 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Knowledge Editing for Information Enrichment and Probability Promotion
Dec 22, 2024Knowledge stored in large language models requires timely updates to reflect the dynamic nature of real-world information. To update the knowledge, most knowledge editing methods focus on the low layers, since recent probes into the knowledge recall process reveal that the answer information is enriched in low layers. However, these probes only and could only reveal critical recall stages for the original answers, while the goal of editing is to rectify model's prediction for the target answers. This inconsistency indicates that both the probe approaches and the associated editing methods are deficient. To mitigate the inconsistency and identify critical editing regions, we propose a contrast-based probe approach, and locate two crucial stages where the model behavior diverges between the original and target answers: Information Enrichment in low layers and Probability Promotion in high layers. Building upon the insights, we develop the Joint knowledge Editing for information Enrichment and probability Promotion (JEEP) method, which jointly edits both the low and high layers to modify the two critical recall stages. Considering the mutual interference and growing forgetting due to dual modifications, JEEP is designed to ensure that updates to distinct regions share the same objectives and are complementary. We rigorously evaluate JEEP by editing up to thousands of facts on various models, i.e., GPT-J (6B) and LLaMA (7B), and addressing diverse editing objectives, i.e., adding factual and counterfactual knowledge. In all tested scenarios, JEEP achieves best performances, validating the effectiveness of the revealings of our probe approach and the designs of our editing method. Our code and data are available at https://github.com/Eric8932/JEEP.
Universal Multi-modal Multi-domain Pre-trained Recommendation
Nov 03, 2023There is a rapidly-growing research interest in modeling user preferences via pre-training multi-domain interactions for recommender systems. However, Existing pre-trained multi-domain recommendations mostly select the item texts to be bridges across domains, and simply explore the user behaviors in target domains. Hence, they ignore other informative multi-modal item contents (e.g., visual information), and also lack of thorough consideration of user behaviors from all interactive domains. To address these issues, in this paper, we propose to pre-train universal multi-modal item content presentation for multi-domain recommendation, called UniM^2Rec, which could smoothly learn the multi-modal item content presentations and the multi-modal user preferences from all domains. With the pre-trained multi-domain recommendation model, UniM^2Rec could be efficiently and effectively transferred to new target domains in practice. Extensive experiments conducted on five real-world datasets in target domains demonstrate the superiority of the proposed method over existing competitive methods, especially for the real-world recommendation scenarios that usually struggle with seriously missing or noisy item contents.
RecBole 2.0: Towards a More Up-to-Date Recommendation Library
Jun 16, 2022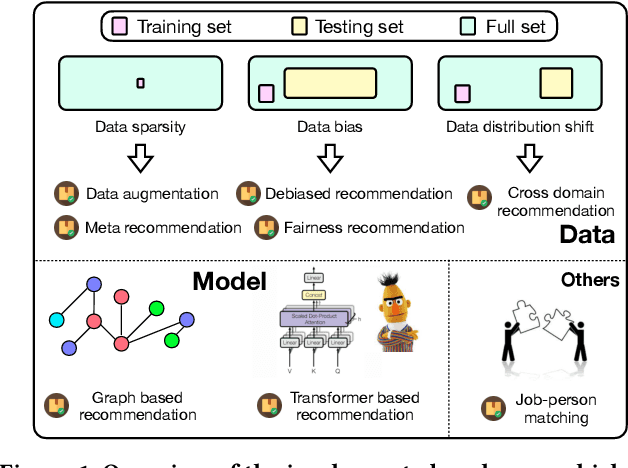
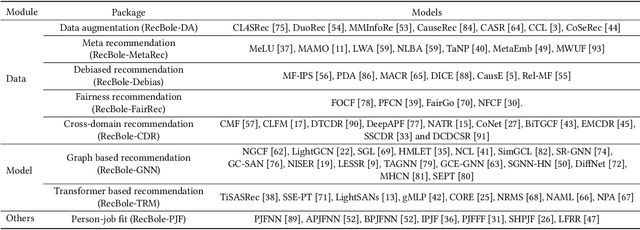

In order to support the study of recent advances in recommender systems, this paper presents an extended recommendation library consisting of eight packages for up-to-date topics and architectures. First of all, from a data perspective, we consider three important topics related to data issues (i.e., sparsity, bias and distribution shift), and develop five packages accordingly: meta-learning, data augmentation, debiasing, fairness and cross-domain recommendation. Furthermore, from a model perspective, we develop two benchmarking packages for Transformer-based and graph neural network (GNN)-based models, respectively. All the packages (consisting of 65 new models) are developed based on a popular recommendation framework RecBole, ensuring that both the implementation and interface are unified. For each package, we provide complete implementations from data loading, experimental setup, evaluation and algorithm implementation. This library provides a valuable resource to facilitate the up-to-date research in recommender systems. The project is released at the link: https://github.com/RUCAIBox/RecBole2.0.
