 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOVO-Bench: How Far is Your Video-LLMs from Real-World Online Video Understanding?
Jan 09, 2025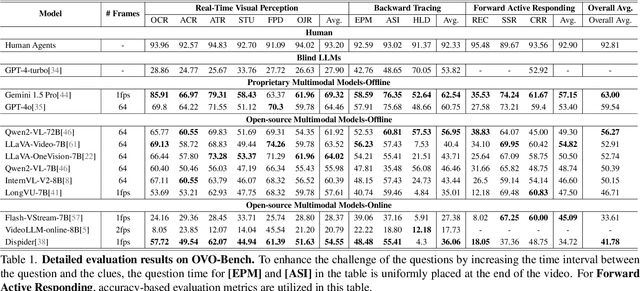
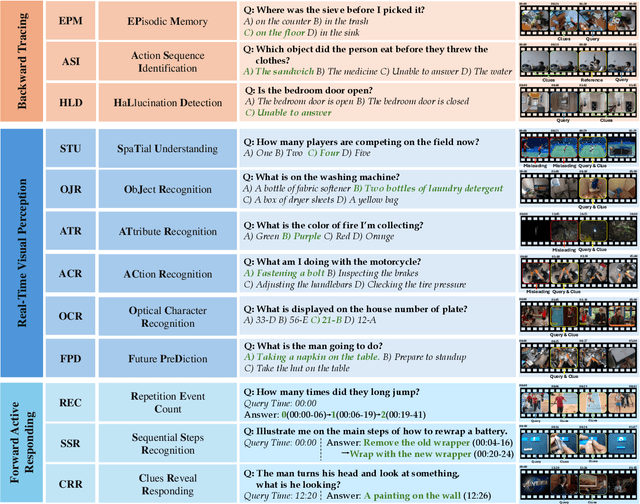
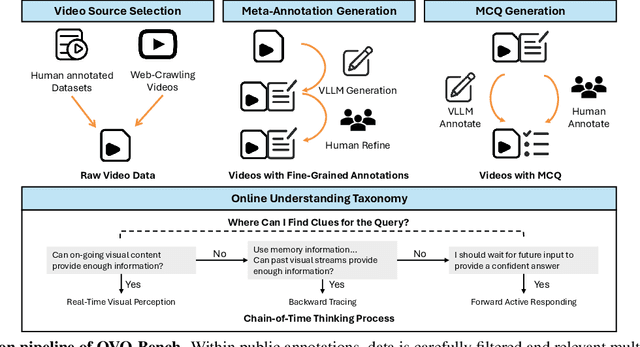
Temporal Awareness, the ability to reason dynamically based on the timestamp when a question is raised, is the key distinction between offline and online video LLMs. Unlike offline models, which rely on complete videos for static, post hoc analysis, online models process video streams incrementally and dynamically adapt their responses based on the timestamp at which the question is posed. Despite its significance, temporal awareness has not been adequately evaluated in existing benchmarks. To fill this gap, we present OVO-Bench (Online-VideO-Benchmark), a novel video benchmark that emphasizes the importance of timestamps for advanced online video understanding capability benchmarking. OVO-Bench evaluates the ability of video LLMs to reason and respond to events occurring at specific timestamps under three distinct scenarios: (1) Backward tracing: trace back to past events to answer the question. (2) Real-time understanding: understand and respond to events as they unfold at the current timestamp. (3) Forward active responding: delay the response until sufficient future information becomes available to answer the question accurately. OVO-Bench comprises 12 tasks, featuring 644 unique videos and approximately human-curated 2,800 fine-grained meta-annotations with precise timestamps. We combine automated generation pipelines with human curation. With these high-quality samples, we further developed an evaluation pipeline to systematically query video LLMs along the video timeline. Evaluations of nine Video-LLMs reveal that, despite advancements on traditional benchmarks, current models struggle with online video understanding, showing a significant gap compared to human agents. We hope OVO-Bench will drive progress in video LLMs and inspire future research in online video reasoning. Our benchmark and code can be accessed at https://github.com/JoeLeelyf/OVO-Bench.
