 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhoSaidIt: Human-LLM Collaborative Annotation for Text-Based Multilingual Speaker-Attribute Classification
May 25, 2026Annotating speaker attributes from text is inherently ambiguous, particularly in multilingual settings where demographic and social cues are implicit and culturally variable. We propose a human-large language model (LLM) collaborative re-annotation framework for stabilizing multilingual speaker-attribute labels under practical resource constraints. Starting from a noisy corpus, we use LLMs to surface recurring annotation rationales through iterative interaction with experts, and apply disagreement-focused sampling for targeted re-annotation. Using this framework, we construct WhoSaidIt, a multilingual dataset covering nine speaker-attribute labels. We quantify divergence between original and revised annotations, benchmark recent LLMs, and analyze the effect of explicit rationales on model behavior. Our results reveal substantial cross-lingual differences in annotation decisions and demonstrate both the strengths and limitations of LLMs in speaker-attribute classification.
Generating Bilingual Pragmatic Color References
May 19, 2018



Contextual influences on language often exhibit substantial cross-lingual regularities; for example, we are more verbose in situations that require finer distinctions. However, these regularities are sometimes obscured by semantic and syntactic differences. Using a newly-collected dataset of color reference games in Mandarin Chinese (which we release to the public), we confirm that a variety of constructions display the same sensitivity to contextual difficulty in Chinese and English. We then show that a neural speaker agent trained on bilingual data with a simple multitask learning approach displays more human-like patterns of context dependence and is more pragmatically informative than its monolingual Chinese counterpart. Moreover, this is not at the expense of language-specific semantic understanding: the resulting speaker model learns the different basic color term systems of English and Chinese (with noteworthy cross-lingual influences), and it can identify synonyms between the two languages using vector analogy operations on its output layer, despite having no exposure to parallel data.
IcoRating: A Deep-Learning System for Scam ICO Identification
Mar 08, 2018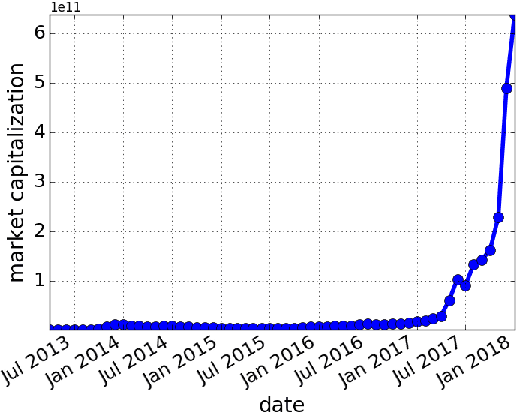
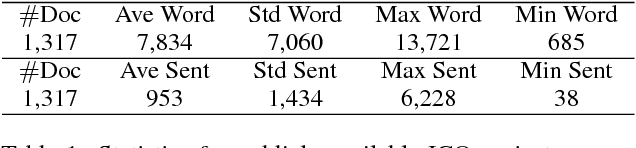
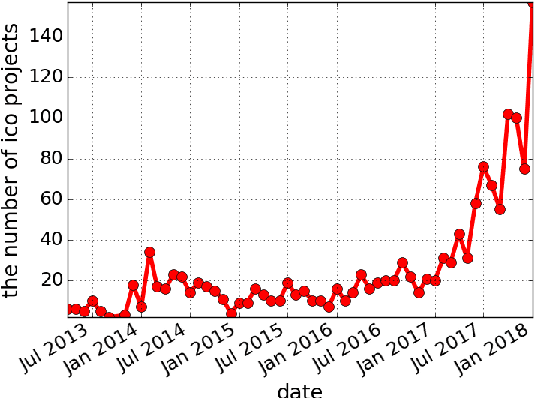
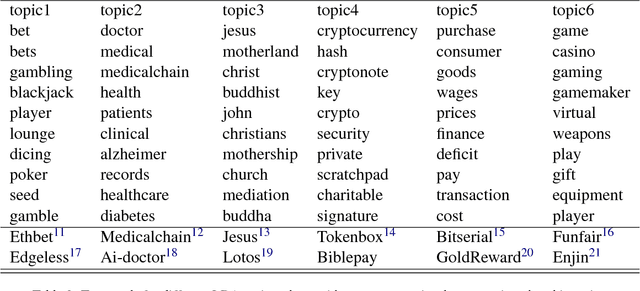
Cryptocurrencies (or digital tokens, digital currencies, e.g., BTC, ETH, XRP, NEO) have been rapidly gaining ground in use, value, and understanding among the public, bringing astonishing profits to investors. Unlike other money and banking systems, most digital tokens do not require central authorities. Being decentralized poses significant challenges for credit rating. Most ICOs are currently not subject to government regulations, which makes a reliable credit rating system for ICO projects necessary and urgent. In this paper, we introduce IcoRating, the first learning--based cryptocurrency rating system. We exploit natural-language processing techniques to analyze various aspects of 2,251 digital currencies to date, such as white paper content, founding teams, Github repositories, websites, etc. Supervised learning models are used to correlate the life span and the price change of cryptocurrencies with these features. For the best setting, the proposed system is able to identify scam ICO projects with 0.83 precision. We hope this work will help investors identify scam ICOs and attract more efforts in automatically evaluating and analyzing ICO projects.