Leveraging Search History for Improving Person-Job Fit
Mar 27, 2022As the core technique of online recruitment platforms, person-job fit can improve hiring efficiency by accurately matching job positions with qualified candidates. However, existing studies mainly focus on the recommendation scenario, while neglecting another important channel for linking positions with job seekers, i.e. search. Intuitively, search history contains rich user behavior in job seeking, reflecting important evidence for job intention of users. In this paper, we present a novel Search History enhanced Person-Job Fit model, named as SHPJF. To utilize both text content from jobs/resumes and search histories from users, we propose two components with different purposes. For text matching component, we design a BERT-based text encoder for capturing the semantic interaction between resumes and job descriptions. For intention modeling component, we design two kinds of intention modeling approaches based on the Transformer architecture, either based on the click sequence or query text sequence. To capture underlying job intentions, we further propose an intention clustering technique to identify and summarize the major intentions from search logs. Extensive experiments on a large real-world recruitment dataset have demonstrated the effectiveness of our approach.
Learning to Match Jobs with Resumes from Sparse Interaction Data using Multi-View Co-Teaching Network
Sep 25, 2020



With the ever-increasing growth of online recruitment data, job-resume matching has become an important task to automatically match jobs with suitable resumes. This task is typically casted as a supervised text matching problem. Supervised learning is powerful when the labeled data is sufficient. However, on online recruitment platforms, job-resume interaction data is sparse and noisy, which affects the performance of job-resume match algorithms. To alleviate these problems, in this paper, we propose a novel multi-view co-teaching network from sparse interaction data for job-resume matching. Our network consists of two major components, namely text-based matching model and relation-based matching model. The two parts capture semantic compatibility in two different views, and complement each other. In order to address the challenges from sparse and noisy data, we design two specific strategies to combine the two components. First, two components share the learned parameters or representations, so that the original representations of each component can be enhanced. More importantly, we adopt a co-teaching mechanism to reduce the influence of noise in training data. The core idea is to let the two components help each other by selecting more reliable training instances. The two strategies focus on representation enhancement and data enhancement, respectively. Compared with pure text-based matching models, the proposed approach is able to learn better data representations from limited or even sparse interaction data, which is more resistible to noise in training data. Experiment results have demonstrated that our model is able to outperform state-of-the-art methods for job-resume matching.
Improving Conversational Recommender Systems via Knowledge Graph based Semantic Fusion
Jul 08, 2020
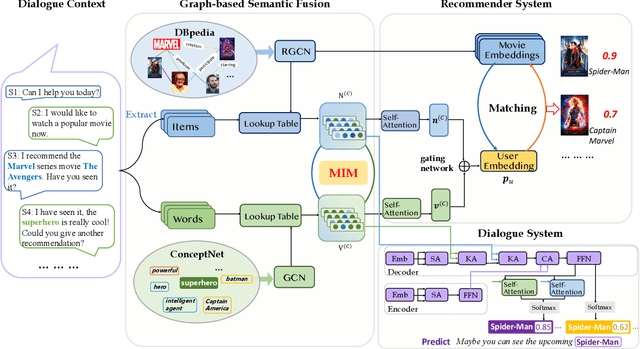
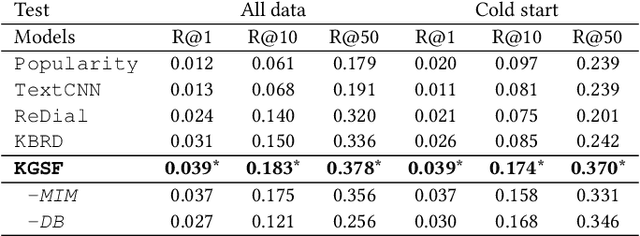
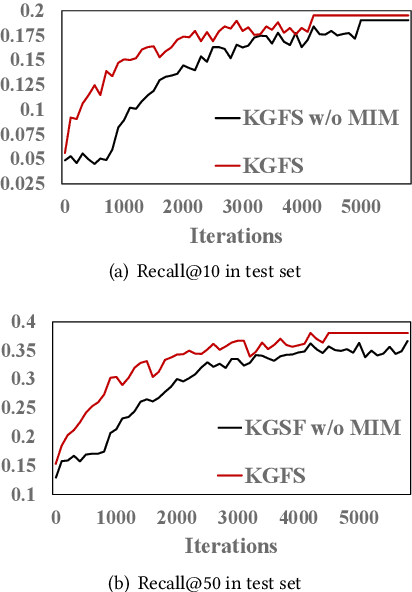
Conversational recommender systems (CRS) aim to recommend high-quality items to users through interactive conversations. Although several efforts have been made for CRS, two major issues still remain to be solved. First, the conversation data itself lacks of sufficient contextual information for accurately understanding users' preference. Second, there is a semantic gap between natural language expression and item-level user preference. To address these issues, we incorporate both word-oriented and entity-oriented knowledge graphs (KG) to enhance the data representations in CRSs, and adopt Mutual Information Maximization to align the word-level and entity-level semantic spaces. Based on the aligned semantic representations, we further develop a KG-enhanced recommender component for making accurate recommendations, and a KG-enhanced dialog component that can generate informative keywords or entities in the response text. Extensive experiments have demonstrated the effectiveness of our approach in yielding better performance on both recommendation and conversation tasks.
