 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTABQAWORLD: Optimizing Multimodal Reasoning for Multi-Turn Table Question Answering
Apr 03, 2026Multimodal reasoning has emerged as a powerful framework for enhancing reasoning capabilities of reasoning models. While multi-turn table reasoning methods have improved reasoning accuracy through tool use and reward modeling, they rely on fixed text serialization for table state readouts. This introduces representation errors in table encoding that significantly accumulate over multiple turns. Such accumulation is alleviated by tabular grounding methods in the expense of inference compute and cost, rendering real world deployment impractical. To address this, we introduce TABQAWORLD, a table reasoning framework that jointly optimizes tabular action through representation and estimation. For representation, TABQAWORLD employs an action-conditioned multimodal selection policy, which dynamically switches between visual and textual representations to maximize table state readout reliability. For estimation, TABQAWORLD optimizes stepwise reasoning trajectory through table metadata including dimension, data types and key values, safely planning trajectory and compressing low-complexity actions to reduce conversation turns and latency. Designed as a training-free framework, empirical evaluations show that TABQAWORLD achieves state-of-the-art performance with 4.87% accuracy improvements over baselines, with 5.42% accuracy gain and 33.35% inference latency reduction over static settings, establishing a new standard for reliable and efficient table reasoning.
When More Words Say Less: Decoupling Length and Specificity in Image Description Evaluation
Jan 08, 2026Vision-language models (VLMs) are increasingly used to make visual content accessible via text-based descriptions. In current systems, however, description specificity is often conflated with their length. We argue that these two concepts must be disentangled: descriptions can be concise yet dense with information, or lengthy yet vacuous. We define specificity relative to a contrast set, where a description is more specific to the extent that it picks out the target image better than other possible images. We construct a dataset that controls for length while varying information content, and validate that people reliably prefer more specific descriptions regardless of length. We find that controlling for length alone cannot account for differences in specificity: how the length budget is allocated makes a difference. These results support evaluation approaches that directly prioritize specificity over verbosity.
Measuring Bias or Measuring the Task: Understanding the Brittle Nature of LLM Gender Biases
Sep 04, 2025As LLMs are increasingly applied in socially impactful settings, concerns about gender bias have prompted growing efforts both to measure and mitigate such bias. These efforts often rely on evaluation tasks that differ from natural language distributions, as they typically involve carefully constructed task prompts that overtly or covertly signal the presence of gender bias-related content. In this paper, we examine how signaling the evaluative purpose of a task impacts measured gender bias in LLMs. Concretely, we test models under prompt conditions that (1) make the testing context salient, and (2) make gender-focused content salient. We then assess prompt sensitivity across four task formats with both token-probability and discrete-choice metrics. We find that even minor prompt changes can substantially alter bias outcomes, sometimes reversing their direction entirely. Discrete-choice metrics further tend to amplify bias relative to probabilistic measures. These findings do not only highlight the brittleness of LLM gender bias evaluations but open a new puzzle for the NLP benchmarking and development community: To what extent can well-controlled testing designs trigger LLM ``testing mode'' performance, and what does this mean for the ecological validity of future benchmarks.
CHART-6: Human-Centered Evaluation of Data Visualization Understanding in Vision-Language Models
May 22, 2025



Data visualizations are powerful tools for communicating patterns in quantitative data. Yet understanding any data visualization is no small feat -- succeeding requires jointly making sense of visual, numerical, and linguistic inputs arranged in a conventionalized format one has previously learned to parse. Recently developed vision-language models are, in principle, promising candidates for developing computational models of these cognitive operations. However, it is currently unclear to what degree these models emulate human behavior on tasks that involve reasoning about data visualizations. This gap reflects limitations in prior work that has evaluated data visualization understanding in artificial systems using measures that differ from those typically used to assess these abilities in humans. Here we evaluated eight vision-language models on six data visualization literacy assessments designed for humans and compared model responses to those of human participants. We found that these models performed worse than human participants on average, and this performance gap persisted even when using relatively lenient criteria to assess model performance. Moreover, while relative performance across items was somewhat correlated between models and humans, all models produced patterns of errors that were reliably distinct from those produced by human participants. Taken together, these findings suggest significant opportunities for further development of artificial systems that might serve as useful models of how humans reason about data visualizations. All code and data needed to reproduce these results are available at: https://osf.io/e25mu/?view_only=399daff5a14d4b16b09473cf19043f18.
MOSAIC: Modeling Social AI for Content Dissemination and Regulation in Multi-Agent Simulations
Apr 10, 2025



