 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranscoder Adapters for Reasoning-Model Diffing
Feb 24, 2026While reasoning models are increasingly ubiquitous, the effects of reasoning training on a model's internal mechanisms remain poorly understood. In this work, we introduce transcoder adapters, a technique for learning an interpretable approximation of the difference in MLP computation before and after fine-tuning. We apply transcoder adapters to characterize the differences between Qwen2.5-Math-7B and its reasoning-distilled variant, DeepSeek-R1-Distill-Qwen-7B. Learned adapters are faithful to the target model's internal computation and next-token predictions. When evaluated on reasoning benchmarks, adapters match the reasoning model's response lengths and typically recover 50-90% of the accuracy gains from reasoning fine-tuning. Adapter features are sparsely activating and interpretable. When examining adapter features, we find that only ~8% have activating examples directly related to reasoning behaviors. We deeply study one such behavior -- the production of hesitation tokens (e.g., "wait"). Using attribution graphs, we trace hesitation to only ~2.4% of adapter features (5.6k total) performing one of two functions. These features are necessary and sufficient for producing hesitation tokens; removing them reduces response length, often without affecting accuracy. Overall, our results provide insight into reasoning training and suggest transcoder adapters may be useful for studying fine-tuning more broadly.
Internal Causal Mechanisms Robustly Predict Language Model Out-of-Distribution Behaviors
May 17, 2025



Interpretability research now offers a variety of techniques for identifying abstract internal mechanisms in neural networks. Can such techniques be used to predict how models will behave on out-of-distribution examples? In this work, we provide a positive answer to this question. Through a diverse set of language modeling tasks--including symbol manipulation, knowledge retrieval, and instruction following--we show that the most robust features for correctness prediction are those that play a distinctive causal role in the model's behavior. Specifically, we propose two methods that leverage causal mechanisms to predict the correctness of model outputs: counterfactual simulation (checking whether key causal variables are realized) and value probing (using the values of those variables to make predictions). Both achieve high AUC-ROC in distribution and outperform methods that rely on causal-agnostic features in out-of-distribution settings, where predicting model behaviors is more crucial. Our work thus highlights a novel and significant application for internal causal analysis of language models.
Modeling Discrimination with Causal Abstraction
Jan 14, 2025A person is directly racially discriminated against only if her race caused her worse treatment. This implies that race is an attribute sufficiently separable from other attributes to isolate its causal role. But race is embedded in a nexus of social factors that resist isolated treatment. If race is socially constructed, in what sense can it cause worse treatment? Some propose that the perception of race, rather than race itself, causes worse treatment. Others suggest that since causal models require modularity, i.e. the ability to isolate causal effects, attempts to causally model discrimination are misguided. This paper addresses the problem differently. We introduce a framework for reasoning about discrimination, in which race is a high-level abstraction of lower-level features. In this framework, race can be modeled as itself causing worse treatment. Modularity is ensured by allowing assumptions about social construction to be precisely and explicitly stated, via an alignment between race and its constituents. Such assumptions can then be subjected to normative and empirical challenges, which lead to different views of when discrimination occurs. By distinguishing constitutive and causal relations, the abstraction framework pinpoints disagreements in the current literature on modeling discrimination, while preserving a precise causal account of discrimination.
Belief in the Machine: Investigating Epistemological Blind Spots of Language Models
Oct 28, 2024As language models (LMs) become integral to fields like healthcare, law, and journalism, their ability to differentiate between fact, belief, and knowledge is essential for reliable decision-making. Failure to grasp these distinctions can lead to significant consequences in areas such as medical diagnosis, legal judgments, and dissemination of fake news. Despite this, current literature has largely focused on more complex issues such as theory of mind, overlooking more fundamental epistemic challenges. This study systematically evaluates the epistemic reasoning capabilities of modern LMs, including GPT-4, Claude-3, and Llama-3, using a new dataset, KaBLE, consisting of 13,000 questions across 13 tasks. Our results reveal key limitations. First, while LMs achieve 86% accuracy on factual scenarios, their performance drops significantly with false scenarios, particularly in belief-related tasks. Second, LMs struggle with recognizing and affirming personal beliefs, especially when those beliefs contradict factual data, which raises concerns for applications in healthcare and counseling, where engaging with a person's beliefs is critical. Third, we identify a salient bias in how LMs process first-person versus third-person beliefs, performing better on third-person tasks (80.7%) compared to first-person tasks (54.4%). Fourth, LMs lack a robust understanding of the factive nature of knowledge, namely, that knowledge inherently requires truth. Fifth, LMs rely on linguistic cues for fact-checking and sometimes bypass the deeper reasoning. These findings highlight significant concerns about current LMs' ability to reason about truth, belief, and knowledge while emphasizing the need for advancements in these areas before broad deployment in critical sectors.