IcoRating: A Deep-Learning System for Scam ICO Identification
Mar 08, 2018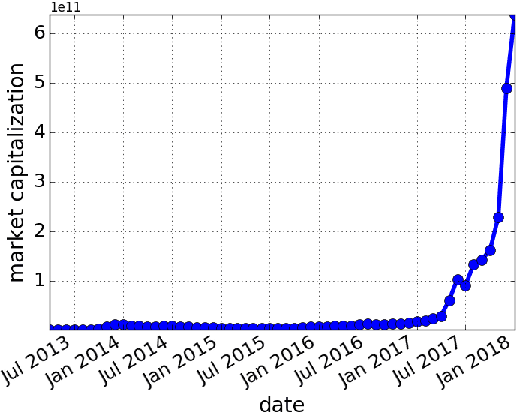
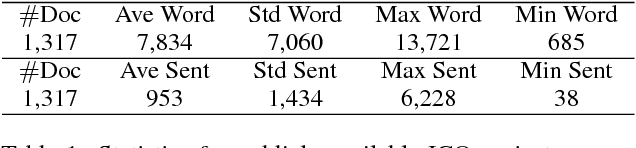
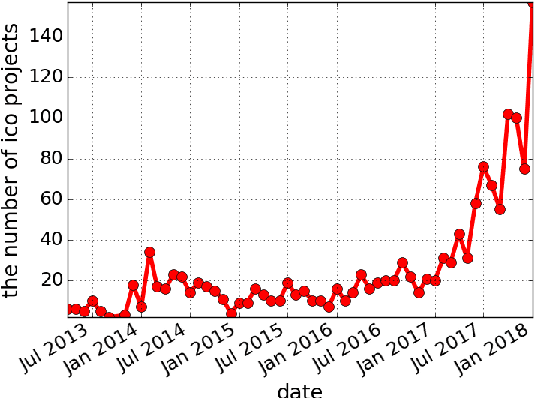
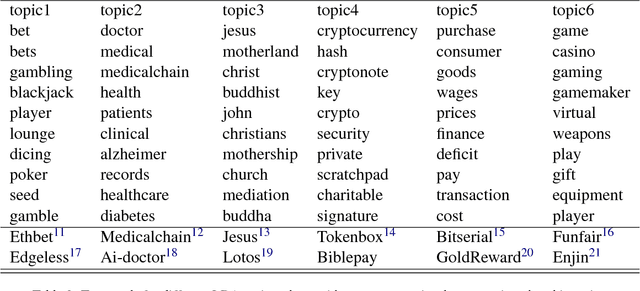
Cryptocurrencies (or digital tokens, digital currencies, e.g., BTC, ETH, XRP, NEO) have been rapidly gaining ground in use, value, and understanding among the public, bringing astonishing profits to investors. Unlike other money and banking systems, most digital tokens do not require central authorities. Being decentralized poses significant challenges for credit rating. Most ICOs are currently not subject to government regulations, which makes a reliable credit rating system for ICO projects necessary and urgent. In this paper, we introduce IcoRating, the first learning--based cryptocurrency rating system. We exploit natural-language processing techniques to analyze various aspects of 2,251 digital currencies to date, such as white paper content, founding teams, Github repositories, websites, etc. Supervised learning models are used to correlate the life span and the price change of cryptocurrencies with these features. For the best setting, the proposed system is able to identify scam ICO projects with 0.83 precision. We hope this work will help investors identify scam ICOs and attract more efforts in automatically evaluating and analyzing ICO projects.