 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosing Fair Generalization Tasks for Natural Language Inference
Nov 03, 2019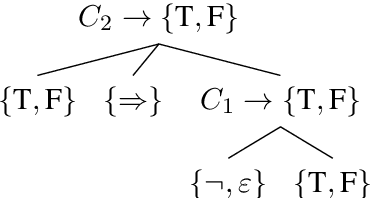
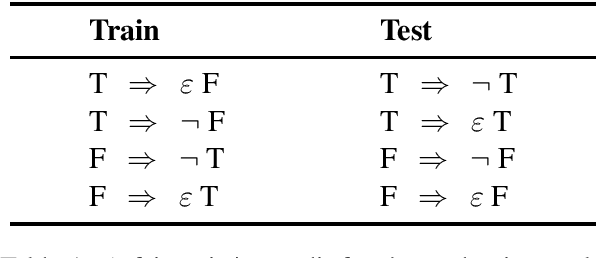

Deep learning models for semantics are generally evaluated using naturalistic corpora. Adversarial methods, in which models are evaluated on new examples with known semantic properties, have begun to reveal that good performance at these naturalistic tasks can hide serious shortcomings. However, we should insist that these evaluations be fair -that the models are given data sufficient to support the requisite kinds of generalization. In this paper, we define and motivate a formal notion of fairness in this sense. We then apply these ideas to natural language inference by constructing very challenging but provably fair artificial datasets and showing that standard neural models fail to generalize in the required ways; only task-specific models that jointly compose the premise and hypothesis are able to achieve high performance, and even these models do not solve the task perfectly.
Stress-Testing Neural Models of Natural Language Inference with Multiply-Quantified Sentences
Oct 30, 2018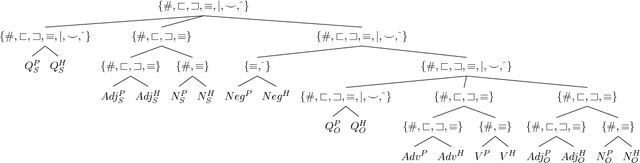


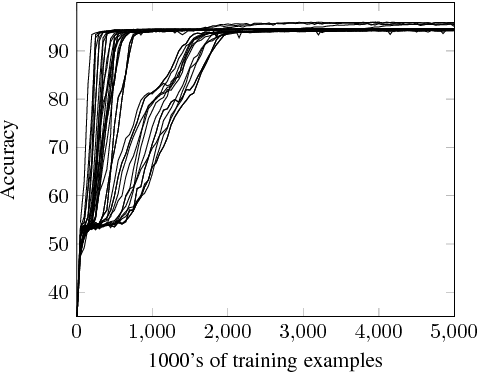
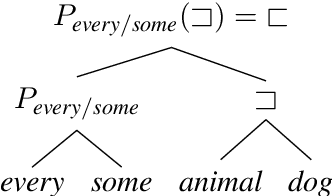
Standard evaluations of deep learning models for semantics using naturalistic corpora are limited in what they can tell us about the fidelity of the learned representations, because the corpora rarely come with good measures of semantic complexity. To overcome this limitation, we present a method for generating data sets of multiply-quantified natural language inference (NLI) examples in which semantic complexity can be precisely characterized, and we use this method to show that a variety of common architectures for NLI inevitably fail to encode crucial information; only a model with forced lexical alignments avoids this damaging information loss.
Finite-State Phonology: Proceedings of the 5th Workshop of the ACL Special Interest Group in Computational Phonology
Feb 23, 2001Home page of the workshop proceedings, with pointers to the individually archived papers. Includes front matter from the printed version of the proceedings.
