 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Abstraction for Faithful Model Interpretation
Jan 11, 2023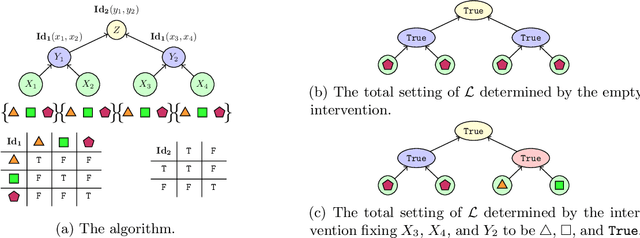
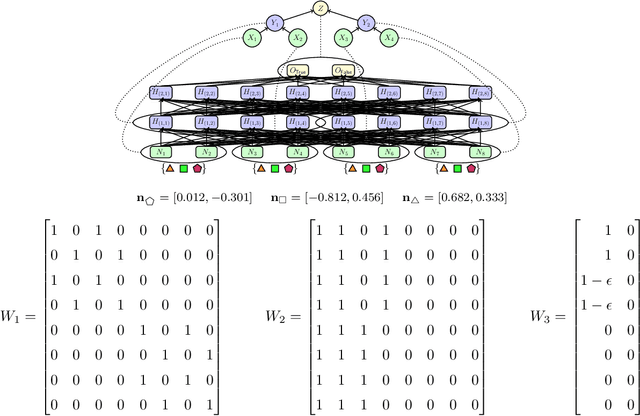
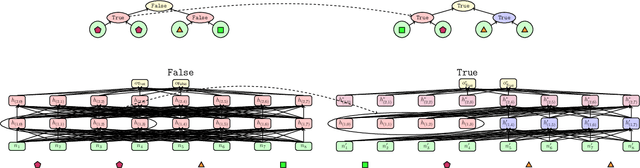
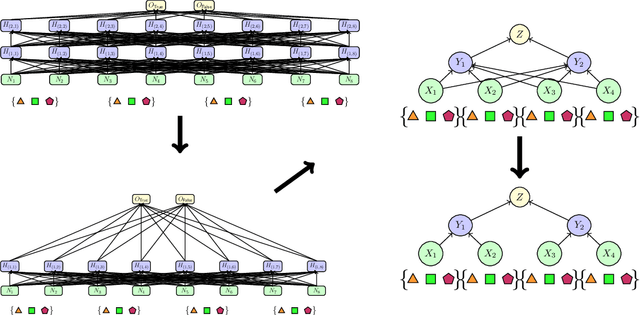
A faithful and interpretable explanation of an AI model's behavior and internal structure is a high-level explanation that is human-intelligible but also consistent with the known, but often opaque low-level causal details of the model. We argue that the theory of causal abstraction provides the mathematical foundations for the desired kinds of model explanations. In causal abstraction analysis, we use interventions on model-internal states to rigorously assess whether an interpretable high-level causal model is a faithful description of an AI model. Our contributions in this area are: (1) We generalize causal abstraction to cyclic causal structures and typed high-level variables. (2) We show how multi-source interchange interventions can be used to conduct causal abstraction analyses. (3) We define a notion of approximate causal abstraction that allows us to assess the degree to which a high-level causal model is a causal abstraction of a lower-level one. (4) We prove constructive causal abstraction can be decomposed into three operations we refer to as marginalization, variable-merge, and value-merge. (5) We formalize the XAI methods of LIME, causal effect estimation, causal mediation analysis, iterated nullspace projection, and circuit-based explanations as special cases of causal abstraction analysis.
Posing Fair Generalization Tasks for Natural Language Inference
Nov 03, 2019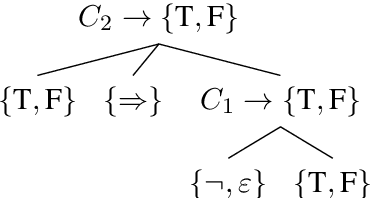
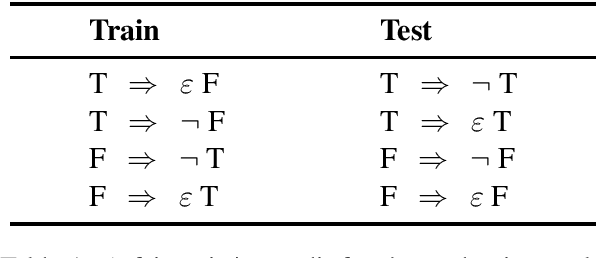

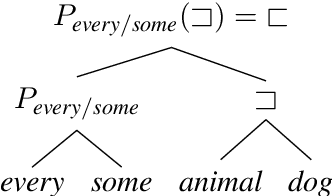
Deep learning models for semantics are generally evaluated using naturalistic corpora. Adversarial methods, in which models are evaluated on new examples with known semantic properties, have begun to reveal that good performance at these naturalistic tasks can hide serious shortcomings. However, we should insist that these evaluations be fair -that the models are given data sufficient to support the requisite kinds of generalization. In this paper, we define and motivate a formal notion of fairness in this sense. We then apply these ideas to natural language inference by constructing very challenging but provably fair artificial datasets and showing that standard neural models fail to generalize in the required ways; only task-specific models that jointly compose the premise and hypothesis are able to achieve high performance, and even these models do not solve the task perfectly.