Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStress-Testing Neural Models of Natural Language Inference with Multiply-Quantified Sentences
Paper and Code
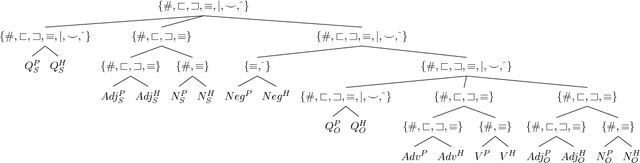


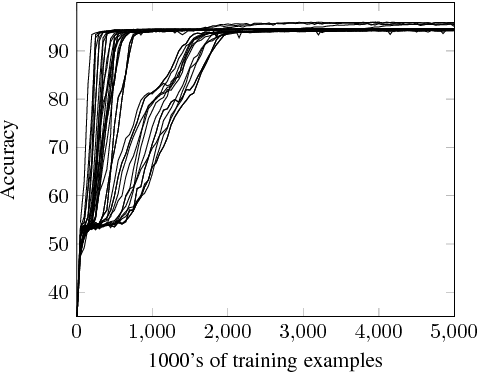
Standard evaluations of deep learning models for semantics using naturalistic corpora are limited in what they can tell us about the fidelity of the learned representations, because the corpora rarely come with good measures of semantic complexity. To overcome this limitation, we present a method for generating data sets of multiply-quantified natural language inference (NLI) examples in which semantic complexity can be precisely characterized, and we use this method to show that a variety of common architectures for NLI inevitably fail to encode crucial information; only a model with forced lexical alignments avoids this damaging information loss.
View paper on