 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Segmentation of Cardiac Images Leveraging Metadata
Oct 30, 2024Cardiac image segmentation is essential for automated cardiac function assessment and monitoring of changes in cardiac structures over time. Inspired by coarse-to-fine approaches in image analysis, we propose a novel multitask compositional segmentation approach that can simultaneously localize the heart in a cardiac image and perform part-based segmentation of different regions of interest. We demonstrate that this compositional approach achieves better results than direct segmentation of the anatomies. Further, we propose a novel Cross-Modal Feature Integration (CMFI) module to leverage the metadata related to cardiac imaging collected during image acquisition. We perform experiments on two different modalities, MRI and ultrasound, using public datasets, Multi-disease, Multi-View, and Multi-Centre (M&Ms-2) and Multi-structure Ultrasound Segmentation (CAMUS) data, to showcase the efficiency of the proposed compositional segmentation method and Cross-Modal Feature Integration module incorporating metadata within the proposed compositional segmentation network. The source code is available: https://github.com/kabbas570/CompSeg-MetaData.
Convolution and Attention-Free Mamba-based Cardiac Image Segmentation
Jun 09, 2024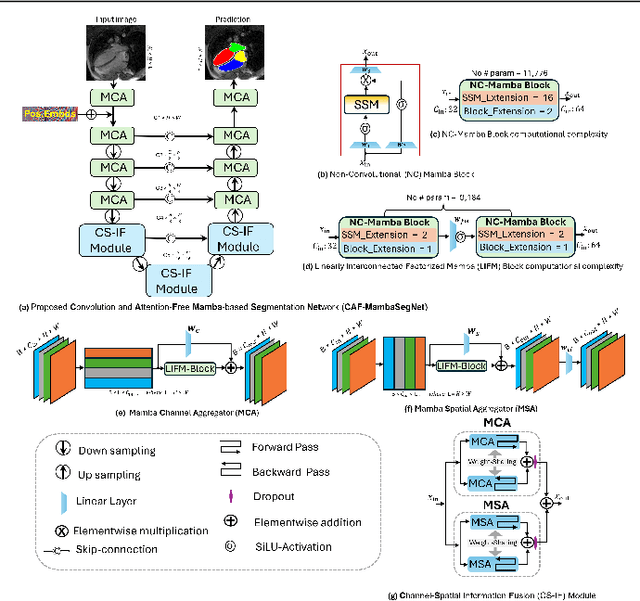

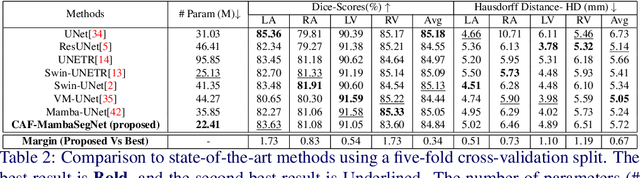
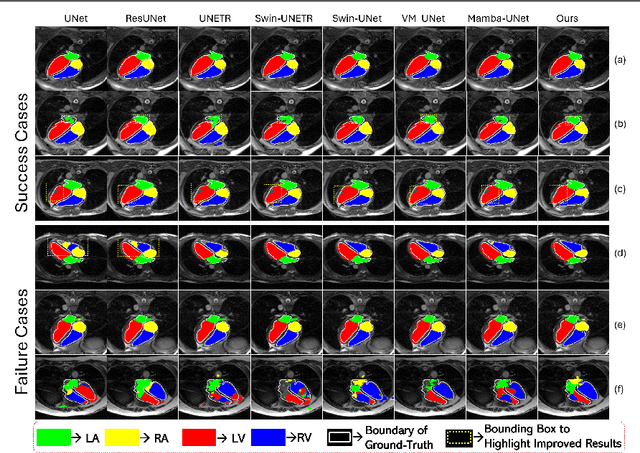
Convolutional Neural Networks (CNNs) and Transformer-based self-attention models have become standard for medical image segmentation. This paper demonstrates that convolution and self-attention, while widely used, are not the only effective methods for segmentation. Breaking with convention, we present a Convolution and self-Attention Free Mamba-based semantic Segmentation Network named CAF-MambaSegNet. Specifically, we design a Mamba-based Channel Aggregator and Spatial Aggregator, which are applied independently in each encoder-decoder stage. The Channel Aggregator extracts information across different channels, and the Spatial Aggregator learns features across different spatial locations. We also propose a Linearly Interconnected Factorized Mamba (LIFM) Block to reduce the computational complexity of a Mamba and to enhance its decision function by introducing a non-linearity between two factorized Mamba blocks. Our goal is not to outperform state-of-the-art results but to show how this innovative, convolution and self-attention-free method can inspire further research beyond well-established CNNs and Transformers, achieving linear complexity and reducing the number of parameters. Source code and pre-trained models will be publicly available.
Multi-view Cardiac Image Segmentation via Trans-Dimensional Priors
Apr 25, 2024



We propose a novel multi-stage trans-dimensional architecture for multi-view cardiac image segmentation. Our method exploits the relationship between long-axis (2D) and short-axis (3D) magnetic resonance (MR) images to perform a sequential 3D-to-2D-to-3D segmentation, segmenting the long-axis and short-axis images. In the first stage, 3D segmentation is performed using the short-axis image, and the prediction is transformed to the long-axis view and used as a segmentation prior in the next stage. In the second step, the heart region is localized and cropped around the segmentation prior using a Heart Localization and Cropping (HLC) module, focusing the subsequent model on the heart region of the image, where a 2D segmentation is performed. Similarly, we transform the long-axis prediction to the short-axis view, localize and crop the heart region and again perform a 3D segmentation to refine the initial short-axis segmentation. We evaluate our proposed method on the Multi-Disease, Multi-View & Multi-Center Right Ventricular Segmentation in Cardiac MRI (M&Ms-2) dataset, where our method outperforms state-of-the-art methods in segmenting cardiac regions of interest in both short-axis and long-axis images. The pre-trained models, source code, and implementation details will be publicly available.
Crop and Couple: cardiac image segmentation using interlinked specialist networks
Feb 14, 2024Diagnosis of cardiovascular disease using automated methods often relies on the critical task of cardiac image segmentation. We propose a novel strategy that performs segmentation using specialist networks that focus on a single anatomy (left ventricle, right ventricle, or myocardium). Given an input long-axis cardiac MR image, our method performs a ternary segmentation in the first stage to identify these anatomical regions, followed by cropping the original image to focus subsequent processing on the anatomical regions. The specialist networks are coupled through an attention mechanism that performs cross-attention to interlink features from different anatomies, serving as a soft relative shape prior. Central to our approach is an additive attention block (E-2A block), which is used throughout our architecture thanks to its efficiency.