ECAT: A Entire space Continual and Adaptive Transfer Learning Framework for Cross-Domain Recommendation
Jul 02, 2024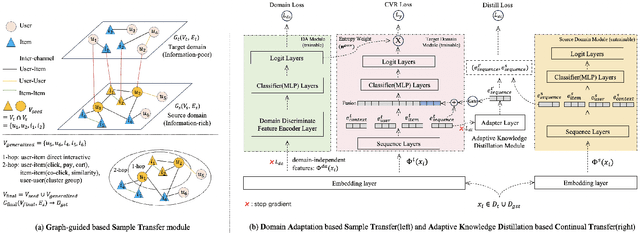
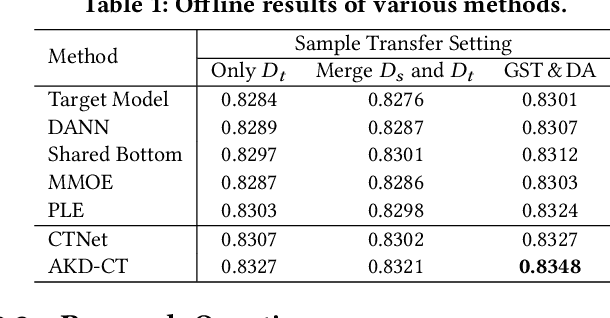

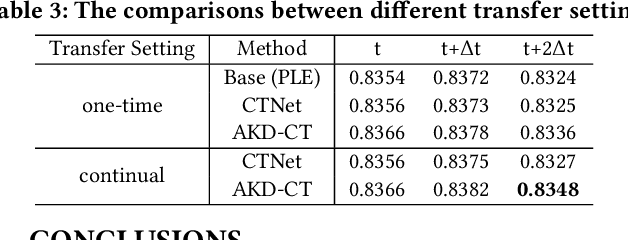
In industrial recommendation systems, there are several mini-apps designed to meet the diverse interests and needs of users. The sample space of them is merely a small subset of the entire space, making it challenging to train an efficient model. In recent years, there have been many excellent studies related to cross-domain recommendation aimed at mitigating the problem of data sparsity. However, few of them have simultaneously considered the adaptability of both sample and representation continual transfer setting to the target task. To overcome the above issue, we propose a Entire space Continual and Adaptive Transfer learning framework called ECAT which includes two core components: First, as for sample transfer, we propose a two-stage method that realizes a coarse-to-fine process. Specifically, we perform an initial selection through a graph-guided method, followed by a fine-grained selection using domain adaptation method. Second, we propose an adaptive knowledge distillation method for continually transferring the representations from a model that is well-trained on the entire space dataset. ECAT enables full utilization of the entire space samples and representations under the supervision of the target task, while avoiding negative migration. Comprehensive experiments on real-world industrial datasets from Taobao show that ECAT advances state-of-the-art performance on offline metrics, and brings +13.6% CVR and +8.6% orders for Baiyibutie, a famous mini-app of Taobao.
JiuZhang 2.0: A Unified Chinese Pre-trained Language Model for Multi-task Mathematical Problem Solving
Jun 19, 2023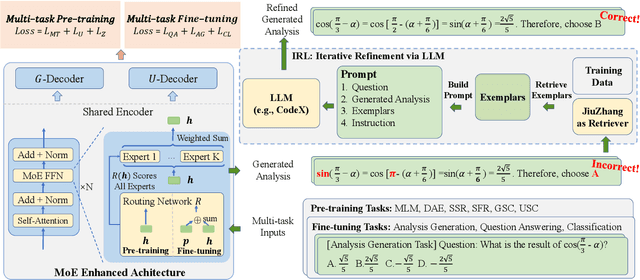
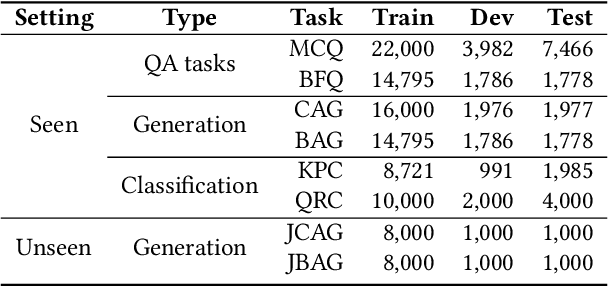
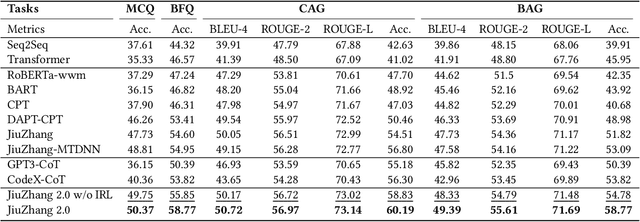
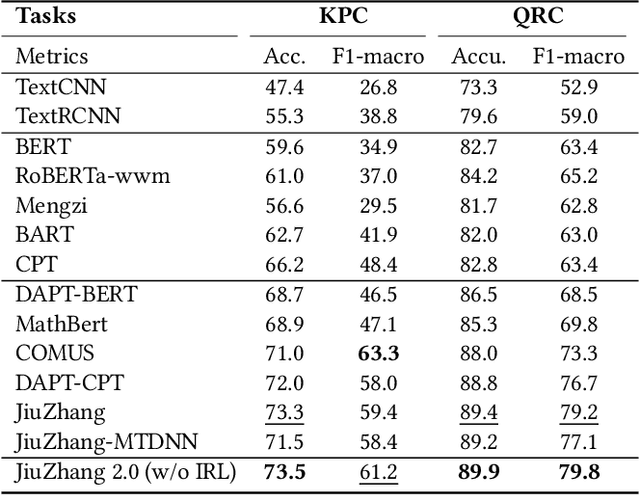
Although pre-trained language models~(PLMs) have recently advanced the research progress in mathematical reasoning, they are not specially designed as a capable multi-task solver, suffering from high cost for multi-task deployment (\eg a model copy for a task) and inferior performance on complex mathematical problems in practical applications. To address these issues, in this paper, we propose \textbf{JiuZhang~2.0}, a unified Chinese PLM specially for multi-task mathematical problem solving. Our