* HTML page, Conference programme, short abstracts, links to papers, preface
Finite-State Non-Concatenative Morphotactics
Jun 30, 2000
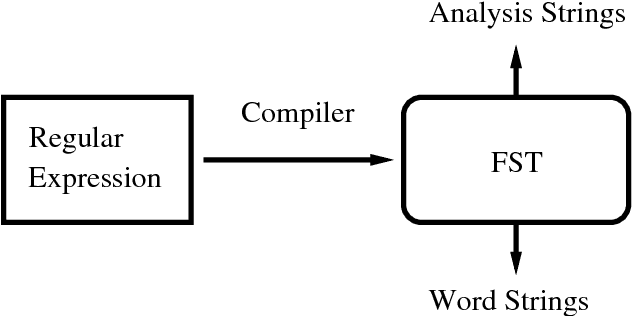
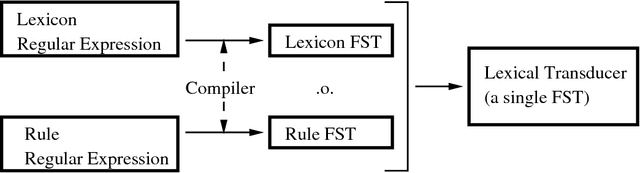
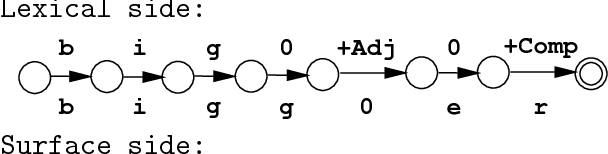
Finite-state morphology in the general tradition of the Two-Level and Xerox implementations has proved very successful in the production of robust morphological analyzer-generators, including many large-scale commercial systems. However, it has long been recognized that these implementations have serious limitations in handling non-concatenative phenomena. We describe a new technique for constructing finite-state transducers that involves reapplying the regular-expression compiler to its own output. Implemented in an algorithm called compile-replace, this technique has proved useful for handling non-concatenative phenomena; and we demonstrate it on Malay full-stem reduplication and Arabic stem interdigitation.
The Proper Treatment of Optimality in Computational Phonology
May 12, 1998
This paper presents a novel formalization of optimality theory. Unlike previous treatments of optimality in computational linguistics, starting with Ellison (1994), the new approach does not require any explicit marking and counting of constraint violations. It is based on the notion of "lenient composition," defined as the combination of ordinary composition and priority union. If an underlying form has outputs that can meet a given constraint, lenient composition enforces the constraint; if none of the output candidates meet the constraint, lenient composition allows all of them. For the sake of greater efficiency, we may "leniently compose" the GEN relation and all the constraints into a single finite-state transducer that maps each underlying form directly into its optimal surface realizations, and vice versa, without ever producing any failing candidates. Seen from this perspective, optimality theory is surprisingly similar to the two older strains of finite-state phonology: classical rewrite systems and two-level models. In particular, the ranking of optimality constraints corresponds to the ordering of rewrite rules.
* 12 pages. Postscript
Parallel Replacement in Finite State Calculus
Aug 12, 1996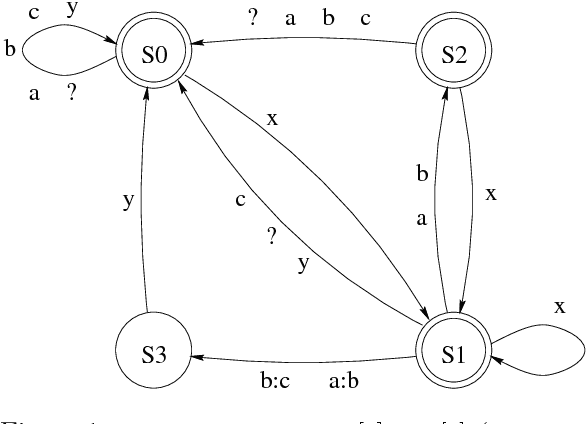
This paper extends the calculus of regular expressions with new types of replacement expressions that enhance the expressiveness of the simple replace operator defined in Karttunen (1995). Parallel replacement allows multiple replacements to apply simultaneously to the same input without interfering with each other. We also allow a replacement to be constrained by any number of alternative contexts. With these enhancements, the general replacement expressions are more versatile than two-level rules for the description of complex morphological alternations.
