 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaba Is AI: Break the Rules to Beat the Benchmark
Jul 18, 2024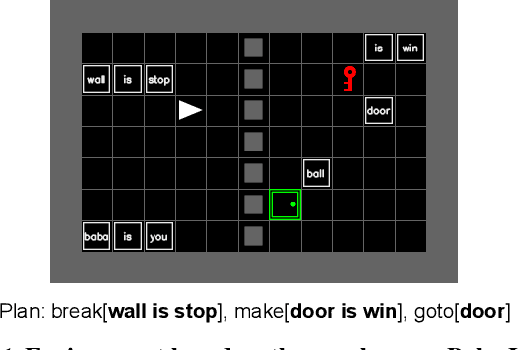

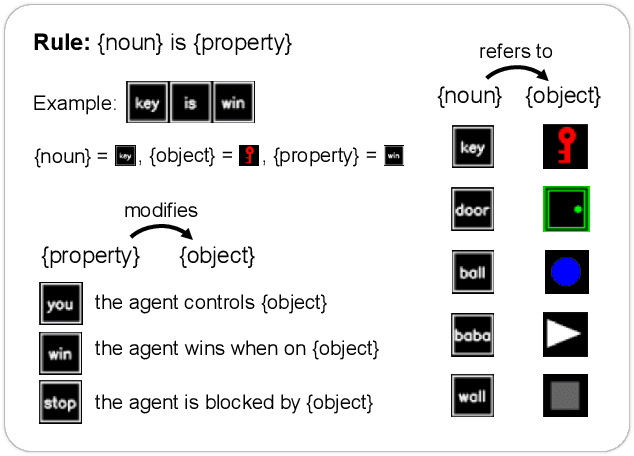
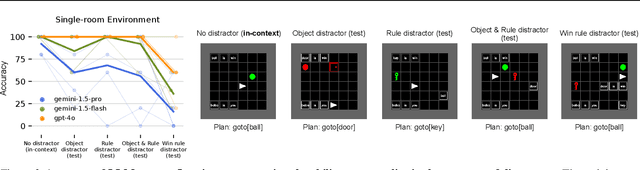
Humans solve problems by following existing rules and procedures, and also by leaps of creativity to redefine those rules and objectives. To probe these abilities, we developed a new benchmark based on the game Baba Is You where an agent manipulates both objects in the environment and rules, represented by movable tiles with words written on them, to reach a specified goal and win the game. We test three state-of-the-art multi-modal large language models (OpenAI GPT-4o, Google Gemini-1.5-Pro and Gemini-1.5-Flash) and find that they fail dramatically when generalization requires that the rules of the game must be manipulated and combined.
Revealing Vision-Language Integration in the Brain with Multimodal Networks
Jun 20, 2024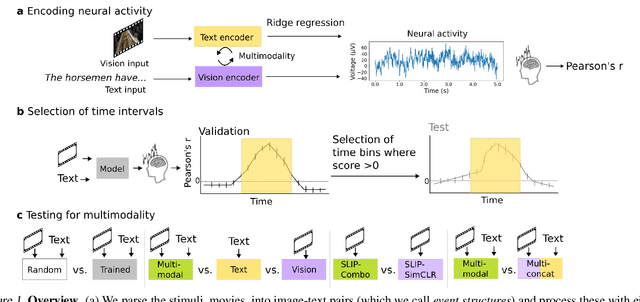

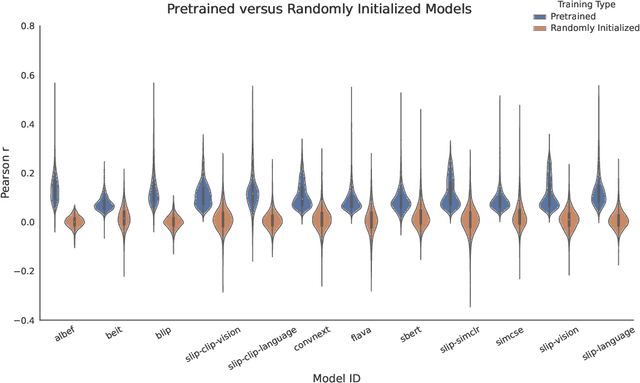
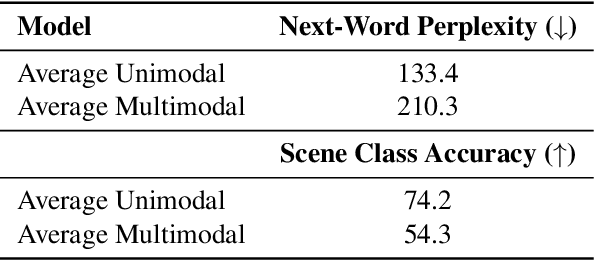
We use (multi)modal deep neural networks (DNNs) to probe for sites of multimodal integration in the human brain by predicting stereoencephalography (SEEG) recordings taken while human subjects watched movies. We operationalize sites of multimodal integration as regions where a multimodal vision-language model predicts recordings better than unimodal language, unimodal vision, or linearly-integrated language-vision models. Our target DNN models span different architectures (e.g., convolutional networks and transformers) and multimodal training techniques (e.g., cross-attention and contrastive learning). As a key enabling step, we first demonstrate that trained vision and language models systematically