 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOUT: Active Information Foraging for Long-Text Understanding with Decoupled Epistemic States
May 06, 2026Long-Text Understanding (LTU) at million-token scale requires balancing reasoning fidelity with computational efficiency. Frontier long-context LLMs can process millions of token contexts end-to-end, but they suffer from high token consumption and attention dilution. In parallel, specialized LTU agents often sacrifice fidelity through task-agnostic abstractions like graph construction or indexing. We identify a key insight for LTU: query-relevant information is typically sparse relative to the full document, so effective reasoning should rely on a query-sufficient subset rather than the entire context. To address this, we propose SCOUT, a new paradigm for LTU that shifts from passive processing to active information foraging. It treats the document as an explorable environment and answers from a compact, provenance-grounded epistemic state. Guided by state-level gap diagnosis, SCOUT adaptively alternates between coarse-to-fine exploration and anchored state updates that progressively contract its epistemic state toward query sufficiency. Experiments show that SCOUT matches state-of-the-art proprietary models while reducing token consumption by up to 8x. Moreover, SCOUT remains stable as context length scales, substantially alleviating the practical cost-performance trade-off.
MERGETUNE: Continued fine-tuning of vision-language models
Jan 16, 2026Fine-tuning vision-language models (VLMs) such as CLIP often leads to catastrophic forgetting of pretrained knowledge. Prior work primarily aims to mitigate forgetting during adaptation; however, forgetting often remains inevitable during this process. We introduce a novel paradigm, continued fine-tuning (CFT), which seeks to recover pretrained knowledge after a zero-shot model has already been adapted. We propose a simple, model-agnostic CFT strategy (named MERGETUNE) guided by linear mode connectivity (LMC), which can be applied post hoc to existing fine-tuned models without requiring architectural changes. Given a fine-tuned model, we continue fine-tuning its trainable parameters (e.g., soft prompts or linear heads) to search for a continued model which has two low-loss paths to the zero-shot (e.g., CLIP) and the fine-tuned (e.g., CoOp) solutions. By exploiting the geometry of the loss landscape, the continued model implicitly merges the two solutions, restoring pretrained knowledge lost in the fine-tuned counterpart. A challenge is that the vanilla LMC constraint requires data replay from the pretraining task. We approximate this constraint for the zero-shot model via a second-order surrogate, eliminating the need for large-scale data replay. Experiments show that MERGETUNE improves the harmonic mean of CoOp by +5.6% on base-novel generalisation without adding parameters. On robust fine-tuning evaluations, the LMC-merged model from MERGETUNE surpasses ensemble baselines with lower inference cost, achieving further gains and state-of-the-art results when ensembled with the zero-shot model. Our code is available at https://github.com/Surrey-UP-Lab/MERGETUNE.
Dynamic Avatar-Scene Rendering from Human-centric Context
Nov 13, 2025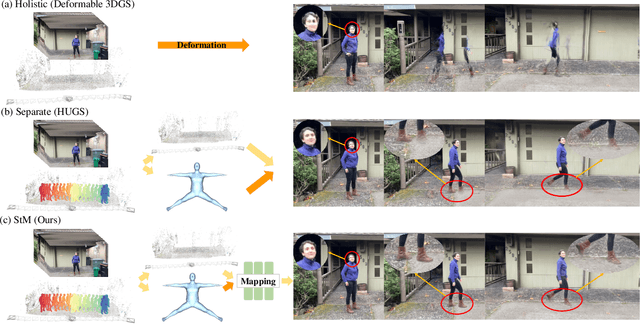
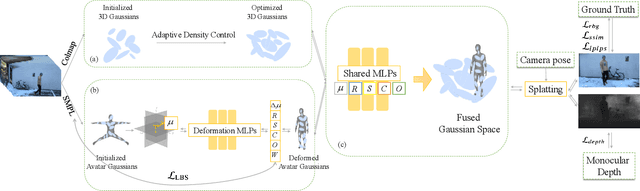


Reconstructing dynamic humans interacting with real-world environments from monocular videos is an important and challenging task. Despite considerable progress in 4D neural rendering, existing approaches either model dynamic scenes holistically or model scenes and backgrounds separately aim to introduce parametric human priors. However, these approaches either neglect distinct motion characteristics of various components in scene especially human, leading to incomplete reconstructions, or ignore the information exchange between the separately modeled components, resulting in spatial inconsistencies and visual artifacts at human-scene boundaries. To address this, we propose {\bf Separate-then-Map} (StM) strategy that introduces a dedicated information mapping mechanism to bridge separately defined and optimized models. Our method employs a shared transformation function for each Gaussian attribute to unify separately modeled components, enhancing computational efficiency by avoiding exhaustive pairwise interactions while ensuring spatial and visual coherence between humans and their surroundings. Extensive experiments on monocular video datasets demonstrate that StM significantly outperforms existing state-of-the-art methods in both visual quality and rendering accuracy, particularly at challenging human-scene interaction boundaries.