idea is to maintain a moderate-sized model and employ the \emph{cross-task knowledge sharing} to improve the model capacity in a multi-task setting. Specially, we construct a Mixture-of-Experts~(MoE) architecture for modeling mathematical text, so as to capture the common mathematical knowledge across tasks. For optimizing the MoE architecture, we design \emph{multi-task continual pre-training} and \emph{multi-task fine-tuning} strategies for multi-task adaptation. These training strategies can effectively decompose the knowledge from the task data and establish the cross-task sharing via expert networks. In order to further improve the general capacity of solving different complex tasks, we leverage large language models~(LLMs) as complementary models to iteratively refine the generated solution by our PLM, via in-context learning. Extensive experiments have demonstrated the effectiveness of our model.
JiuZhang: A Chinese Pre-trained Language Model for Mathematical Problem Understanding
Jun 13, 2022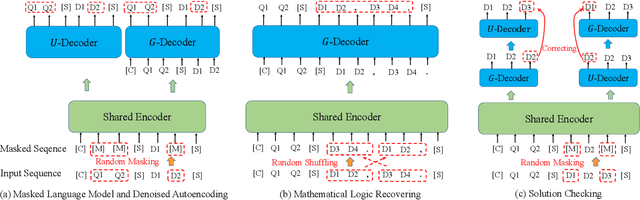
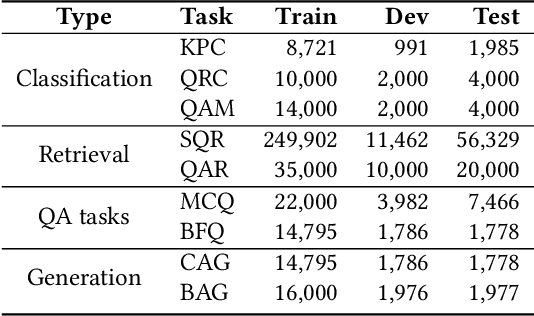
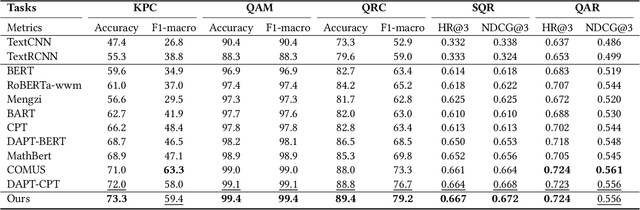

This paper aims to advance the mathematical intelligence of machines by presenting the first Chinese mathematical pre-trained language model~(PLM) for effectively understanding and representing mathematical problems. Unlike other standard NLP tasks, mathematical texts are difficult to understand, since they involve mathematical terminology, symbols and formulas in the problem statement. Typically, it requires complex mathematical logic and background knowledge for solving mathematical problems. Considering the complex nature of mathematical texts, we design a novel curriculum pre-training approach for improving the learning of mathematical PLMs, consisting of both basic and advanced courses. Specially, we first perform token-level pre-training based on a position-biased masking strategy, and then design logic-based pre-training tasks that aim to recover the shuffled sentences and formulas, respectively. Finally, we introduce a more difficult pre-training task that enforces the PLM to detect and correct the errors in its generated solutions. We conduct extensive experiments on offline evaluation (including nine math-related tasks) and online $A/B$ test. Experimental results demonstrate the effectiveness of our approach compared with a number of competitive baselines. Our code is available at: \textcolor{blue}{\url{https://github.com/RUCAIBox/JiuZhang}}.