outperform their randomly initialized counterparts in their ability to predict SEEG signals. We then compare unimodal and multimodal models against one another. Because our target DNN models often have different architectures, number of parameters, and training sets (possibly obscuring those differences attributable to integration), we carry out a controlled comparison of two models (SLIP and SimCLR), which keep all of these attributes the same aside from input modality. Using this approach, we identify a sizable number of neural sites (on average 141 out of 1090 total sites or 12.94%) and brain regions where multimodal integration seems to occur. Additionally, we find that among the variants of multimodal training techniques we assess, CLIP-style training is the best suited for downstream prediction of the neural activity in these sites.
BrainBERT: Self-supervised representation learning for intracranial recordings
Feb 28, 2023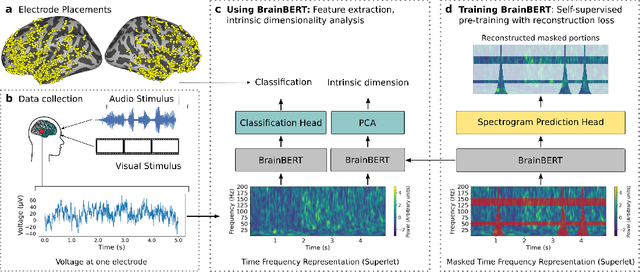
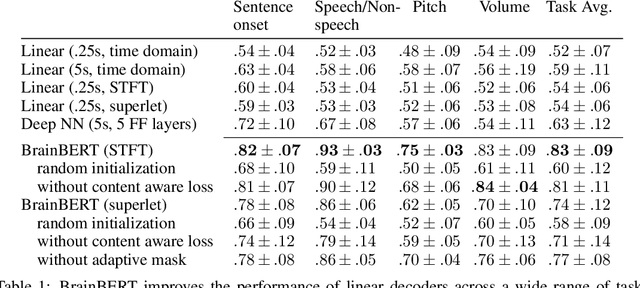
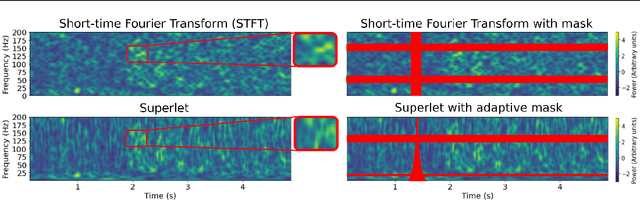
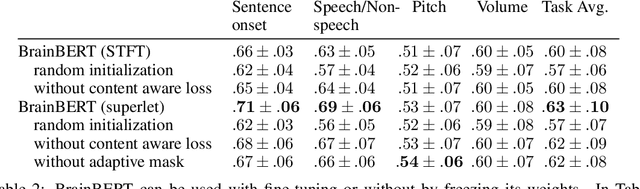
We create a reusable Transformer, BrainBERT, for intracranial recordings bringing modern representation learning approaches to neuroscience. Much like in NLP and speech recognition, this Transformer enables classifying complex concepts, i.e., decoding neural data, with higher accuracy and with much less data by being pretrained in an unsupervised manner on a large corpus of unannotated neural recordings. Our approach generalizes to new subjects with electrodes in new positions and to unrelated tasks showing that the representations robustly disentangle the neural signal. Just like in NLP where one can study language by investigating what a language model learns, this approach opens