A Reply to Makelov et al. 's "Interpretability Illusion" Arguments
Jan 23, 2024We respond to the recent paper by Makelov et al. (2023), which reviews subspace interchange intervention methods like distributed alignment search (DAS; Geiger et al. 2023) and claims that these methods potentially cause "interpretability illusions". We first review Makelov et al. (2023)'s technical notion of what an "interpretability illusion" is, and then we show that even intuitive and desirable explanations can qualify as illusions in this sense. As a result, their method of discovering "illusions" can reject explanations they consider "non-illusory". We then argue that the illusions Makelov et al. (2023) see in practice are artifacts of their training and evaluation paradigms. We close by emphasizing that, though we disagree with their core characterization, Makelov et al. (2023)'s examples and discussion have undoubtedly pushed the field of interpretability forward.
Comparing Causal Frameworks: Potential Outcomes, Structural Models, Graphs, and Abstractions
Jun 25, 2023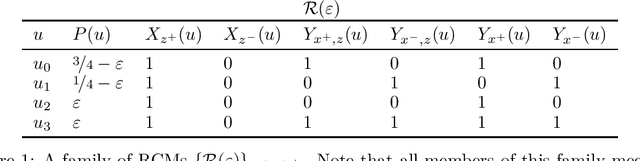
The aim of this paper is to make clear and precise the relationship between the Rubin causal model (RCM) and structural causal model (SCM) frameworks for causal inference. Adopting a neutral logical perspective, and drawing on previous work, we show what is required for an RCM to be representable by an SCM. A key result then shows that every RCM -- including those that violate algebraic principles implied by the SCM framework -- emerges as an abstraction of some representable RCM. Finally, we illustrate the power of this ameliorative perspective by pinpointing an important role for SCM principles in classic applications of RCMs; conversely, we offer a characterization of the algebraic constraints implied by a graph, helping to substantiate further comparisons between the two frameworks.
Finding Alignments Between Interpretable Causal Variables and Distributed Neural Representations
Mar 05, 2023Causal abstraction is a promising theoretical framework for explainable artificial intelligence that defines when an interpretable high-level causal model is a faithful simplification of a low-level deep learning system. However, existing causal abstraction methods have two major limitations: they require a brute-force search over alignments between the high-level model and the low-level one, and they presuppose that variables in the high-level model will align with disjoint sets of neurons in the low-level one. In this paper, we present distributed alignment search (DAS), which overcomes these limitations. In DAS, we find the alignment between high-level and low-level models using gradient descent rather than conducting a brute-force search, and we allow individual neurons to play multiple distinct roles by analyzing representations in non-standard bases-distributed representations. Our experiments show that DAS can discover internal structure that prior approaches miss. Overall, DAS removes previous obstacles to conducting causal abstraction analyses and allows us to find conceptual structure in trained neural nets.
Causal Abstraction for Faithful Model Interpretation
Jan 11, 2023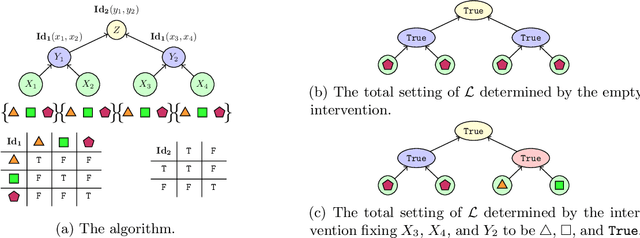
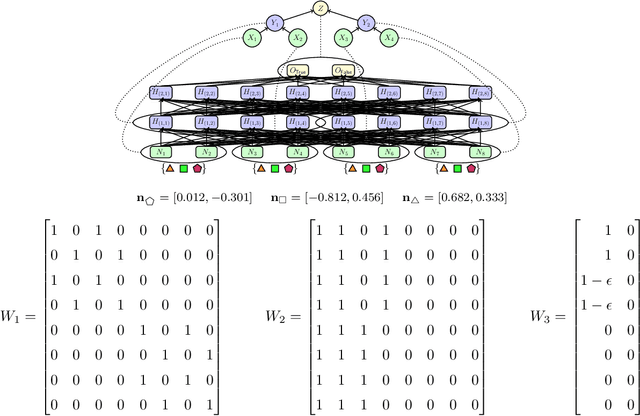
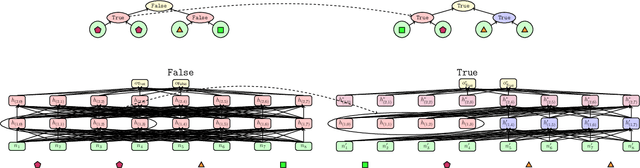
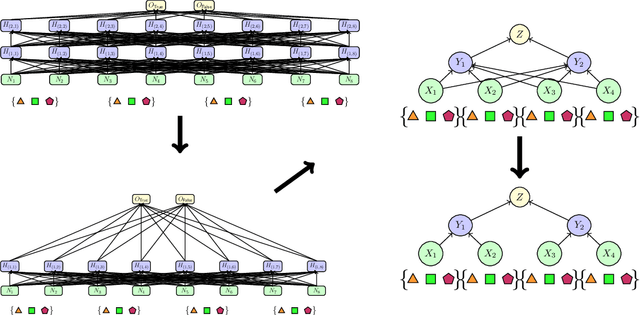
A faithful and interpretable explanation of an AI model's behavior and internal structure is a high-level explanation that is human-intelligible but also consistent with the known, but often opaque low-level causal details of the model. We argue that the theory of causal abstraction provides the mathematical foundations for the desired kinds of model explanations. In causal abstraction analysis, we use interventions on model-internal states to rigorously assess whether an interpretable high-level causal model is a faithful description of an AI model. Our contributions in this area are: (1) We generalize causal abstraction to cyclic causal structures and typed high-level variables. (2) We show how multi-source interchange interventions can be used to conduct causal abstraction analyses. (3) We define a notion of approximate causal abstraction that allows us to assess the degree to which a high-level causal model is a causal abstraction of a lower-level one. (4) We prove constructive causal abstraction can be decomposed into three operations we refer to as marginalization, variable-merge, and value-merge. (5) We formalize the XAI methods of LIME, causal effect estimation, causal mediation analysis, iterated nullspace projection, and circuit-based explanations as special cases of causal abstraction analysis.
