 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Biologically Plausible Temporal Credit Assignment Rules Match BPTT for Neural Similarity? E-prop as an Example
Jun 07, 2025Understanding how the brain learns may be informed by studying biologically plausible learning rules. These rules, often approximating gradient descent learning to respect biological constraints such as locality, must meet two critical criteria to be considered an appropriate brain model: (1) good neuroscience task performance and (2) alignment with neural recordings. While extensive research has assessed the first criterion, the second remains underexamined. Employing methods such as Procrustes analysis on well-known neuroscience datasets, this study demonstrates the existence of a biologically plausible learning rule -- namely e-prop, which is based on gradient truncation and has demonstrated versatility across a wide range of tasks -- that can achieve neural data similarity comparable to Backpropagation Through Time (BPTT) when matched for task accuracy. Our findings also reveal that model architecture and initial conditions can play a more significant role in determining neural similarity than the specific learning rule. Furthermore, we observe that BPTT-trained models and their biologically plausible counterparts exhibit similar dynamical properties at comparable accuracies. These results underscore the substantial progress made in developing biologically plausible learning rules, highlighting their potential to achieve both competitive task performance and neural data similarity.
A Framework for Standardizing Similarity Measures in a Rapidly Evolving Field
Sep 26, 2024Similarity measures are fundamental tools for quantifying the alignment between artificial and biological systems. However, the diversity of similarity measures and their varied naming and implementation conventions makes it challenging to compare across studies. To facilitate comparisons and make explicit the implementation choices underlying a given code package, we have created and are continuing to develop a Python repository that benchmarks and standardizes similarity measures. The goal of creating a consistent naming convention that uniquely and efficiently specifies a similarity measure is not trivial as, for example, even commonly used methods like Centered Kernel Alignment (CKA) have at least 12 different variations, and this number will likely continue to grow as the field evolves. For this reason, we do not advocate for a fixed, definitive naming convention. The landscape of similarity measures and best practices will continue to change and so we see our current repository, which incorporates approximately 100 different similarity measures from 14 packages, as providing a useful tool at this snapshot in time. To accommodate the evolution of the field we present a framework for developing, validating, and refining naming conventions with the goal of uniquely and efficiently specifying similarity measures, ultimately making it easier for the community to make comparisons across studies.
Baba Is AI: Break the Rules to Beat the Benchmark
Jul 18, 2024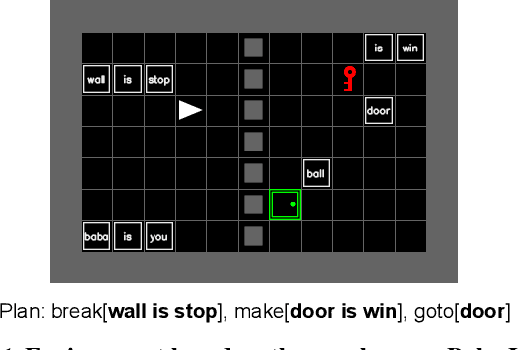

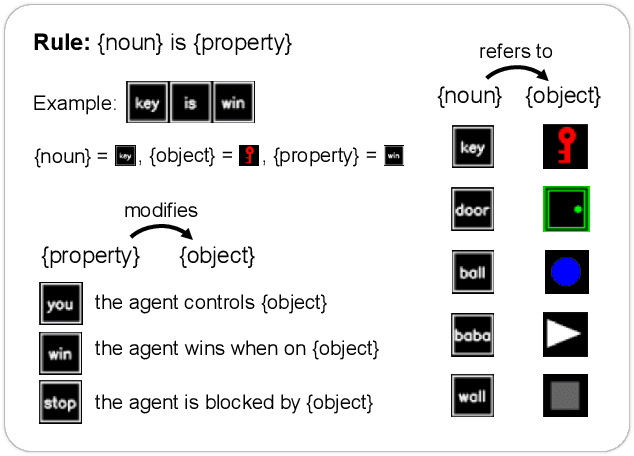
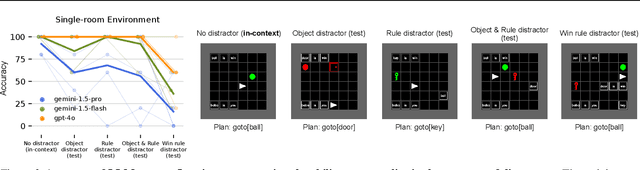
Humans solve problems by following existing rules and procedures, and also by leaps of creativity to redefine those rules and objectives. To probe these abilities, we developed a new benchmark based on the game Baba Is You where an agent manipulates both objects in the environment and rules, represented by movable tiles with words written on them, to reach a specified goal and win the game. We test three state-of-the-art multi-modal large language models (OpenAI GPT-4o, Google Gemini-1.5-Pro and Gemini-1.5-Flash) and find that they fail dramatically when generalization requires that the rules of the game must be manipulated and combined.