the door to investigating the brain by what a model of the brain learns. As a first step along this path, we demonstrate a new analysis of the intrinsic dimensionality of the computations in different areas of the brain. To construct these representations, we combine a technique for producing super-resolution spectrograms of neural data with an approach designed for generating contextual representations of audio by masking. In the future, far more concepts will be decodable from neural recordings by using representation learning, potentially unlocking the brain like language models unlocked language.
Continual Learning In Environments With Polynomial Mixing Times
Dec 13, 2021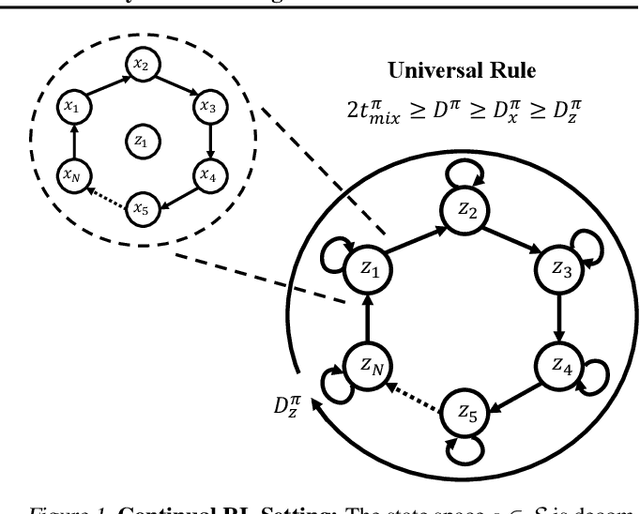

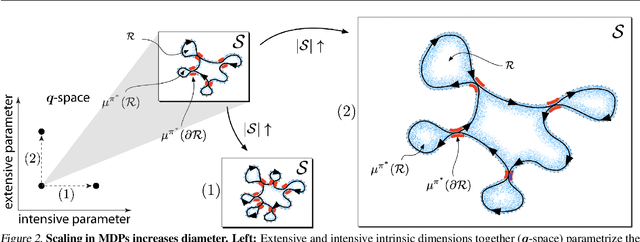
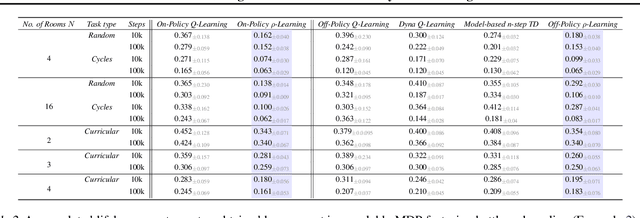
The mixing time of the Markov chain induced by a policy limits performance in real-world continual learning scenarios. Yet, the effect of mixing times on learning in continual reinforcement learning (RL) remains underexplored. In this paper, we characterize problems that are of long-term interest to the development of continual RL, which we call scalable MDPs, through the lens of mixing times. In particular, we establish that scalable MDPs have mixing times that scale polynomially with the size of the problem. We go on to demonstrate that polynomial mixing times present significant difficulties for existing approaches and propose a family of model-based algorithms that speed up learning by directly optimizing for the average reward through a novel bootstrapping procedure. Finally, we perform empirical regret analysis of our proposed approaches, demonstrating clear improvements over baselines and also how scalable MDPs can be used for analysis of RL algorithms as mixing times scale.