C2-CRS: Coarse-to-Fine Contrastive Learning for Conversational Recommender System
Jan 04, 2022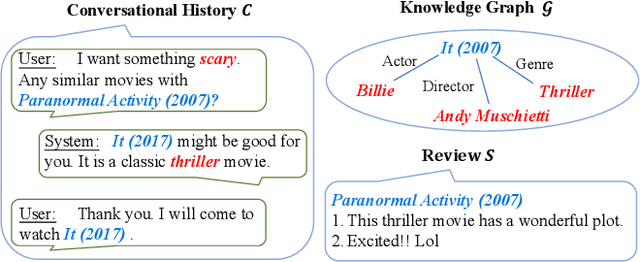
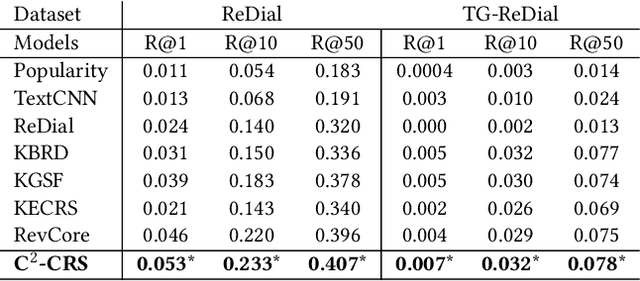
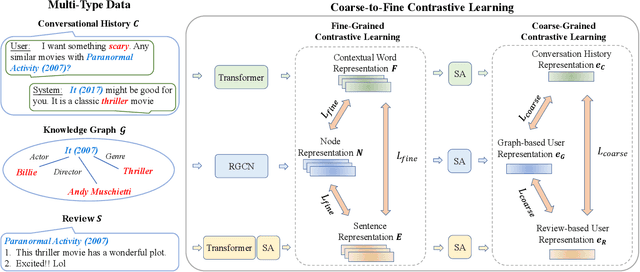
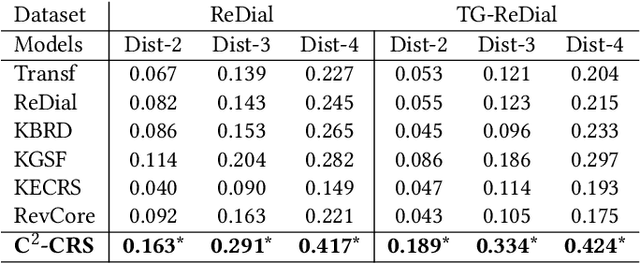
Conversational recommender systems (CRS) aim to recommend suitable items to users through natural language conversations. For developing effective CRSs, a major technical issue is how to accurately infer user preference from very limited conversation context. To address issue, a promising solution is to incorporate external data for enriching the context information. However, prior studies mainly focus on designing fusion models tailored for some specific type of external data, which is not general to model and utilize multi-type external data. To effectively leverage multi-type external data, we propose a novel coarse-to-fine contrastive learning framework to improve data semantic fusion for CRS. In our approach, we first extract and represent multi-grained semantic units from different data signals, and then align the associated multi-type semantic units in a coarse-to-fine way. To implement this framework, we design both coarse-grained and fine-grained procedures for modeling user preference, where the former focuses on more general, coarse-grained semantic fusion and the latter focuses on more specific, fine-grained semantic fusion. Such an approach can be extended to incorporate more kinds of external data. Extensive experiments on two public CRS datasets have demonstrated the effectiveness of our approach in both recommendation and conversation tasks.