Adversarial Learning for Neural Dialogue Generation
Sep 24, 2017
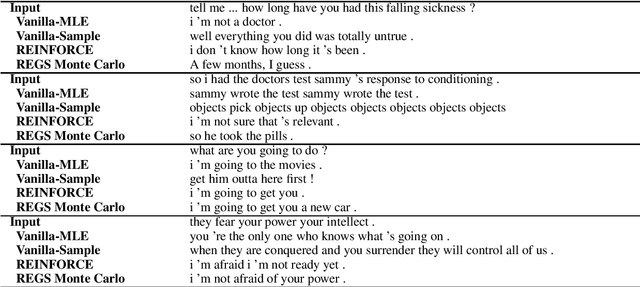

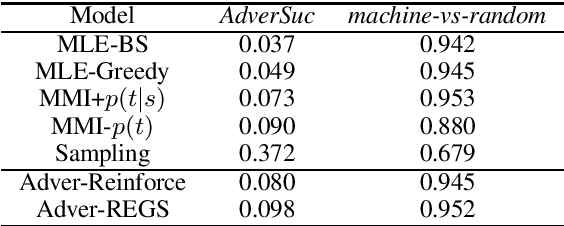
In this paper, drawing intuition from the Turing test, we propose using adversarial training for open-domain dialogue generation: the system is trained to produce sequences that are indistinguishable from human-generated dialogue utterances. We cast the task as a reinforcement learning (RL) problem where we jointly train two systems, a generative model to produce response sequences, and a discriminator---analagous to the human evaluator in the Turing test--- to distinguish between the human-generated dialogues and the machine-generated ones. The outputs from the discriminator are then used as rewards for the generative model, pushing the system to generate dialogues that mostly resemble human dialogues. In addition to adversarial training we describe a model for adversarial {\em evaluation} that uses success in fooling an adversary as a dialogue evaluation metric, while avoiding a number of potential pitfalls. Experimental results on several metrics, including adversarial evaluation, demonstrate that the adversarially-trained system generates higher-quality responses than previous baselines.
Colors in Context: A Pragmatic Neural Model for Grounded Language Understanding
May 16, 2017We present a model of pragmatic referring expression interpretation in a grounded communication task (identifying colors from descriptions) that draws upon predictions from two recurrent neural network classifiers, a speaker and a listener, unified by a recursive pragmatic reasoning framework. Experiments show that this combined pragmatic model interprets color descriptions more accurately than the classifiers from which it is built, and that much of this improvement results from combining the speaker and listener perspectives. We observe that pragmatic reasoning helps primarily in the hardest cases: when the model must distinguish very similar colors, or when few utterances adequately express the target color. Our findings make use of a newly-collected corpus of human utterances in color reference games, which exhibit a variety of pragmatic behaviors. We also show that the embedded speaker model reproduces many of these pragmatic behaviors.