MARS: Optimizing Dual-System Deep Research via Multi-Agent Reinforcement Learning
Oct 06, 2025Large Reasoning Models (LRMs) often exhibit a tendency for overanalysis in simple tasks, where the models excessively utilize System 2-type, deliberate reasoning, leading to inefficient token generation. Furthermore, these models face challenges in adapting their reasoning capabilities to rapidly changing environments due to the static nature of their pretraining data. To address these issues, advancing Large Language Models (LLMs) for complex reasoning tasks requires innovative approaches that bridge intuitive and deliberate cognitive processes, akin to human cognition's dual-system dynamic. This paper introduces a Multi-Agent System for Deep ReSearch (MARS) enabling seamless integration of System 1's fast, intuitive thinking with System 2's deliberate reasoning within LLMs. MARS strategically integrates multiple external tools, such as Google Search, Google Scholar, and Python Interpreter, to access up-to-date information and execute complex computations, while creating a specialized division of labor where System 1 efficiently processes and summarizes high-volume external information, providing distilled insights that expand System 2's reasoning context without overwhelming its capacity. Furthermore, we propose a multi-agent reinforcement learning framework extending Group Relative Policy Optimization to simultaneously optimize both systems with multi-turn tool interactions, bin-packing optimization, and sample balancing strategies that enhance collaborative efficiency. Extensive experiments demonstrate MARS achieves substantial improvements of 3.86% on the challenging Humanity's Last Exam (HLE) benchmark and an average gain of 8.9% across 7 knowledge-intensive tasks, validating the effectiveness of our dual-system paradigm for complex reasoning in dynamic information environments.
Dual-Stage Safe Herding Framework for Adversarial Attacker in Dynamic Environment
Sep 10, 2025Recent advances in robotics have enabled the widespread deployment of autonomous robotic systems in complex operational environments, presenting both unprecedented opportunities and significant security problems. Traditional shepherding approaches based on fixed formations are often ineffective or risky in urban and obstacle-rich scenarios, especially when facing adversarial agents with unknown and adaptive behaviors. This paper addresses this challenge as an extended herding problem, where defensive robotic systems must safely guide adversarial agents with unknown strategies away from protected areas and into predetermined safe regions, while maintaining collision-free navigation in dynamic environments. We propose a hierarchical hybrid framework based on reach-avoid game theory and local motion planning, incorporating a virtual containment boundary and event-triggered pursuit mechanisms to enable scalable and robust multi-agent coordination. Simulation results demonstrate that the proposed approach achieves safe and efficient guidance of adversarial agents to designated regions.
