 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Distillation for Language Models
Dec 05, 2021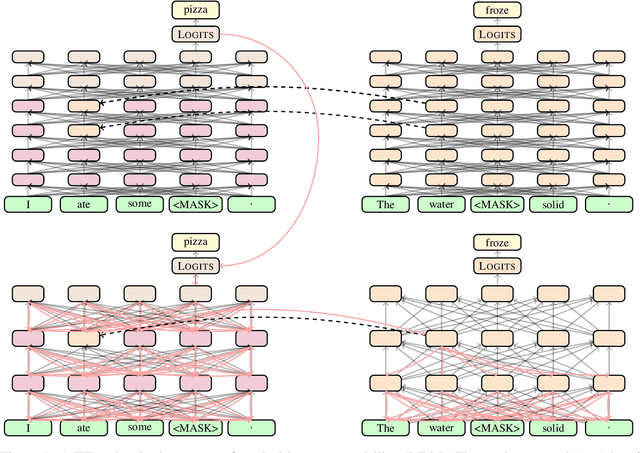

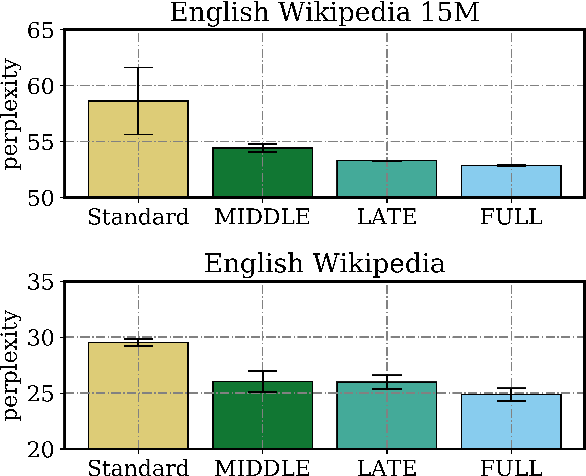
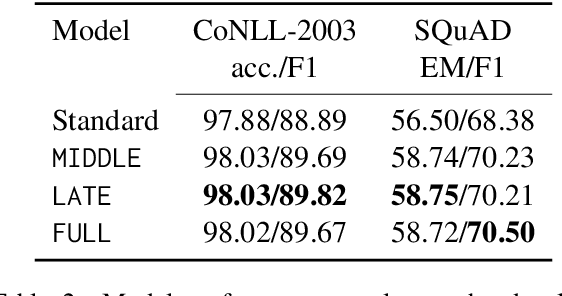
Distillation efforts have led to language models that are more compact and efficient without serious drops in performance. The standard approach to distillation trains a student model against two objectives: a task-specific objective (e.g., language modeling) and an imitation objective that encourages the hidden states of the student model to be similar to those of the larger teacher model. In this paper, we show that it is beneficial to augment distillation with a third objective that encourages the student to imitate the causal computation process of the teacher through interchange intervention training(IIT). IIT pushes the student model to become a causal abstraction of the teacher model - a simpler model with the same causal structure. IIT is fully differentiable, easily implemented, and combines flexibly with other objectives. Compared with standard distillation of BERT, distillation via IIT results in lower perplexity on Wikipedia (masked language modeling) and marked improvements on the GLUE benchmark (natural language understanding), SQuAD (question answering), and CoNLL-2003 (named entity recognition).
Inducing Causal Structure for Interpretable Neural Networks
Dec 01, 2021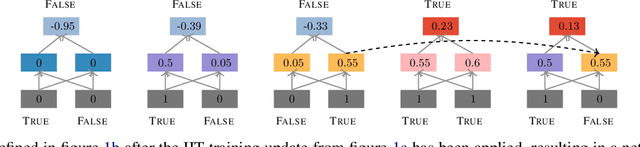
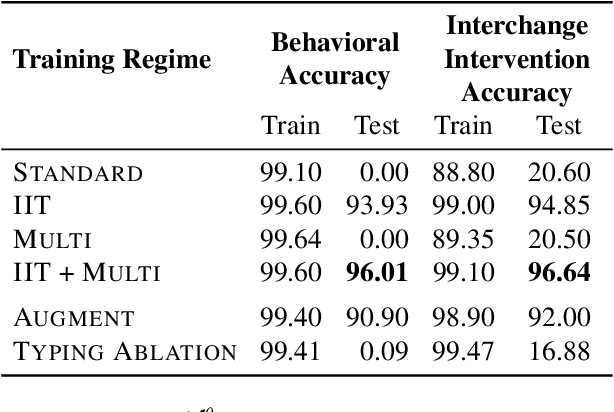
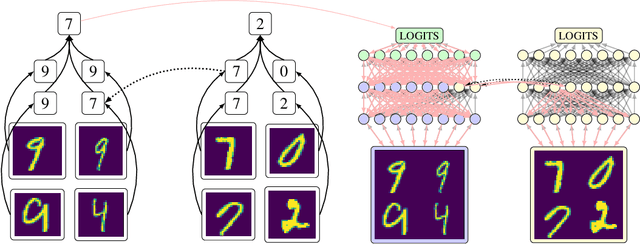
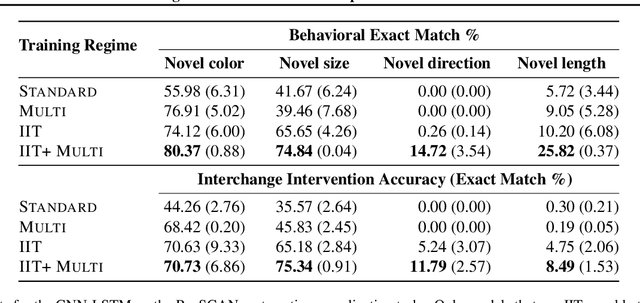
In many areas, we have well-founded insights about causal structure that would be useful to bring into our trained models while still allowing them to learn in a data-driven fashion. To achieve this, we present the new method of interchange intervention training(IIT). In IIT, we (1)align variables in the causal model with representations in the neural model and (2) train a neural model to match the counterfactual behavior of the causal model on a base input when aligned representations in both models are set to be the value they would be for a second source input. IIT is fully differentiable, flexibly combines with other objectives, and guarantees that the target causal model is acausal abstraction of the neural model when its loss is minimized. We evaluate IIT on a structured vision task (MNIST-PVR) and a navigational instruction task (ReaSCAN). We compare IIT against multi-task training objectives and data augmentation. In all our experiments, IIT achieves the best results and produces neural models that are more interpretable in the sense that they realize the target causal model.
Causal Abstractions of Neural Networks
Jun 06, 2021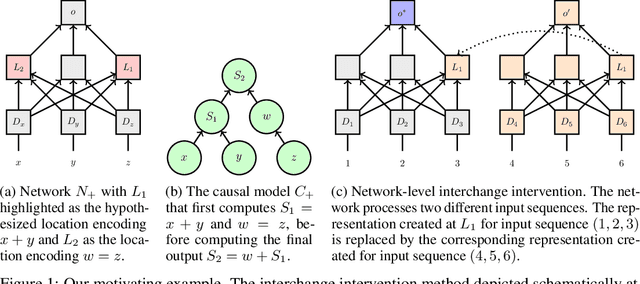

