 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapeGlot: Learning Language for Shape Differentiation
May 08, 2019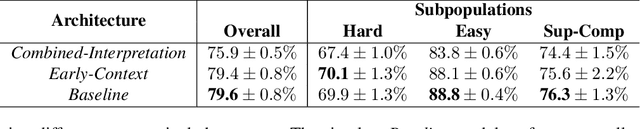
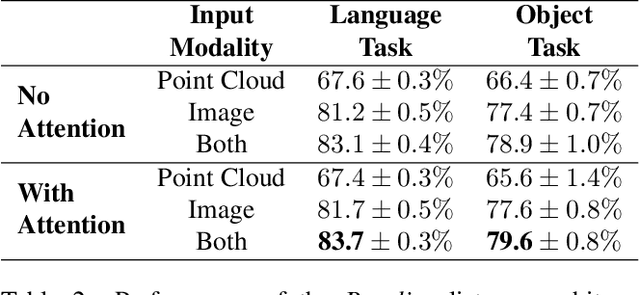
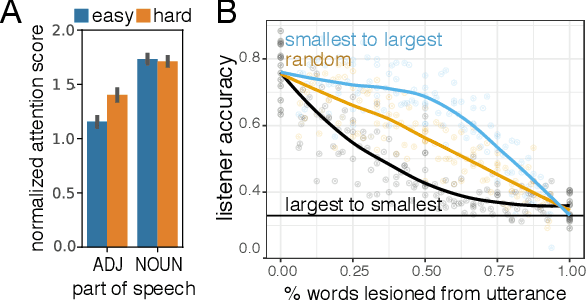
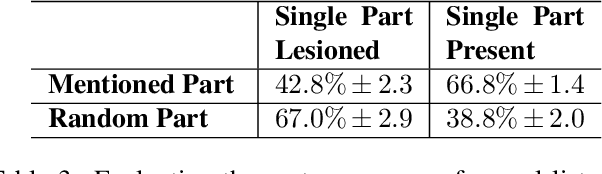
In this work we explore how fine-grained differences between the shapes of common objects are expressed in language, grounded on images and 3D models of the objects. We first build a large scale, carefully controlled dataset of human utterances that each refers to a 2D rendering of a 3D CAD model so as to distinguish it from a set of shape-wise similar alternatives. Using this dataset, we develop neural language understanding (listening) and production (speaking) models that vary in their grounding (pure 3D forms via point-clouds vs. rendered 2D images), the degree of pragmatic reasoning captured (e.g. speakers that reason about a listener or not), and the neural architecture (e.g. with or without attention). We find models that perform well with both synthetic and human partners, and with held out utterances and objects. We also find that these models are amenable to zero-shot transfer learning to novel object classes (e.g. transfer from training on chairs to testing on lamps), as well as to real-world images drawn from furniture catalogs. Lesion studies indicate that the neural listeners depend heavily on part-related words and associate these words correctly with visual parts of objects (without any explicit network training on object parts), and that transfer to novel classes is most successful when known part-words are available. This work illustrates a practical approach to language grounding, and provides a case study in the relationship between object shape and linguistic structure when it comes to object differentiation.
When redundancy is rational: A Bayesian approach to 'overinformative' referring expressions
Mar 19, 2019


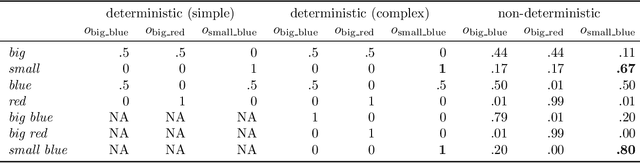
Referring is one of the most basic and prevalent uses of language. How do speakers choose from the wealth of referring expressions at their disposal? Rational theories of language use have come under attack for decades for not being able to account for the seemingly irrational overinformativeness ubiquitous in referring expressions. Here we present a novel production model of referring expressions within the Rational Speech Act framework that treats speakers as agents that rationally trade off cost and informativeness of utterances. Crucially, we relax the assumption of deterministic meaning in favor of a graded semantics. This innovation allows us to capture a large number of seemingly disparate phenomena within one unified framework: the basic asymmetry in speakers' propensity to overmodify with color rather than size; the increase in overmodification in complex scenes; the increase in overmodification with atypical features; and the preference for basic level nominal reference. These findings cast a new light on the production of referring expressions: rather than being wastefully overinformative, reference is rationally redundant.