Data Distillation for Controlling Specificity in Dialogue Generation
Feb 22, 2017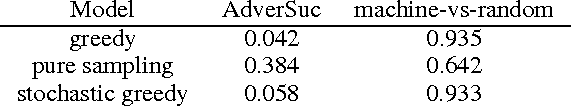
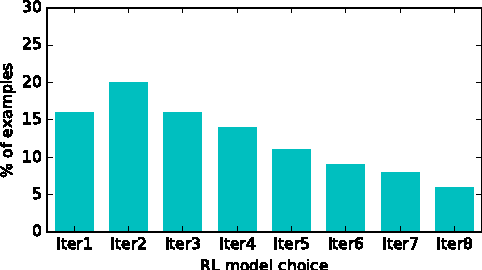
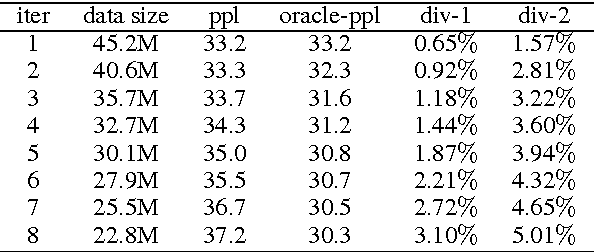
People speak at different levels of specificity in different situations. Depending on their knowledge, interlocutors, mood, etc.} A conversational agent should have this ability and know when to be specific and when to be general. We propose an approach that gives a neural network--based conversational agent this ability. Our approach involves alternating between \emph{data distillation} and model training : removing training examples that are closest to the responses most commonly produced by the model trained from the last round and then retrain the model on the remaining dataset. Dialogue generation models trained with different degrees of data distillation manifest different levels of specificity. We then train a reinforcement learning system for selecting among this pool of generation models, to choose the best level of specificity for a given input. Compared to the original generative model trained without distillation, the proposed system is capable of generating more interesting and higher-quality responses, in addition to appropriately adjusting specificity depending on the context. Our research constitutes a specific case of a broader approach involving training multiple subsystems from a single dataset distinguished by differences in a specific property one wishes to model. We show that from such a set of subsystems, one can use reinforcement learning to build a system that tailors its output to different input contexts at test time.
Learning to Decode for Future Success
Feb 03, 2017
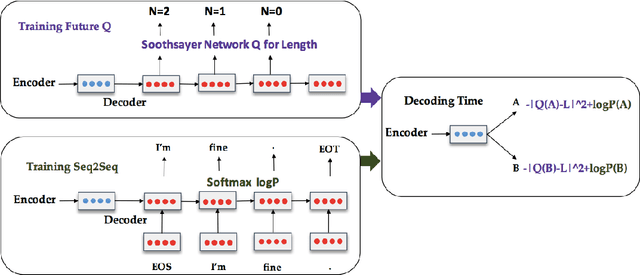


We introduce a simple, general strategy to manipulate the behavior of a neural decoder that enables it to generate outputs that have specific properties of interest (e.g., sequences of a pre-specified length). The model can be thought of as a simple version of the actor-critic model that uses an interpolation of the actor (the MLE-based token generation policy) and the critic (a value function that estimates the future values of the desired property) for decision making. We demonstrate that the approach is able to incorporate a variety of properties that cannot be handled by standard neural sequence decoders, such as sequence length and backward probability (probability of sources given targets), in addition to yielding consistent improvements in abstractive summarization and machine translation when the property to be optimized is BLEU or ROUGE scores.
Understanding Neural Networks through Representation Erasure
Jan 10, 2017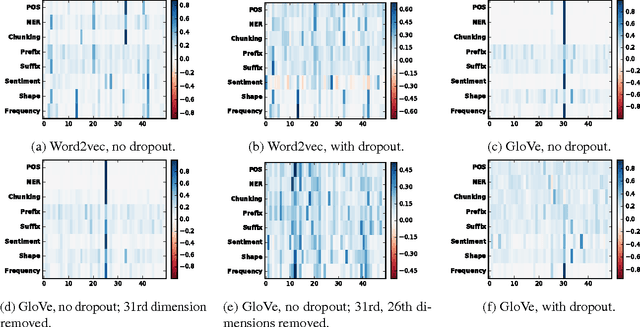

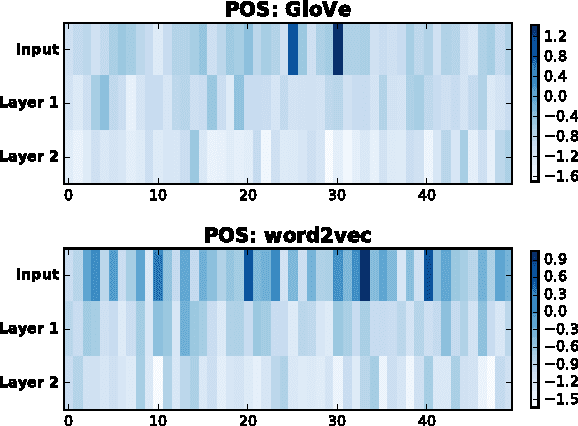

While neural networks have been successfully applied to many natural language processing tasks, they come at the cost of interpretability. In this paper, we propose a general methodology to analyze and interpret decisions from a neural model by observing the effects on the model of erasing various parts of the representation, such as input word-vector dimensions, intermediate hidden units, or input words. We present several approaches to analyzing the effects of such erasure, from computing the relative difference in evaluation metrics, to using reinforcement learning to erase the minimum set of input words in order to flip a neural model's decision. In a comprehensive analysis of multiple NLP tasks, including linguistic feature classification, sentence-level sentiment analysis, and document level sentiment aspect prediction, we show that the proposed methodology not only offers clear explanations about neural model decisions, but also provides a way to conduct error analysis on neural models.