Causal Abstraction with Soft Interventions
Nov 22, 2022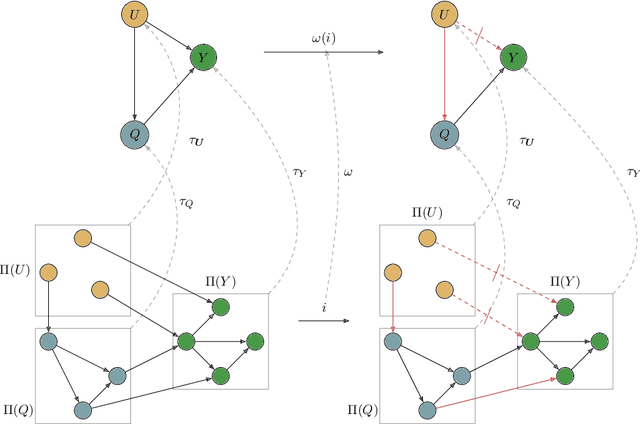
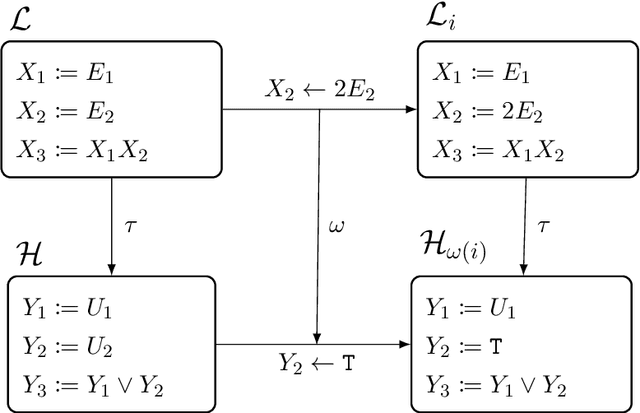
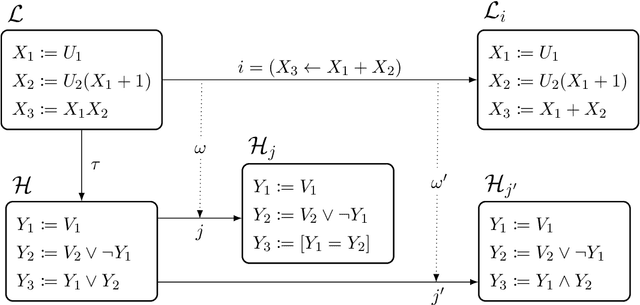
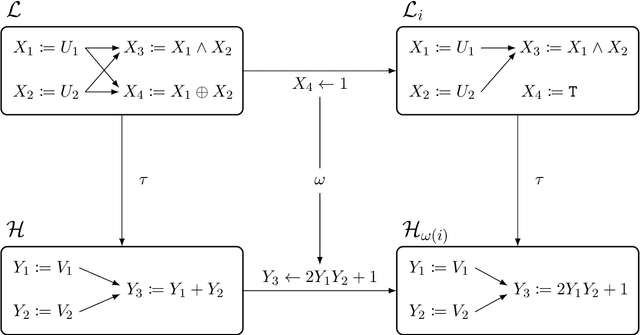
Causal abstraction provides a theory describing how several causal models can represent the same system at different levels of detail. Existing theoretical proposals limit the analysis of abstract models to "hard" interventions fixing causal variables to be constant values. In this work, we extend causal abstraction to "soft" interventions, which assign possibly non-constant functions to variables without adding new causal connections. Specifically, (i) we generalize $\tau$-abstraction from Beckers and Halpern (2019) to soft interventions, (ii) we propose a further definition of soft abstraction to ensure a unique map $\omega$ between soft interventions, and (iii) we prove that our constructive definition of soft abstraction guarantees the intervention map $\omega$ has a specific and necessary explicit form.
Holistic Evaluation of Language Models
Nov 16, 2022



Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.