Speakers account for asymmetries in visual perspective so listeners don't have to
Oct 22, 2018
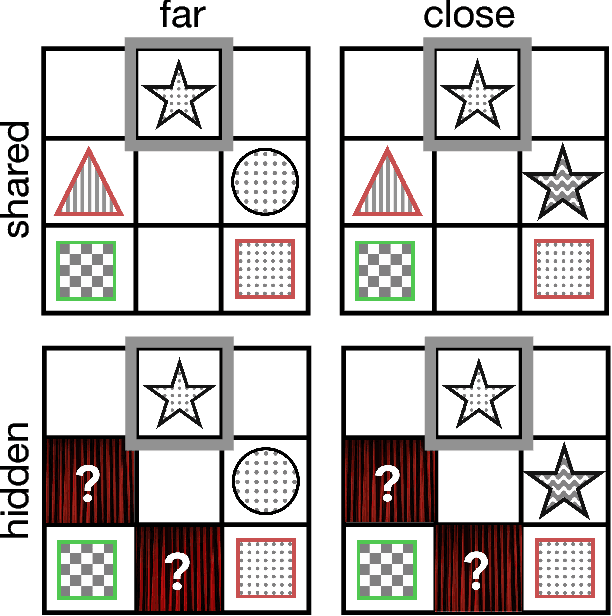
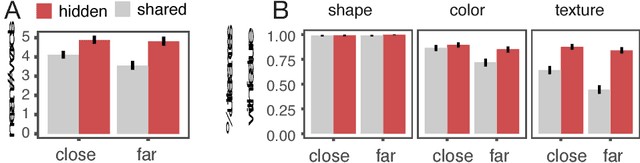
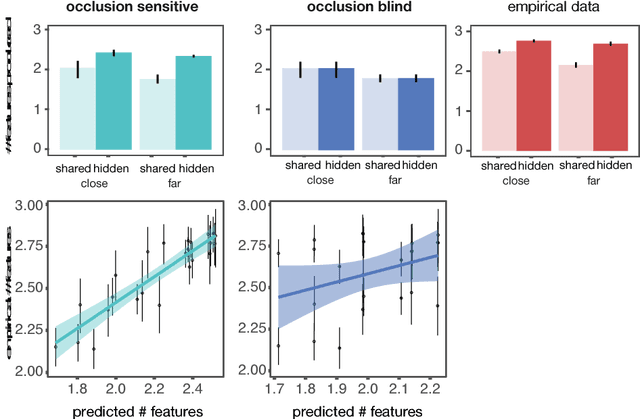
Debates over adults' theory of mind use have been fueled by surprising failures of visual perspective-taking in simple communicative tasks. Motivated by recent computational models of context-sensitive language use, we reconsider the evidence in light of the nuanced Gricean pragmatics of these tasks: the differential informativity expected of a speaker depending on the context. In particular, when speakers are faced with asymmetries in visual access---when it is clear that additional objects are in their partner's view but not their own---our model predicts that they ought to adjust their utterances to be more informative. In Exp. 1, we explicitly manipulated the presence or absence of occlusions and found that speakers systematically produced longer, more specific referring expressions than required given their own view. In Exp. 2, we compare the scripted utterances used by confederates in prior work with those produced by unscripted speakers in the same task. We find that confederates are systematically less informative than would be expected, leading to more listener errors. In addition to demonstrating a sophisticated form of speaker perspective-taking, these results suggest a resource-rational explanation for why listeners may sometimes neglect to consider visual perspective: it may be justified by adaptive Gricean expectations about the likely division of joint cognitive effort.
Colors in Context: A Pragmatic Neural Model for Grounded Language Understanding
May 16, 2017We present a model of pragmatic referring expression interpretation in a grounded communication task (identifying colors from descriptions) that draws upon predictions from two recurrent neural network classifiers, a speaker and a listener, unified by a recursive pragmatic reasoning framework. Experiments show that this combined pragmatic model interprets color descriptions more accurately than the classifiers from which it is built, and that much of this improvement results from combining the speaker and listener perspectives. We observe that pragmatic reasoning helps primarily in the hardest cases: when the model must distinguish very similar colors, or when few utterances adequately express the target color. Our findings make use of a newly-collected corpus of human utterances in color reference games, which exhibit a variety of pragmatic behaviors. We also show that the embedded speaker model reproduces many of these pragmatic behaviors.
Coarse-to-Fine Sequential Monte Carlo for Probabilistic Programs
Sep 09, 2015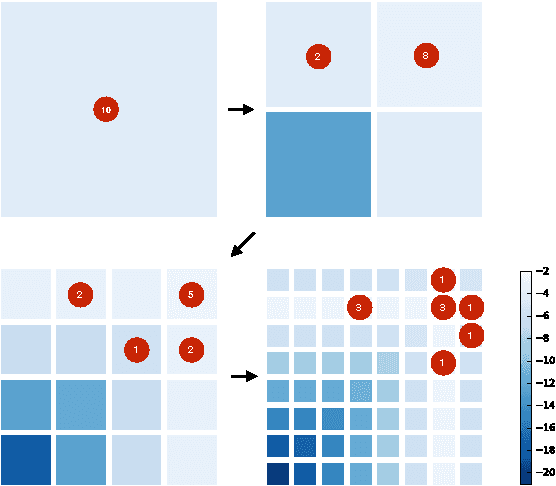


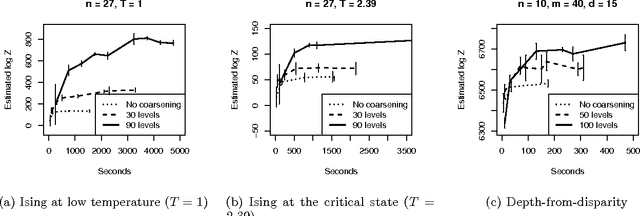
Many practical techniques for probabilistic inference require a sequence of distributions that interpolate between a tractable distribution and an intractable distribution of interest. Usually, the sequences used are simple, e.g., based on geometric averages between distributions. When models are expressed as probabilistic programs, the models themselves are highly structured objects that can be used to derive annealing sequences that are more sensitive to domain structure. We propose an algorithm for transforming probabilistic programs to coarse-to-fine programs which have the same marginal distribution as the original programs, but generate the data at increasing levels of detail, from coarse to fine. We apply this algorithm to an Ising model, its depth-from-disparity variation, and a factorial hidden Markov model. We show preliminary evidence that the use of coarse-to-fine models can make existing generic inference algorithms more efficient.