A Simple, Fast Diverse Decoding Algorithm for Neural Generation
Dec 22, 2016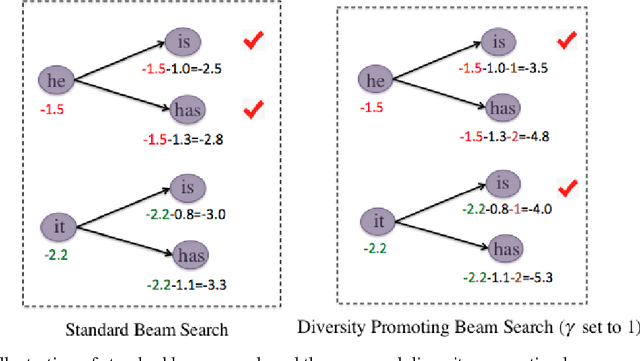
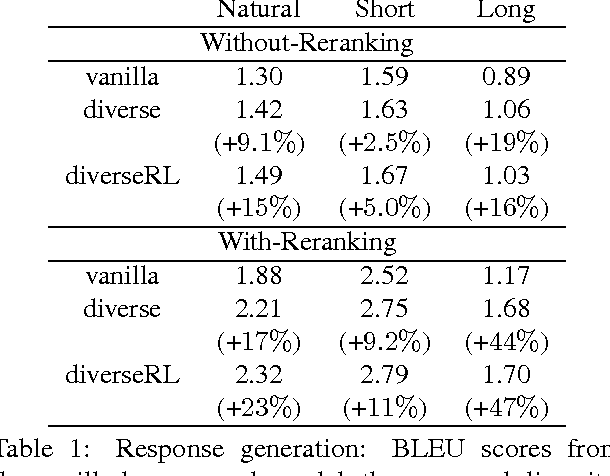
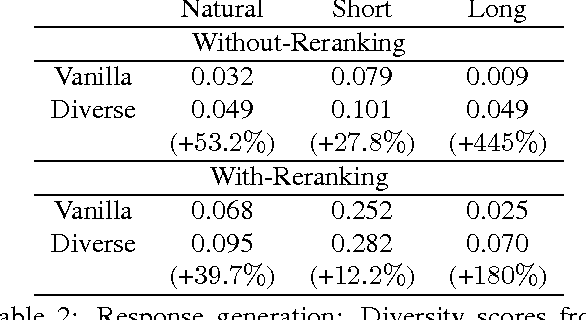
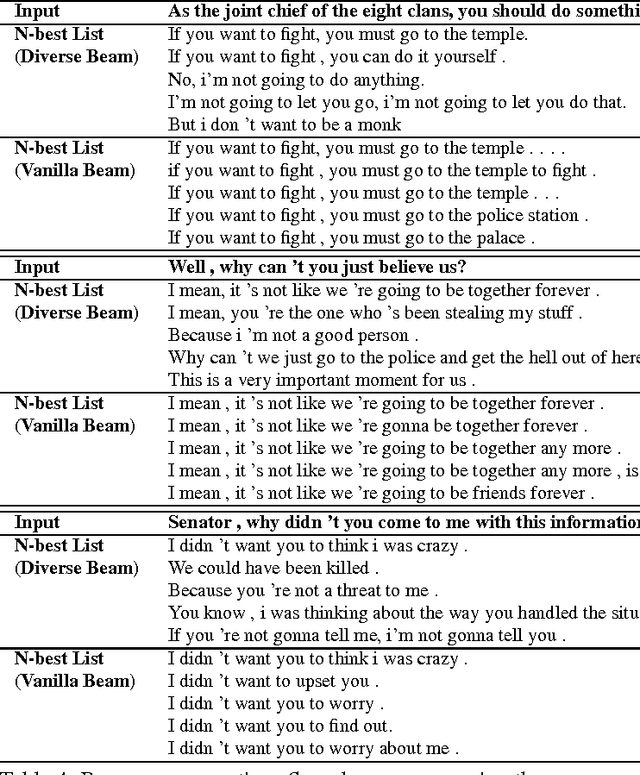
In this paper, we propose a simple, fast decoding algorithm that fosters diversity in neural generation. The algorithm modifies the standard beam search algorithm by adding an inter-sibling ranking penalty, favoring choosing hypotheses from diverse parents. We evaluate the proposed model on the tasks of dialogue response generation, abstractive summarization and machine translation. We find that diverse decoding helps across all tasks, especially those for which reranking is needed. We further propose a variation that is capable of automatically adjusting its diversity decoding rates for different inputs using reinforcement learning (RL). We observe a further performance boost from this RL technique. This paper includes material from the unpublished script "Mutual Information and Diverse Decoding Improve Neural Machine Translation" (Li and Jurafsky, 2016).
