 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenUS: A Fully Open-Source Foundation Model for Ultrasound Image Analysis via Self-Adaptive Masked Contrastive Learning
Nov 14, 2025Ultrasound (US) is one of the most widely used medical imaging modalities, thanks to its low cost, portability, real-time feedback, and absence of ionizing radiation. However, US image interpretation remains highly operator-dependent and varies significantly across anatomical regions, acquisition protocols, and device types. These variations, along with unique challenges such as speckle, low contrast, and limited standardized annotations, hinder the development of generalizable, label-efficient ultrasound AI models. In this paper, we propose OpenUS, the first reproducible, open-source ultrasound foundation model built on a large collection of public data. OpenUS employs a vision Mamba backbone, capturing both local and global long-range dependencies across the image. To extract rich features during pre-training, we introduce a novel self-adaptive masking framework that combines contrastive learning with masked image modeling. This strategy integrates the teacher's attention map with student reconstruction loss, adaptively refining clinically-relevant masking to enhance pre-training effectiveness. OpenUS also applies a dynamic learning schedule to progressively adjust the difficulty of the pre-training process. To develop the foundation model, we compile the largest to-date public ultrasound dataset comprising over 308K images from 42 publicly available datasets, covering diverse anatomical regions, institutions, imaging devices, and disease types. Our pre-trained OpenUS model can be easily adapted to specific downstream tasks by serving as a backbone for label-efficient fine-tuning. Code is available at https://github.com/XZheng0427/OpenUS.
HanDrawer: Leveraging Spatial Information to Render Realistic Hands Using a Conditional Diffusion Model in Single Stage
Mar 03, 2025



Although diffusion methods excel in text-to-image generation, generating accurate hand gestures remains a major challenge, resulting in severe artifacts, such as incorrect number of fingers or unnatural gestures. To enable the diffusion model to learn spatial information to improve the quality of the hands generated, we propose HanDrawer, a module to condition the hand generation process. Specifically, we apply graph convolutional layers to extract the endogenous spatial structure and physical constraints implicit in MANO hand mesh vertices. We then align and fuse these spatial features with other modalities via cross-attention. The spatially fused features are used to guide a single stage diffusion model denoising process for high quality generation of the hand region. To improve the accuracy of spatial feature fusion, we propose a Position-Preserving Zero Padding (PPZP) fusion strategy, which ensures that the features extracted by HanDrawer are fused into the region of interest in the relevant layers of the diffusion model. HanDrawer learns the entire image features while paying special attention to the hand region thanks to an additional hand reconstruction loss combined with the denoising loss. To accurately train and evaluate our approach, we perform careful cleansing and relabeling of the widely used HaGRID hand gesture dataset and obtain high quality multimodal data. Quantitative and qualitative analyses demonstrate the state-of-the-art performance of our method on the HaGRID dataset through multiple evaluation metrics. Source code and our enhanced dataset will be released publicly if the paper is accepted.
Adaptive Multi-Modal Control of Digital Human Hand Synthesis Using a Region-Aware Cycle Loss
Sep 13, 2024



Diffusion models have shown their remarkable ability to synthesize images, including the generation of humans in specific poses. However, current models face challenges in adequately expressing conditional control for detailed hand pose generation, leading to significant distortion in the hand regions. To tackle this problem, we first curate the How2Sign dataset to provide richer and more accurate hand pose annotations. In addition, we introduce adaptive, multi-modal fusion to integrate characters' physical features expressed in different modalities such as skeleton, depth, and surface normal. Furthermore, we propose a novel Region-Aware Cycle Loss (RACL) that enables the diffusion model training to focus on improving the hand region, resulting in improved quality of generated hand gestures. More specifically, the proposed RACL computes a weighted keypoint distance between the full-body pose keypoints from the generated image and the ground truth, to generate higher-quality hand poses while balancing overall pose accuracy. Moreover, we use two hand region metrics, named hand-PSNR and hand-Distance for hand pose generation evaluations. Our experimental evaluations demonstrate the effectiveness of our proposed approach in improving the quality of digital human pose generation using diffusion models, especially the quality of the hand region. The source code is available at https://github.com/fuqifan/Region-Aware-Cycle-Loss.
Vector Quantized Semantic Communication System
Sep 23, 2022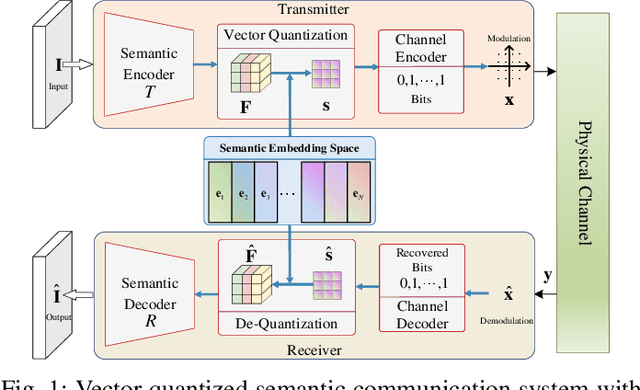
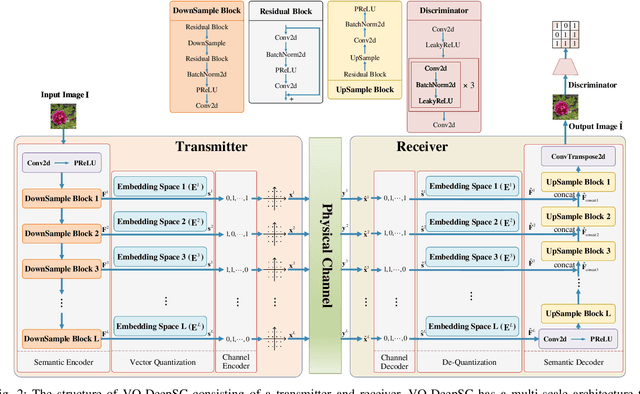
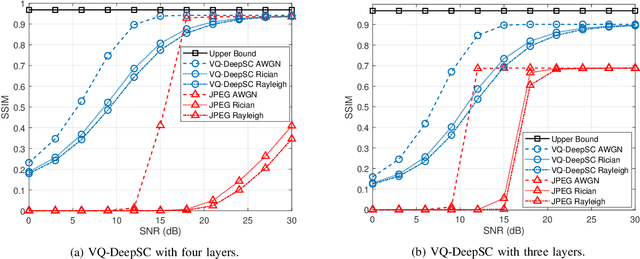
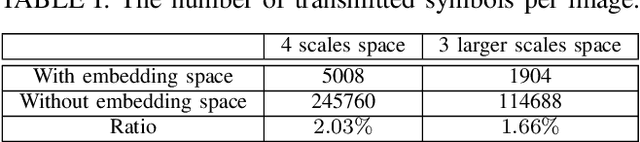
Although analog semantic communication systems have received considerable attention in the literature, there is less work on digital semantic communication systems. In this paper, we develop a deep learning (DL)-enabled vector quantized (VQ) semantic communication system for image transmission, named VQ-DeepSC. Specifically, we propose a convolutional neural network (CNN)-based transceiver to extract multi-scale semantic features of images and introduce multi-scale semantic embedding spaces to perform semantic feature quantization, rendering the data compatible with digital communication systems. Furthermore, we employ adversarial training to improve the quality of received images by introducing a PatchGAN discriminator. Experimental results demonstrate that the proposed VQ-DeepSC outperforms traditional image transmission methods in terms of SSIM.