On the Role of Weight Sharing During Deep Option Learning
Feb 06, 2020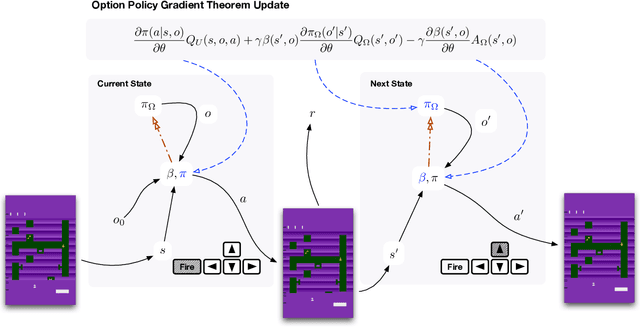
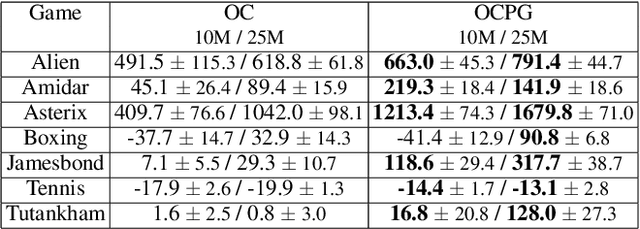


The options framework is a popular approach for building temporally extended actions in reinforcement learning. In particular, the option-critic architecture provides general purpose policy gradient theorems for learning actions from scratch that are extended in time. However, past work makes the key assumption that each of the components of option-critic has independent parameters. In this work we note that while this key assumption of the policy gradient theorems of option-critic holds in the tabular case, it is always violated in practice for the deep function approximation setting. We thus reconsider this assumption and consider more general extensions of option-critic and hierarchical option-critic training that optimize for the full architecture with each update. It turns out that not assuming parameter independence challenges a belief in prior work that training the policy over options can be disentangled from the dynamics of the underlying options. In fact, learning can be sped up by focusing the policy over options on states where options are actually likely to terminate. We put our new algorithms to the test in application to sample efficient learning of Atari games, and demonstrate significantly improved stability and faster convergence when learning long options.
Posing Fair Generalization Tasks for Natural Language Inference
Nov 03, 2019
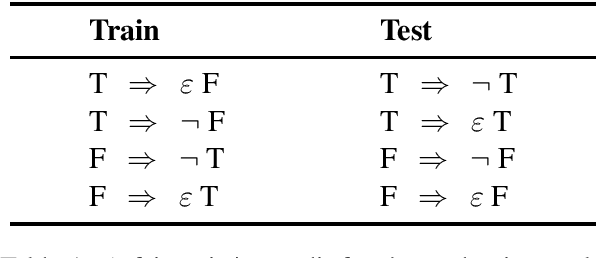

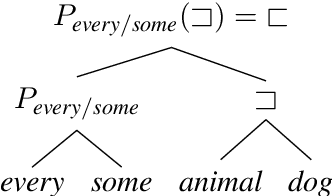
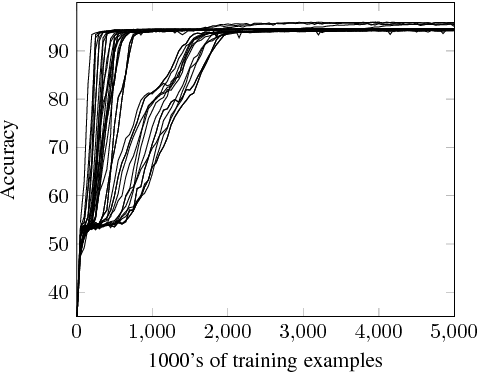
Deep learning models for semantics are generally evaluated using naturalistic corpora. Adversarial methods, in which models are evaluated on new examples with known semantic properties, have begun to reveal that good performance at these naturalistic tasks can hide serious shortcomings. However, we should insist that these evaluations be fair -that the models are given data sufficient to support the requisite kinds of generalization. In this paper, we define and motivate a formal notion of fairness in this sense. We then apply these ideas to natural language inference by constructing very challenging but provably fair artificial datasets and showing that standard neural models fail to generalize in the required ways; only task-specific models that jointly compose the premise and hypothesis are able to achieve high performance, and even these models do not solve the task perfectly.
