 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-to-3D Gaussian Splatting with Physics-Grounded Motion Generation
Paper and Code
Dec 07, 2024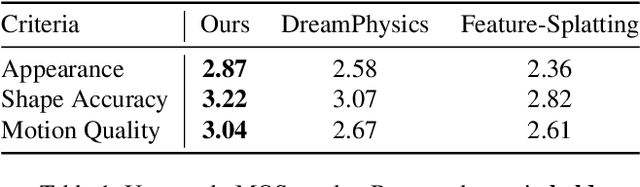
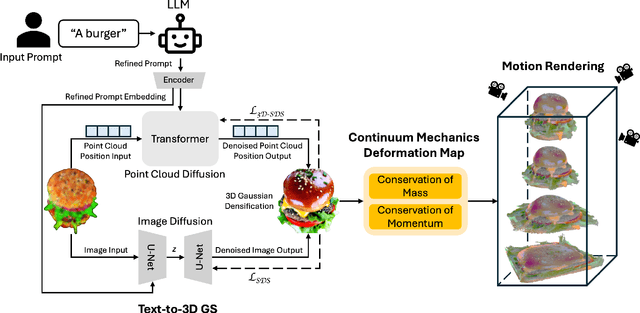
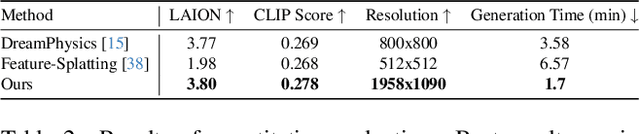

Text-to-3D generation is a valuable technology in virtual reality and digital content creation. While recent works have pushed the boundaries of text-to-3D generation, producing high-fidelity 3D objects with inefficient prompts and simulating their physics-grounded motion accurately still remain unsolved challenges. To address these challenges, we present an innovative framework that utilizes the Large Language Model (LLM)-refined prompts and diffusion priors-guided Gaussian Splatting (GS) for generating 3D models with accurate appearances and geometric structures. We also incorporate a continuum mechanics-based deformation map and color regularization to synthesize vivid physics-grounded motion for the generated 3D Gaussians, adhering to the conservation of mass and momentum. By integrating text-to-3D generation with physics-grounded motion synthesis, our framework renders photo-realistic 3D objects that exhibit physics-aware motion, accurately reflecting the behaviors of the objects under various forces and constraints across different materials. Extensive experiments demonstrate that our approach achieves high-quality 3D generations with realistic physics-grounded motion.