Encouraging Good Processes Without the Need for Good Answers: Reinforcement Learning for LLM Agent Planning
Aug 27, 2025The functionality of Large Language Model (LLM) agents is primarily determined by two capabilities: action planning and answer summarization. The former, action planning, is the core capability that dictates an agent's performance. However, prevailing training paradigms employ end-to-end, multi-objective optimization that jointly trains both capabilities. This paradigm faces two critical challenges: imbalanced optimization objective allocation and scarcity of verifiable data, making it difficult to enhance the agent's planning capability. To address these challenges, we propose Reinforcement Learning with Tool-use Rewards (RLTR), a novel framework that decouples the training process to enable a focused, single-objective optimization of the planning module. Crucially, RLTR introduces a reward signal based on tool-use completeness to directly evaluate the quality of tool invocation sequences. This method offers a more direct and reliable training signal than assessing the final response content, thereby obviating the need for verifiable data. Our experiments demonstrate that RLTR achieves an 8%-12% improvement in planning performance compared to end-to-end baselines. Moreover, this enhanced planning capability, in turn, translates to a 5%-6% increase in the final response quality of the overall agent system.
Set Invariance with Probability One for Controlled Diffusion: Score-based Approach
Jul 30, 2025Given a controlled diffusion and a connected, bounded, Lipschitz set, when is it possible to guarantee controlled set invariance with probability one? In this work, we answer this question by deriving the necessary and sufficient conditions for the same in terms of gradients of certain log-likelihoods -- a.k.a. score vector fields -- for two cases: given finite time horizon and infinite time horizon. The deduced conditions comprise a score-based test that provably certifies or falsifies the existence of Markovian controllers for given controlled set invariance problem data. Our results are constructive in the sense when the problem data passes the proposed test, we characterize all controllers guaranteeing the desired set invariance. When the problem data fails the proposed test, there does not exist a controller that can accomplish the desired set invariance with probability one. The computation in the proposed tests involve solving certain Dirichlet boundary value problems, and in the finite horizon case, can also account for additional constraint of hitting a target subset at the terminal time. We illustrate the results using several semi-analytical and numerical examples.
Markov Kernels, Distances and Optimal Control: A Parable of Linear Quadratic Non-Gaussian Distribution Steering
Apr 22, 2025For a controllable linear time-varying (LTV) pair $(\boldsymbol{A}_t,\boldsymbol{B}_t)$ and $\boldsymbol{Q}_{t}$ positive semidefinite, we derive the Markov kernel for the It\^{o} diffusion ${\mathrm{d}}\boldsymbol{x}_{t}=\boldsymbol{A}_{t}\boldsymbol{x}_t {\mathrm{d}} t + \sqrt{2}\boldsymbol{B}_{t}{\mathrm{d}}\boldsymbol{w}_{t}$ with an accompanying killing of probability mass at rate $\frac{1}{2}\boldsymbol{x}^{\top}\boldsymbol{Q}_{t}\boldsymbol{x}$. This Markov kernel is the Green's function for an associated linear reaction-advection-diffusion partial differential equation. Our result generalizes the recently derived kernel for the special case $\left(\boldsymbol{A}_t,\boldsymbol{B}_t\right)=\left(\boldsymbol{0},\boldsymbol{I}\right)$, and depends on the solution of an associated Riccati matrix ODE. A consequence of this result is that the linear quadratic non-Gaussian Schr\"{o}dinger bridge is exactly solvable. This means that the problem of steering a controlled LTV diffusion from a given non-Gaussian distribution to another over a fixed deadline while minimizing an expected quadratic cost can be solved using dynamic Sinkhorn recursions performed with the derived kernel. Our derivation for the $\left(\boldsymbol{A}_t,\boldsymbol{B}_t,\boldsymbol{Q}_t\right)$-parametrized kernel pursues a new idea that relies on finding a state-time dependent distance-like functional given by the solution of a deterministic optimal control problem. This technique breaks away from existing methods, such as generalizing Hermite polynomials or Weyl calculus, which have seen limited success in the reaction-diffusion context. Our technique uncovers a new connection between Markov kernels, distances, and optimal control. This connection is of interest beyond its immediate application in solving the linear quadratic Schr\"{o}dinger bridge problem.