Learning to Generate Compositional Color Descriptions
Oct 18, 2016
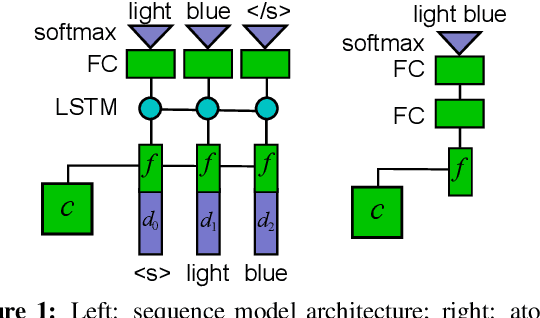
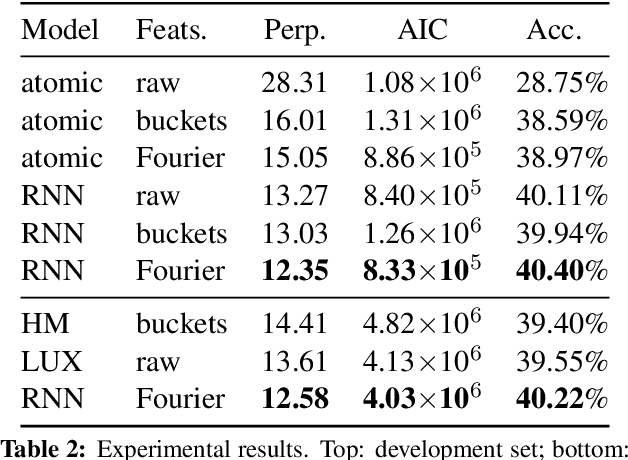
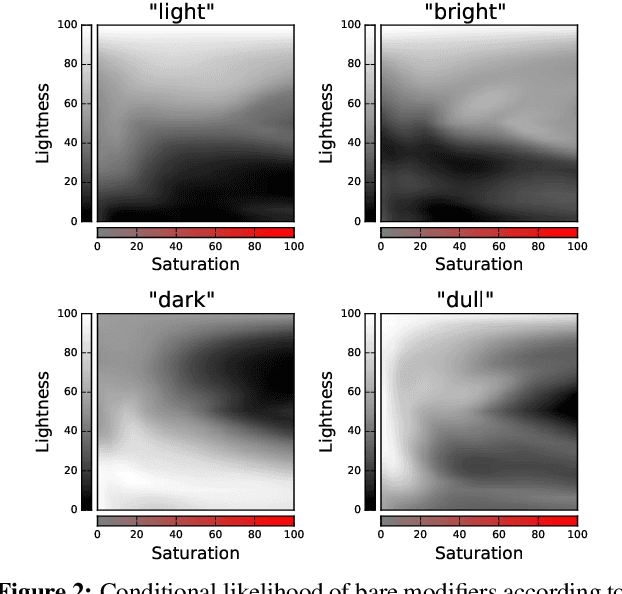
The production of color language is essential for grounded language generation. Color descriptions have many challenging properties: they can be vague, compositionally complex, and denotationally rich. We present an effective approach to generating color descriptions using recurrent neural networks and a Fourier-transformed color representation. Our model outperforms previous work on a conditional language modeling task over a large corpus of naturalistic color descriptions. In addition, probing the model's output reveals that it can accurately produce not only basic color terms but also descriptors with non-convex denotations ("greenish"), bare modifiers ("bright", "dull"), and compositional phrases ("faded teal") not seen in training.