CRSLab: An Open-Source Toolkit for Building Conversational Recommender System
Jan 04, 2021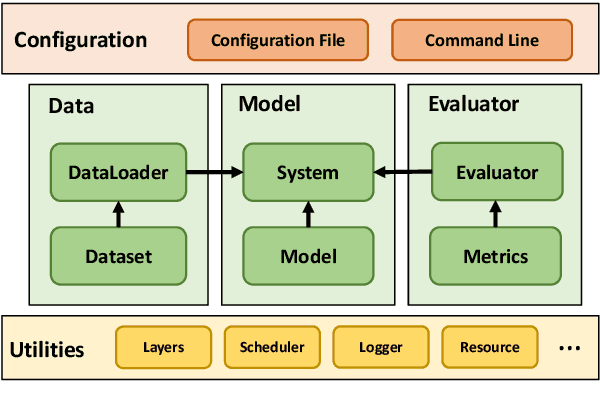
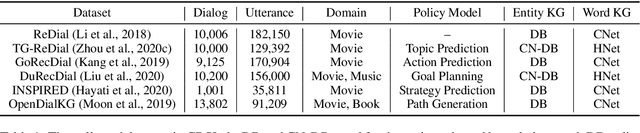
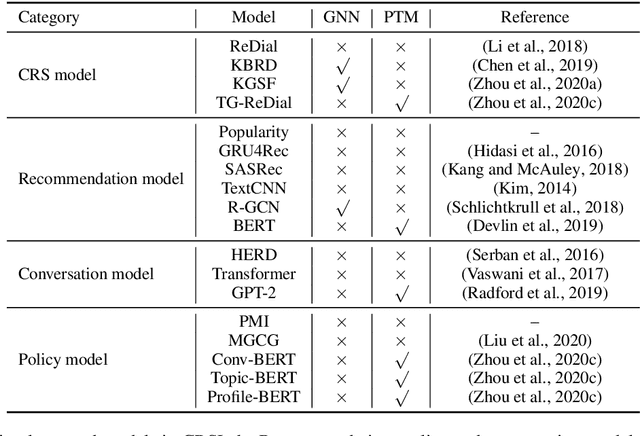
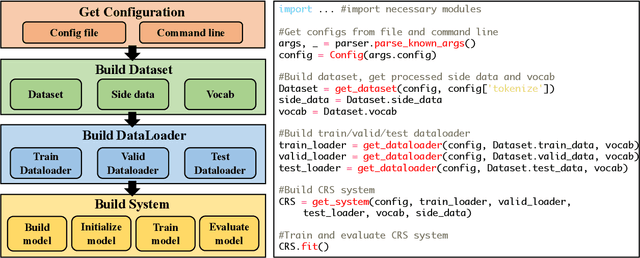
In recent years, conversational recommender system (CRS) has received much attention in the research community. However, existing studies on CRS vary in scenarios, goals and techniques, lacking unified, standardized implementation or comparison. To tackle this challenge, we propose an open-source CRS toolkit CRSLab, which provides a unified and extensible framework with highly-decoupled modules to develop CRSs. Based on this framework, we collect 6 commonly-used human-annotated CRS datasets and implement 18 models that include recent techniques such as graph neural network and pre-training models. Besides, our toolkit provides a series of automatic evaluation protocols and a human-machine interaction interface to test and compare different CRS methods. The project and documents are released at https://github.com/RUCAIBox/CRSLab.
Towards Topic-Guided Conversational Recommender System
Oct 08, 2020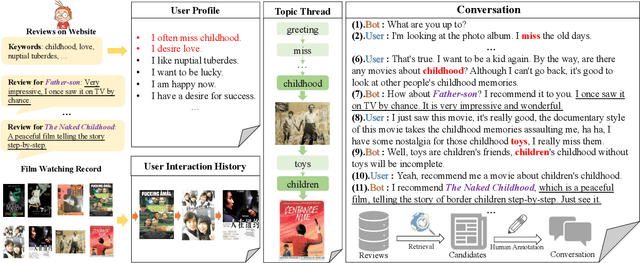
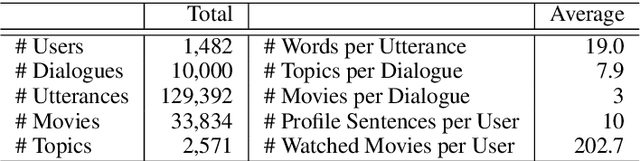
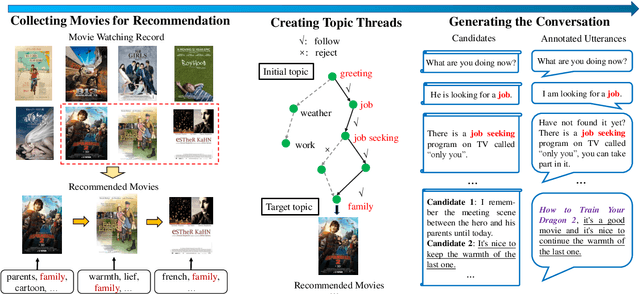
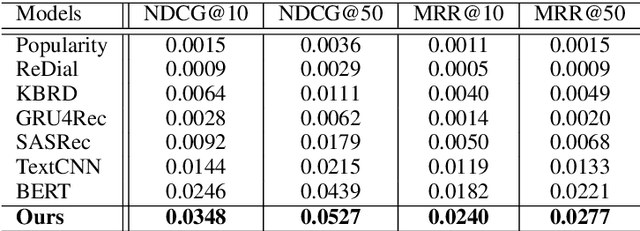
Conversational recommender systems (CRS) aim to recommend high-quality items to users through interactive conversations. To develop an effective CRS, the support of high-quality datasets is essential. Existing CRS datasets mainly focus on immediate requests from users, while lack proactive guidance to the recommendation scenario. In this paper, we contribute a new CRS dataset named \textbf{TG-ReDial} (\textbf{Re}commendation through \textbf{T}opic-\textbf{G}uided \textbf{Dial}og). Our dataset has two major features. First, it incorporates