* 6 pages, dvi (+ 1x eps) tar gzip uuencode
Directed Replacement
Jun 23, 1996
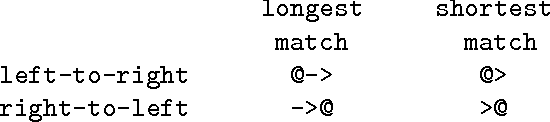
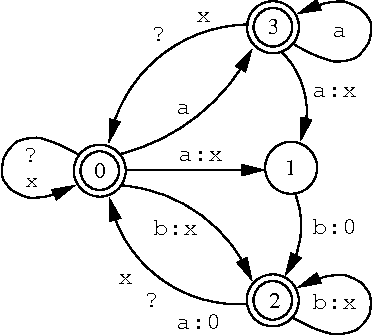
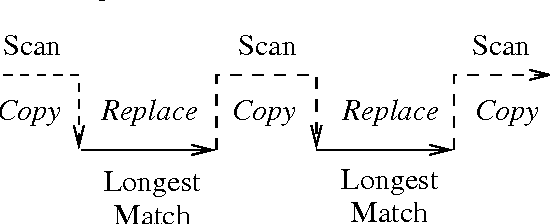
This paper introduces to the finite-state calculus a family of directed replace operators. In contrast to the simple replace expression, UPPER -> LOWER, defined in Karttunen (ACL-95), the new directed version, UPPER @-> LOWER, yields an unambiguous transducer if the lower language consists of a single string. It transduces the input string from left to right, making only the longest possible replacement at each point. A new type of replacement expression, UPPER @-> PREFIX ... SUFFIX, yields a transducer that inserts text around strings that are instances of UPPER. The symbol ... denotes the matching part of the input which itself remains unchanged. PREFIX and SUFFIX are regular expressions describing the insertions. Expressions of the type UPPER @-> PREFIX ... SUFFIX may be used to compose a deterministic parser for a ``local grammar'' in the sense of Gross (1989). Other useful applications of directed replacement include tokenization and filtering of text streams.
The Replace Operator
May 08, 1995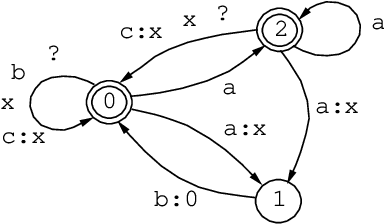
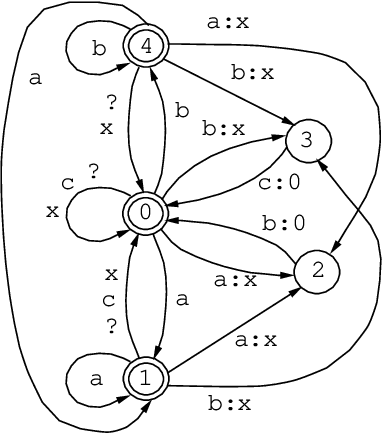
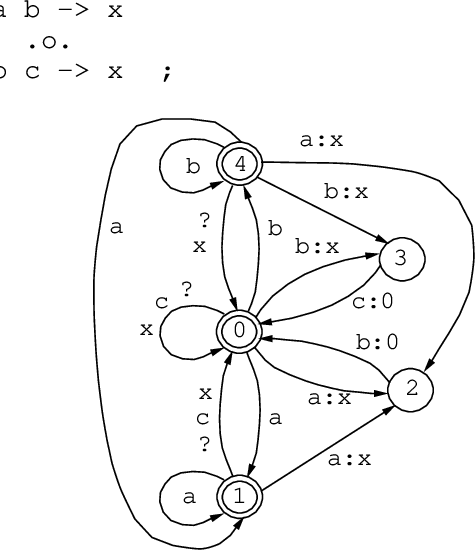
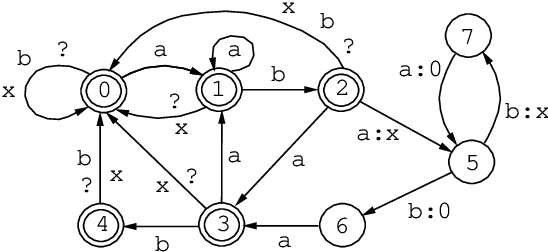
This paper introduces to the calculus of regular expressions a replace operator, ->, and defines a set of replacement expressions that concisely encode several alternate variations of the operation. The basic case is unconditional obligatory replacement: UPPER -> LOWER Conditional versions of replacement, such as, UPPER -> LOWER || LEFT _ RIGHT constrain the operation by left and right contexts. UPPER, LOWER, LEFT, and RIGHT may be regular expressions of any complexity. Replace expressions denote regular relations. The replace operator is defined in terms of other regular expression operators using techniques introduced by Ronald M. Kaplan and Martin Kay in "Regular Models of Phonological Rule Systems" (Computational Linguistics 20:3 331-378. 1994).