Routing Networks and the Challenges of Modular and Compositional Computation
Apr 29, 2019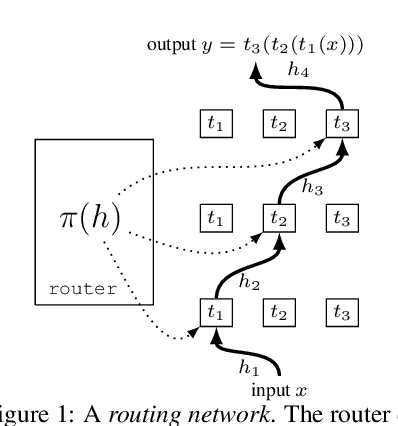
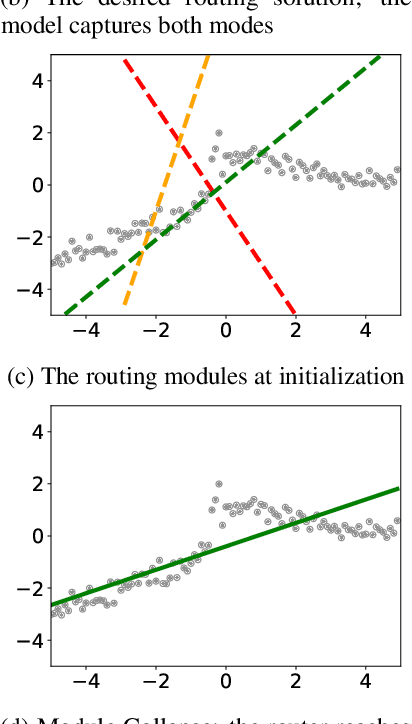
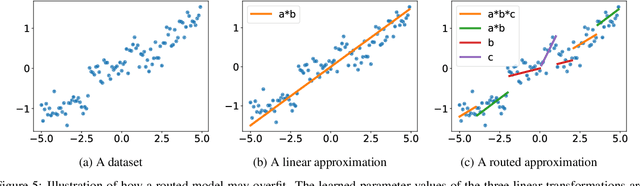
Compositionality is a key strategy for addressing combinatorial complexity and the curse of dimensionality. Recent work has shown that compositional solutions can be learned and offer substantial gains across a variety of domains, including multi-task learning, language modeling, visual question answering, machine comprehension, and others. However, such models present unique challenges during training when both the module parameters and their composition must be learned jointly. In this paper, we identify several of these issues and analyze their underlying causes. Our discussion focuses on routing networks, a general approach to this problem, and examines empirically the interplay of these challenges and a variety of design decisions. In particular, we consider the effect of how the algorithm decides on module composition, how the algorithm updates the modules, and if the algorithm uses regularization.
Stress-Testing Neural Models of Natural Language Inference with Multiply-Quantified Sentences
Oct 30, 2018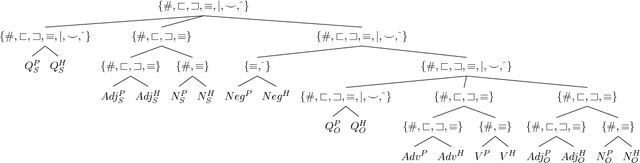


Standard evaluations of deep learning models for semantics using naturalistic corpora are limited in what they can tell us about the fidelity of the learned representations, because the corpora rarely come with good measures of semantic complexity. To overcome this limitation, we present a method for generating data sets of multiply-quantified natural language inference (NLI) examples in which semantic complexity can be precisely characterized, and we use this method to show that a variety of common architectures for NLI inevitably fail to encode crucial information; only a model with forced lexical alignments avoids this damaging information loss.
