 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolution and Attention-Free Mamba-based Cardiac Image Segmentation
Paper and Code
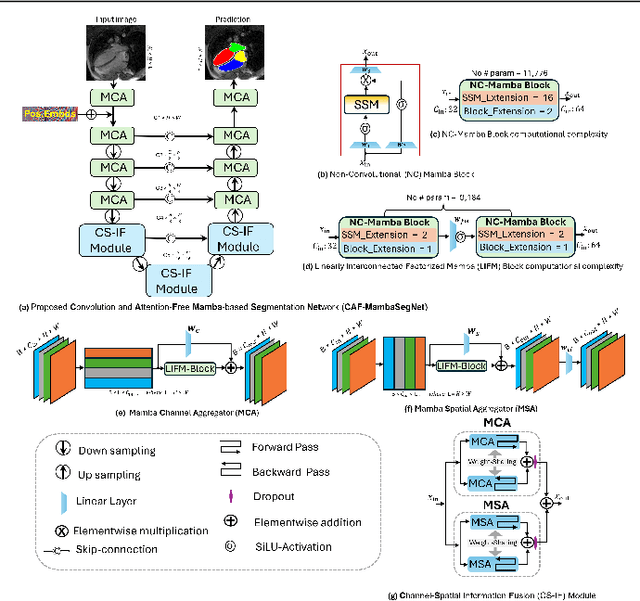

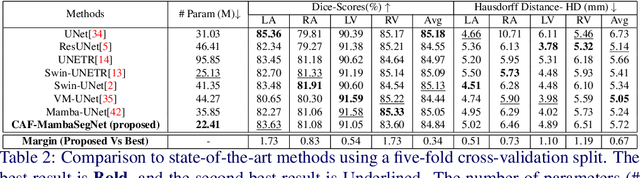
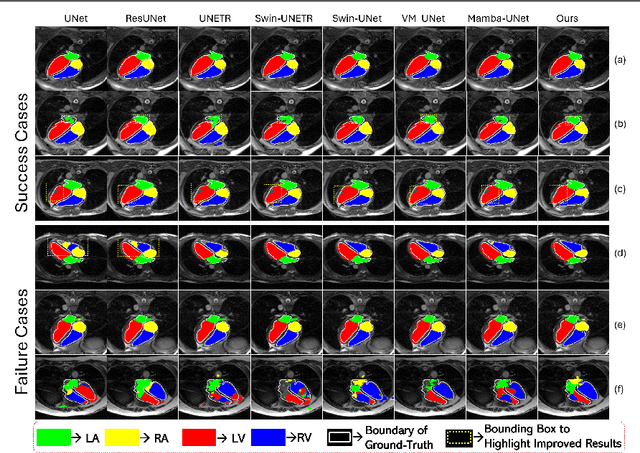
Convolutional Neural Networks (CNNs) and Transformer-based self-attention models have become standard for medical image segmentation. This paper demonstrates that convolution and self-attention, while widely used, are not the only effective methods for segmentation. Breaking with convention, we present a Convolution and self-Attention Free Mamba-based semantic Segmentation Network named CAF-MambaSegNet. Specifically, we design a Mamba-based Channel Aggregator and Spatial Aggregator, which are applied independently in each encoder-decoder stage. The Channel Aggregator extracts information across different channels, and the Spatial Aggregator learns features across different spatial locations. We also propose a Linearly Interconnected Factorized Mamba (LIFM) Block to reduce the computational complexity of a Mamba and to enhance its decision function by introducing a non-linearity between two factorized Mamba blocks. Our goal is not to outperform state-of-the-art results but to show how this innovative, convolution and self-attention-free method can inspire further research beyond well-established CNNs and Transformers, achieving linear complexity and reducing the number of parameters. Source code and pre-trained models will be publicly available.