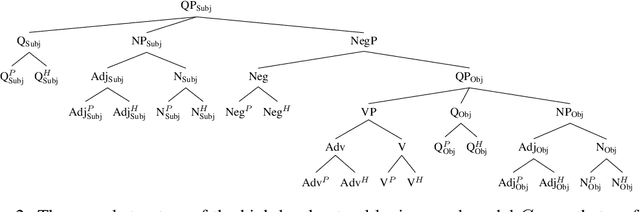

Structural analysis methods (e.g., probing and feature attribution) are increasingly important tools for neural network analysis. We propose a new structural analysis method grounded in a formal theory of \textit{causal abstraction} that provides rich characterizations of model-internal representations and their roles in input/output behavior. In this method, neural representations are aligned with variables in interpretable causal models, and then \textit{interchange interventions} are used to experimentally verify that the neural representations have the causal properties of their aligned variables. We apply this method in a case study to analyze neural models trained on Multiply Quantified Natural Language Inference (MQNLI) corpus, a highly complex NLI dataset that was constructed with a tree-structured natural logic causal model. We discover that a BERT-based model with state-of-the-art performance successfully realizes the approximate causal structure of the natural logic causal model, whereas a simpler baseline model fails to show any such structure, demonstrating that neural representations encode the compositional structure of MQNLI examples.