We present a novel, open-source social network simulation framework, MOSAIC, where generative language agents predict user behaviors such as liking, sharing, and flagging content. This simulation combines LLM agents with a directed social graph to analyze emergent deception behaviors and gain a better understanding of how users determine the veracity of online social content. By constructing user representations from diverse fine-grained personas, our system enables multi-agent simulations that model content dissemination and engagement dynamics at scale. Within this framework, we evaluate three different content moderation strategies with simulated misinformation dissemination, and we find that they not only mitigate the spread of non-factual content but also increase user engagement. In addition, we analyze the trajectories of popular content in our simulations, and explore whether simulation agents' articulated reasoning for their social interactions truly aligns with their collective engagement patterns. We open-source our simulation software to encourage further research within AI and social sciences.
Updating CLIP to Prefer Descriptions Over Captions
Jun 12, 2024Although CLIPScore is a powerful generic metric that captures the similarity between a text and an image, it fails to distinguish between a caption that is meant to complement the information in an image and a description that is meant to replace an image entirely, e.g., for accessibility. We address this shortcoming by updating the CLIP model with the Concadia dataset to assign higher scores to descriptions than captions using parameter efficient fine-tuning and a loss objective derived from work on causal interpretability. This model correlates with the judgements of blind and low-vision people while preserving transfer capabilities and has interpretable structure that sheds light on the caption--description distinction.
CommVQA: Situating Visual Question Answering in Communicative Contexts
Feb 22, 2024Current visual question answering (VQA) models tend to be trained and evaluated on image-question pairs in isolation. However, the questions people ask are dependent on their informational needs and prior knowledge about the image content. To evaluate how situating images within naturalistic contexts shapes visual questions, we introduce CommVQA, a VQA dataset consisting of images, image descriptions, real-world communicative scenarios where the image might appear (e.g., a travel website), and follow-up questions and answers conditioned on the scenario. We show that CommVQA poses a challenge for current models. Providing contextual information to VQA models improves performance broadly, highlighting the relevance of situating systems within a communicative scenario.
ContextRef: Evaluating Referenceless Metrics For Image Description Generation
Sep 21, 2023



Referenceless metrics (e.g., CLIPScore) use pretrained vision--language models to assess image descriptions directly without costly ground-truth reference texts. Such methods can facilitate rapid progress, but only if they truly align with human preference judgments. In this paper, we introduce ContextRef, a benchmark for assessing referenceless metrics for such alignment. ContextRef has two components: human ratings along a variety of established quality dimensions, and ten diverse robustness checks designed to uncover fundamental weaknesses. A crucial aspect of ContextRef is that images and descriptions are presented in context, reflecting prior work showing that context is important for description quality. Using ContextRef, we assess a variety of pretrained models, scoring functions, and techniques for incorporating context. None of the methods is successful with ContextRef, but we show that careful fine-tuning yields substantial improvements. ContextRef remains a challenging benchmark though, in large part due to the challenge of context dependence.
Context-VQA: Towards Context-Aware and Purposeful Visual Question Answering
Jul 28, 2023

Visual question answering (VQA) has the potential to make the Internet more accessible in an interactive way, allowing people who cannot see images to ask questions about them. However, multiple studies have shown that people who are blind or have low-vision prefer image explanations that incorporate the context in which an image appears, yet current VQA datasets focus on images in isolation. We argue that VQA models will not fully succeed at meeting people's needs unless they take context into account. To further motivate and analyze the distinction between different contexts, we introduce Context-VQA, a VQA dataset that pairs images with contexts, specifically types of websites (e.g., a shopping website). We find that the types of questions vary systematically across contexts. For example, images presented in a travel context garner 2 times more "Where?" questions, and images on social media and news garner 2.8 and 1.8 times more "Who?" questions than the average. We also find that context effects are especially important when participants can't see the image. These results demonstrate that context affects the types of questions asked and that VQA models should be context-sensitive to better meet people's needs, especially in accessibility settings.
Context Matters for Image Descriptions for Accessibility: Challenges for Referenceless Evaluation Metrics
May 21, 2022
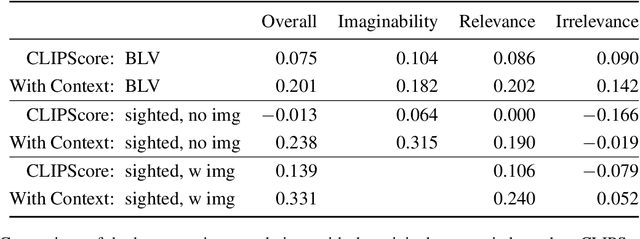
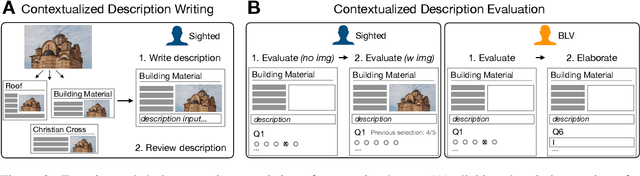
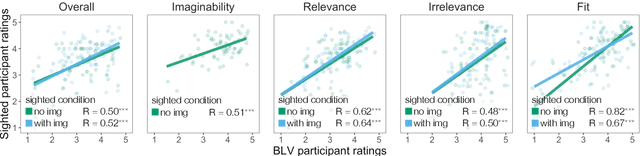
Few images on the Web receive alt-text descriptions that would make them accessible to blind and low vision (BLV) users. Image-based NLG systems have progressed to the point where they can begin to address this persistent societal problem, but these systems will not be fully successful unless we evaluate them on metrics that guide their development correctly. Here, we argue against current referenceless metrics -- those that don't rely on human-generated ground-truth descriptions -- on the grounds that they do not align with the needs of BLV users. The fundamental shortcoming of these metrics is that they cannot take context into account, whereas contextual information is highly valued by BLV users. To substantiate these claims, we present a study with BLV participants who rated descriptions along a variety of dimensions. An in-depth analysis reveals that the lack of context-awareness makes current referenceless metrics inadequate for advancing image accessibility, requiring a rethinking of referenceless evaluation metrics for image-based NLG systems.