HandSplat: Embedding-Driven Gaussian Splatting for High-Fidelity Hand Rendering
Mar 18, 2025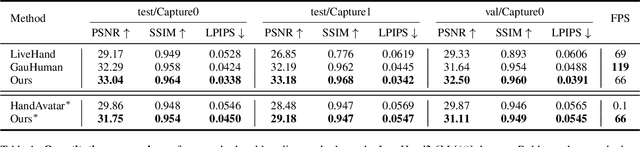
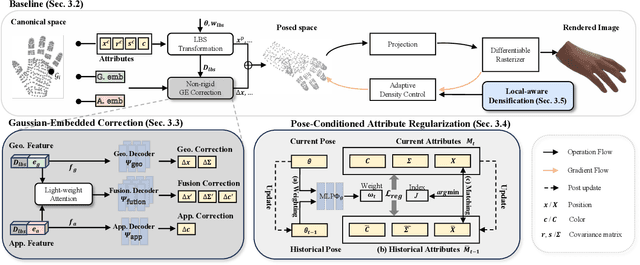
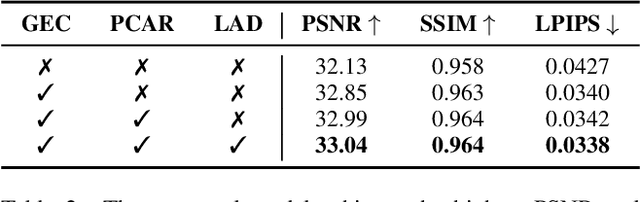

Existing 3D Gaussian Splatting (3DGS) methods for hand rendering rely on rigid skeletal motion with an oversimplified non-rigid motion model, which fails to capture fine geometric and appearance details. Additionally, they perform densification based solely on per-point gradients and process poses independently, ignoring spatial and temporal correlations. These limitations lead to geometric detail loss, temporal instability, and inefficient point distribution. To address these issues, we propose HandSplat, a novel Gaussian Splatting-based framework that enhances both fidelity and stability for hand rendering. To improve fidelity, we extend standard 3DGS attributes with implicit geometry and appearance embeddings for finer non-rigid motion modeling while preserving the static hand characteristic modeled by original 3DGS attributes. Additionally, we introduce a local gradient-aware densification strategy that dynamically refines Gaussian density in high-variation regions. To improve stability, we incorporate pose-conditioned attribute regularization to encourage attribute consistency across similar poses, mitigating temporal artifacts. Extensive experiments on InterHand2.6M demonstrate that HandSplat surpasses existing methods in fidelity and stability while achieving real-time performance. We will release the code and pre-trained models upon acceptance.
Interpersonal Memory Matters: A New Task for Proactive Dialogue Utilizing Conversational History
Mar 07, 2025Proactive dialogue systems aim to empower chatbots with the capability of leading conversations towards specific targets, thereby enhancing user engagement and service autonomy. Existing systems typically target pre-defined keywords or entities, neglecting user attributes and preferences implicit in dialogue history, hindering the development of long-term user intimacy. To address these challenges, we take a radical step towards building a more human-like conversational agent by integrating proactive dialogue systems with long-term memory into a unified framework. Specifically, we define a novel task named Memory-aware Proactive Dialogue (MapDia). By decomposing the task, we then propose an automatic data construction method and create the first Chinese Memory-aware Proactive Dataset (ChMapData). Furthermore, we introduce a joint framework based on Retrieval Augmented Generation (RAG), featuring three modules: Topic Summarization, Topic Retrieval, and Proactive Topic-shifting Detection and Generation, designed to steer dialogues towards relevant historical topics at the right time. The effectiveness of our dataset and models is validated through both automatic and human evaluations. We release the open-source framework and dataset at https://github.com/FrontierLabs/MapDia.