 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpersonal Memory Matters: A New Task for Proactive Dialogue Utilizing Conversational History
Mar 07, 2025Proactive dialogue systems aim to empower chatbots with the capability of leading conversations towards specific targets, thereby enhancing user engagement and service autonomy. Existing systems typically target pre-defined keywords or entities, neglecting user attributes and preferences implicit in dialogue history, hindering the development of long-term user intimacy. To address these challenges, we take a radical step towards building a more human-like conversational agent by integrating proactive dialogue systems with long-term memory into a unified framework. Specifically, we define a novel task named Memory-aware Proactive Dialogue (MapDia). By decomposing the task, we then propose an automatic data construction method and create the first Chinese Memory-aware Proactive Dataset (ChMapData). Furthermore, we introduce a joint framework based on Retrieval Augmented Generation (RAG), featuring three modules: Topic Summarization, Topic Retrieval, and Proactive Topic-shifting Detection and Generation, designed to steer dialogues towards relevant historical topics at the right time. The effectiveness of our dataset and models is validated through both automatic and human evaluations. We release the open-source framework and dataset at https://github.com/FrontierLabs/MapDia.
Improving Conversational Recommender Systems via Knowledge Graph based Semantic Fusion
Jul 08, 2020
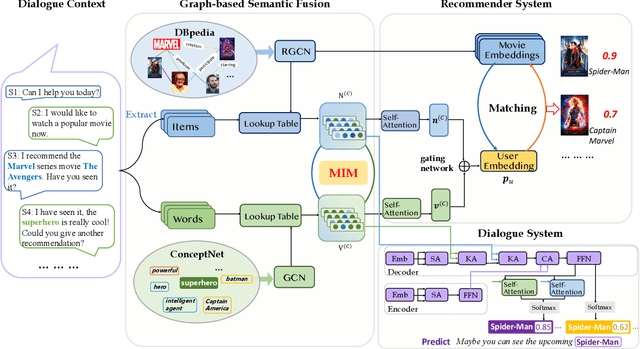
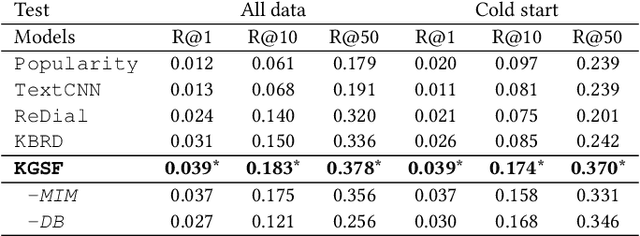
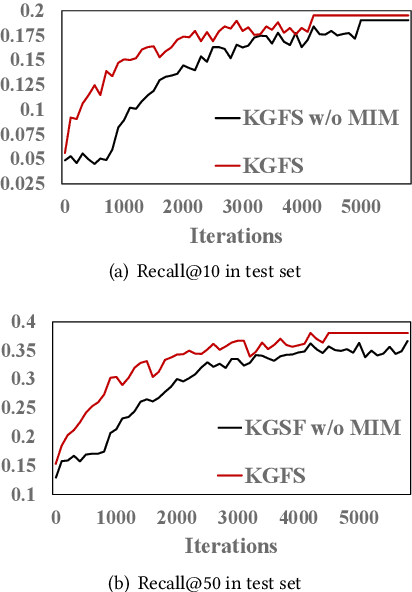
Conversational recommender systems (CRS) aim to recommend high-quality items to users through interactive conversations. Although several efforts have been made for CRS, two major issues still remain to be solved. First, the conversation data itself lacks of sufficient contextual information for accurately understanding users' preference. Second, there is a semantic gap between natural language expression and item-level user preference. To address these issues, we incorporate both word-oriented and entity-oriented knowledge graphs (KG) to enhance the data representations in CRSs, and adopt Mutual Information Maximization to align the word-level and entity-level semantic spaces. Based on the aligned semantic representations, we further develop a KG-enhanced recommender component for making accurate recommendations, and a KG-enhanced dialog component that can generate informative keywords or entities in the response text. Extensive experiments have demonstrated the effectiveness of our approach in yielding better performance on both recommendation and conversation tasks.
Improving Multi-Turn Response Selection Models with Complementary Last-Utterance Selection by Instance Weighting
Feb 18, 2020



Open-domain retrieval-based dialogue systems require a considerable amount of training data to learn their parameters. However, in practice, the negative samples of training data are usually selected from an unannotated conversation data set at random. The generated training data is likely to contain noise and affect the performance of the response selection models. To address this difficulty, we consider utilizing the underlying correlation in the data resource itself to derive different kinds of supervision signals and reduce the influence of noisy data. More specially, we consider a main-complementary task pair. The main task (\ie our focus) selects the correct response given the last utterance and context, and the complementary task selects the last utterance given the response and context. The key point is that the output of the complementary task is used to set instance weights for the main task. We conduct extensive experiments in two public datasets and obtain significant improvement in both datasets. We also investigate the variant of our approach in multiple aspects, and the results have verified the effectiveness of our approach.
Unsupervised Context Rewriting for Open Domain Conversation
Oct 30, 2019
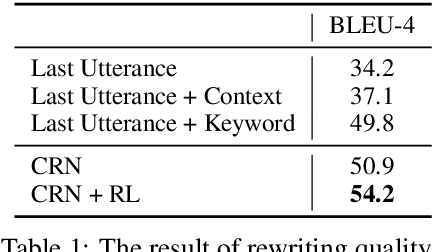
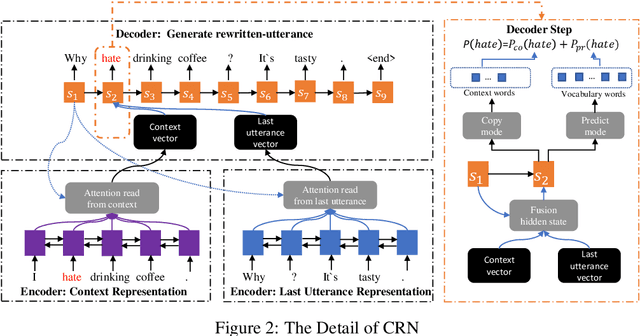
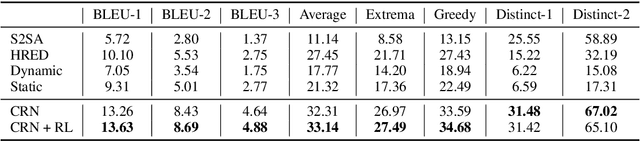
Context modeling has a pivotal role in open domain conversation. Existing works either use heuristic methods or jointly learn context modeling and response generation with an encoder-decoder framework. This paper proposes an explicit context rewriting method, which rewrites the last utterance by considering context history. We leverage pseudo-parallel data and elaborate a context rewriting network, which is built upon the CopyNet with the reinforcement learning method. The rewritten utterance is beneficial to candidate retrieval, explainable context modeling, as well as enabling to employ a single-turn framework to the multi-turn scenario. The empirical results show that our model outperforms baselines in terms of the rewriting quality, the multi-turn response generation, and the end-to-end retrieval-based chatbots.