyCheck, a challenging benchmark with extreme viewpoint variation, show that ViDAR outperforms all state-of-the-art baselines in visual quality and geometric consistency. We further highlight ViDAR's strong improvement over baselines on dynamic regions and provide a new benchmark to compare performance in reconstructing motion-rich parts of the scene. Project page: https://vidar-4d.github.io
DanceChat: Large Language Model-Guided Music-to-Dance Generation
Jun 12, 2025Music-to-dance generation aims to synthesize human dance motion conditioned on musical input. Despite recent progress, significant challenges remain due to the semantic gap between music and dance motion, as music offers only abstract cues, such as melody, groove, and emotion, without explicitly specifying the physical movements. Moreover, a single piece of music can produce multiple plausible dance interpretations. This one-to-many mapping demands additional guidance, as music alone provides limited information for generating diverse dance movements. The challenge is further amplified by the scarcity of paired music and dance data, which restricts the model\^a\u{A}\'Zs ability to learn diverse dance patterns. In this paper, we introduce DanceChat, a Large Language Model (LLM)-guided music-to-dance generation approach. We use an LLM as a choreographer that provides textual motion instructions, offering explicit, high-level guidance for dance generation. This approach goes beyond implicit learning from music alone, enabling the model to generate dance that is both more diverse and better aligned with musical styles. Our approach consists of three components: (1) an LLM-based pseudo instruction generation module that produces textual dance guidance based on music style and structure, (2) a multi-modal feature extraction and fusion module that integrates music, rhythm, and textual guidance into a shared representation, and (3) a diffusion-based motion synthesis module together with a multi-modal alignment loss, which ensures that the generated dance is aligned with both musical and textual cues. Extensive experiments on AIST++ and human evaluations show that DanceChat outperforms state-of-the-art methods both qualitatively and quantitatively.
STaR: Seamless Spatial-Temporal Aware Motion Retargeting with Penetration and Consistency Constraints
Apr 09, 2025Motion retargeting seeks to faithfully replicate the spatio-temporal motion characteristics of a source character onto a target character with a different body shape. Apart from motion semantics preservation, ensuring geometric plausibility and maintaining temporal consistency are also crucial for effective motion retargeting. However, many existing methods prioritize either geometric plausibility or temporal consistency. Neglecting geometric plausibility results in interpenetration while neglecting temporal consistency leads to motion jitter. In this paper, we propose a novel sequence-to-sequence model for seamless Spatial-Temporal aware motion Retargeting (STaR), with penetration and consistency constraints. STaR consists of two modules: (1) a spatial module that incorporates dense shape representation and a novel limb penetration constraint to ensure geometric plausibility while preserving motion semantics, and (2) a temporal module that utilizes a temporal transformer and a novel temporal consistency constraint to predict the entire motion sequence at once while enforcing multi-level trajectory smoothness. The seamless combination of the two modules helps us achieve a good balance between the semantic, geometric, and temporal targets. Extensive experiments on the Mixamo and ScanRet datasets demonstrate that our method produces plausible and coherent motions while significantly reducing interpenetration rates compared with other approaches.
BioX-CPath: Biologically-driven Explainable Diagnostics for Multistain IHC Computational Pathology
Mar 26, 2025



The development of biologically interpretable and explainable models remains a key challenge in computational pathology, particularly for multistain immunohistochemistry (IHC) analysis. We present BioX-CPath, an explainable graph neural network architecture for whole slide image (WSI) classification that leverages both spatial and semantic features across multiple stains. At its core, BioX-CPath introduces a novel Stain-Aware Attention Pooling (SAAP) module that generates biologically meaningful, stain-aware patient embeddings. Our approach achieves state-of-the-art performance on both Rheumatoid Arthritis and Sjogren's Disease multistain datasets. Beyond performance metrics, BioX-CPath provides interpretable insights through stain attention scores, entropy measures, and stain interaction scores, that permit measuring model alignment with known pathological mechanisms. This biological grounding, combined with strong classification performance, makes BioX-CPath particularly suitable for clinical applications where interpretability is key. Source code and documentation can be found at: https://github.com/AmayaGS/BioX-CPath.
HandSplat: Embedding-Driven Gaussian Splatting for High-Fidelity Hand Rendering
Mar 18, 2025
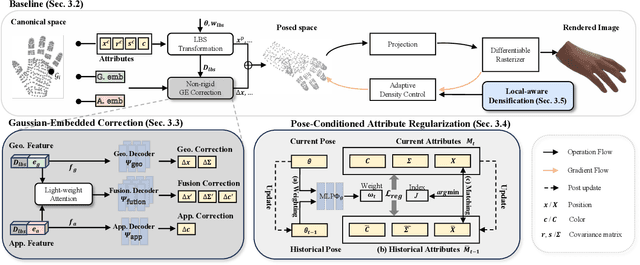
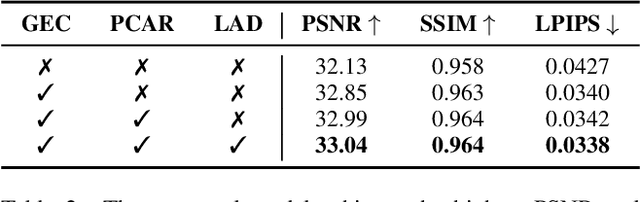

Existing 3D Gaussian Splatting (3DGS) methods for hand rendering rely on rigid skeletal motion with an oversimplified non-rigid motion model, which fails to capture fine geometric and appearance details. Additionally, they perform densification based solely on per-point gradients and process poses independently, ignoring spatial and temporal correlations. These limitations lead to geometric detail loss, temporal instability, and inefficient point distribution. To address these issues, we propose HandSplat, a novel Gaussian Splatting-based framework that enhances both fidelity and stability for hand rendering. To improve fidelity, we extend standard 3DGS attributes with implicit geometry and appearance embeddings for finer non-rigid motion modeling while preserving the static hand characteristic modeled by original 3DGS attributes. Additionally, we introduce a local gradient-aware densification strategy that dynamically refines Gaussian density in high-variation regions. To improve stability, we incorporate pose-conditioned attribute regularization to encourage attribute consistency across similar poses, mitigating temporal artifacts. Extensive experiments on InterHand2.6M demonstrate that HandSplat surpasses existing methods in fidelity and stability while achieving real-time performance. We will release the code and pre-trained models upon acceptance.
SuperCap: Multi-resolution Superpixel-based Image Captioning
Mar 11, 2025It has been a longstanding goal within image captioning to move beyond a dependence on object detection. We investigate using superpixels coupled with Vision Language Models (VLMs) to bridge the gap between detector-based captioning architectures and those that solely pretrain on large datasets. Our novel superpixel approach ensures that the model receives object-like features whilst the use of VLMs provides our model with open set object understanding. Furthermore, we extend our architecture to make use of multi-resolution inputs, allowing our model to view images in different levels of detail, and use an attention mechanism to determine which parts are most relevant to the caption. We demonstrate our model's performance with multiple VLMs and through a range of ablations detailing the impact of different architectural choices. Our full model achieves a competitive CIDEr score of $136.9$ on the COCO Karpathy split.