topic threads to enforce natural semantic transitions towards the recommendation scenario. Second, it is created in a semi-automatic way, hence human annotation is more reasonable and controllable. Based on TG-ReDial, we present the task of topic-guided conversational recommendation, and propose an effective approach to this task. Extensive experiments have demonstrated the effectiveness of our approach on three sub-tasks, namely topic prediction, item recommendation and response generation. TG-ReDial is available at https://github.com/RUCAIBox/TG-ReDial.
Improving Conversational Recommender Systems via Knowledge Graph based Semantic Fusion
Jul 08, 2020
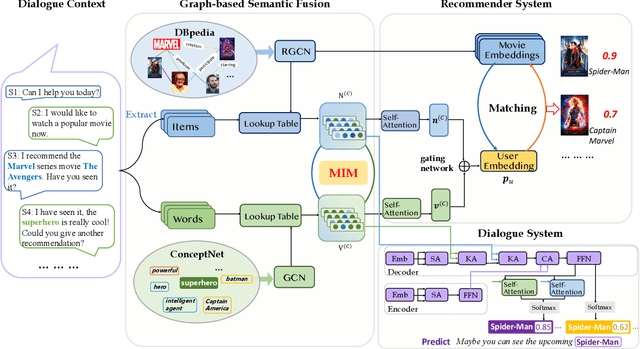
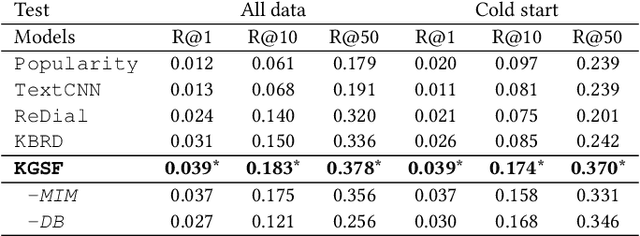
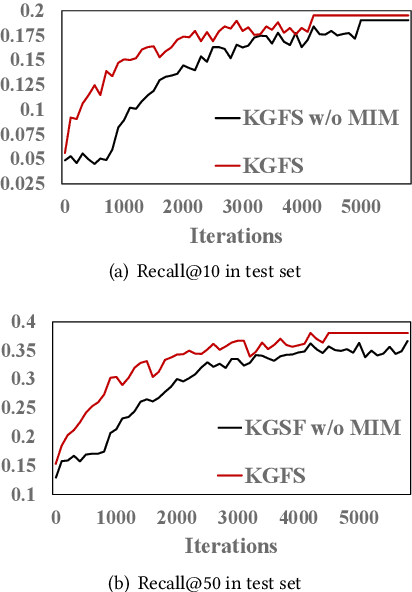
Conversational recommender systems (CRS) aim to recommend high-quality items to users through interactive conversations. Although several efforts have been made for CRS, two major issues still remain to be solved. First, the conversation data itself lacks of sufficient contextual information for accurately understanding users' preference. Second, there is a semantic gap between natural language expression and item-level user preference. To address these issues, we incorporate both word-oriented and entity-oriented knowledge graphs (KG) to enhance the data representations in CRSs, and adopt Mutual Information Maximization to align the word-level and entity-level semantic spaces. Based on the aligned semantic representations, we further develop a KG-enhanced recommender component for making accurate recommendations, and a KG-enhanced dialog component that can generate informative keywords or entities in the response text. Extensive experiments have demonstrated the effectiveness of our approach in yielding better performance on both recommendation and conversation tasks.