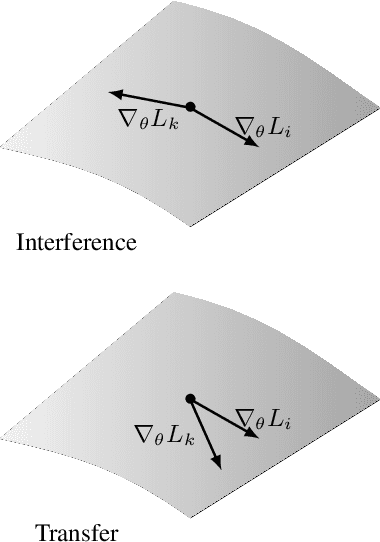
Learning to Learn without Forgetting By Maximizing Transfer and Minimizing Interference
Oct 29, 2018
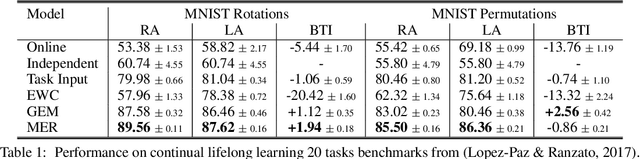
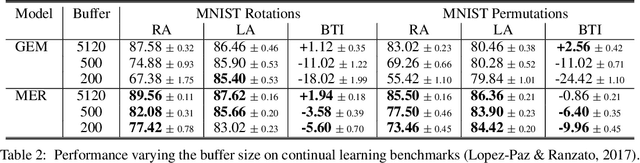

Lack of performance when it comes to continual learning over non-stationary distributions of data remains a major challenge in scaling neural network learning to more human realistic settings. In this work we propose a new conceptualization of the continual learning problem in terms of a trade-off between transfer and interference. We then propose a new algorithm, Meta-Experience Replay (MER), that directly exploits this view by combining experience replay with optimization based meta-learning. This method learns parameters that make interference based on future gradients less likely and transfer based on future gradients more likely. We conduct experiments across continual lifelong supervised learning benchmarks and non-stationary reinforcement learning environments demonstrating that our approach consistently outperforms recently proposed baselines for continual learning. Our experiments show that the gap between the performance of MER and baseline algorithms grows both as the environment gets more non-stationary and as the fraction of the total experiences stored gets smaller.
On the Effective Use of Pretraining for Natural Language Inference
Oct 05, 2017

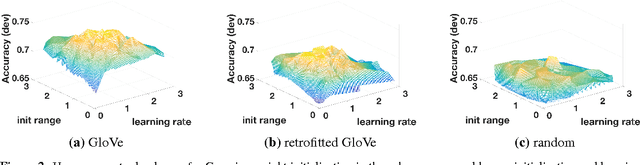

Neural networks have excelled at many NLP tasks, but there remain open questions about the performance of pretrained distributed word representations and their interaction with weight initialization and other hyperparameters. We address these questions empirically using attention-based sequence-to-sequence models for natural language inference (NLI). Specifically, we compare three types of embeddings: random, pretrained (GloVe, word2vec), and retrofitted (pretrained plus WordNet information). We show that pretrained embeddings outperform both random and retrofitted ones in a large NLI corpus. Further experiments on more controlled data sets shed light on the contexts for which retrofitted embeddings can be useful. We also explore two principled approaches to initializing the rest of the model parameters, Gaussian and orthogonal, showing that the latter yields gains of up to 2.9% in the NLI task.