Differentiable Optimization of Similarity Scores Between Models and Brains
Jul 09, 2024What metrics should guide the development of more realistic models of the brain? One proposal is to quantify the similarity between models and brains using methods such as linear regression, Centered Kernel Alignment (CKA), and angular Procrustes distance. To better understand the limitations of these similarity measures we analyze neural activity recorded in five experiments on nonhuman primates, and optimize synthetic datasets to become more similar to these neural recordings. How similar can these synthetic datasets be to neural activity while failing to encode task relevant variables? We find that some measures like linear regression and CKA, differ from angular Procrustes, and yield high similarity scores even when task relevant variables cannot be linearly decoded from the synthetic datasets. Synthetic datasets optimized to maximize similarity scores initially learn the first principal component of the target dataset, but angular Procrustes captures higher variance dimensions much earlier than methods like linear regression and CKA. We show in both theory and simulations how these scores change when different principal components are perturbed. And finally, we jointly optimize multiple similarity scores to find their allowed ranges, and show that a high angular Procrustes similarity, for example, implies a high CKA score, but not the converse.
Recurrent neural network models for working memory of continuous variables: activity manifolds, connectivity patterns, and dynamic codes
Nov 01, 2021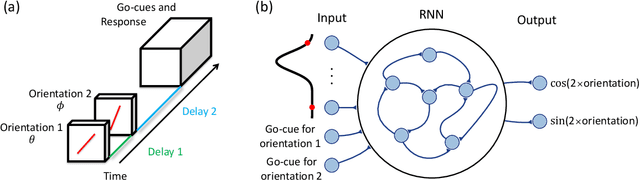
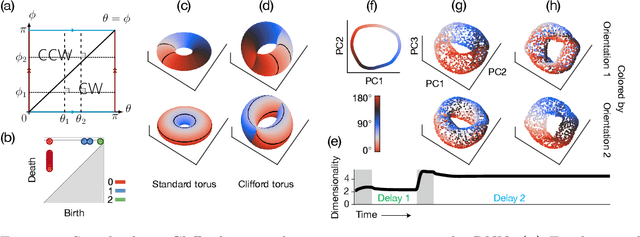
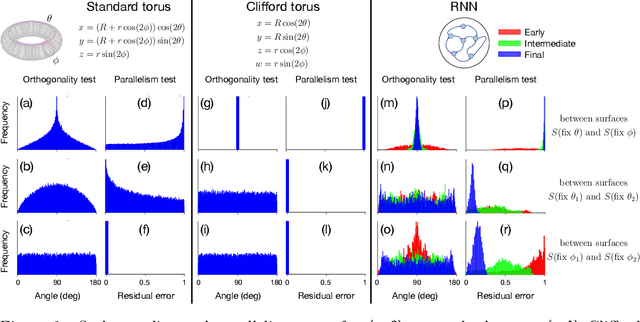
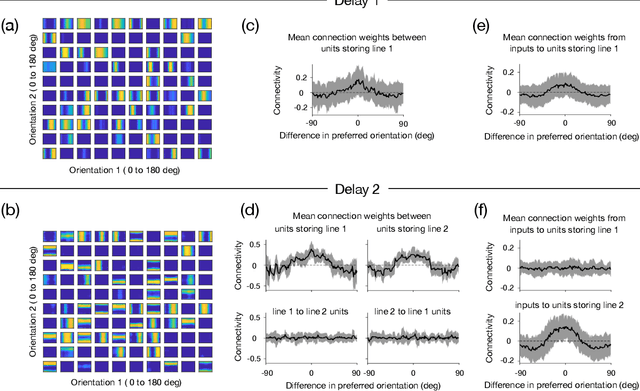
Many daily activities and psychophysical experiments involve keeping multiple items in working memory. When items take continuous values (e.g., orientation, contrast, length, loudness) they must be stored in a continuous structure of appropriate dimensions. We investigate how this structure is represented in neural circuits by training recurrent networks to report two previously shown stimulus orientations. We find the activity manifold for the two orientations resembles a Clifford torus. Although a Clifford and standard torus (the surface of a donut) are topologically equivalent, they have important functional differences. A Clifford torus treats the two orientations equally and keeps them in orthogonal subspaces, as demanded by the task, whereas a standard torus does not. We find and characterize the connectivity patterns that support the Clifford torus. Moreover, in addition to attractors that store information via persistent activity, our networks also use a dynamic code where units change their tuning to prevent new sensory input from overwriting the previously stored one. We argue that such dynamic codes are generally required whenever multiple inputs enter a memory system via shared connections. Finally, we apply our framework to a human psychophysics experiment in which subjects reported two remembered orientations. By varying the training conditions of the RNNs, we test and support the hypothesis that human behavior is a product of both neural noise and reliance on the more stable and behaviorally relevant memory of the ordinal relationship between the two orientations. This suggests that suitable inductive biases in RNNs are important for uncovering how the human brain implements working memory. Together, these results offer an understanding of the neural computations underlying a class of visual decoding tasks, bridging the scales from human behavior to synaptic connectivity.
Emergence of functional and structural properties of the head direction system by optimization of recurrent neural networks
Dec 21, 2019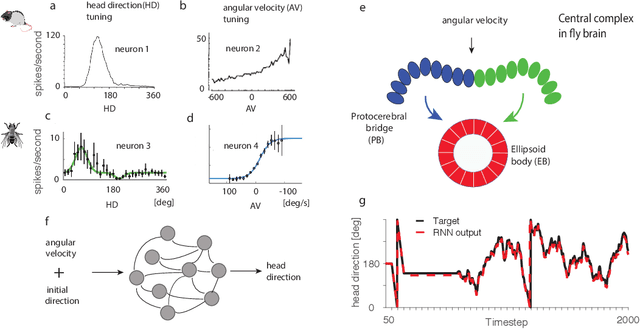
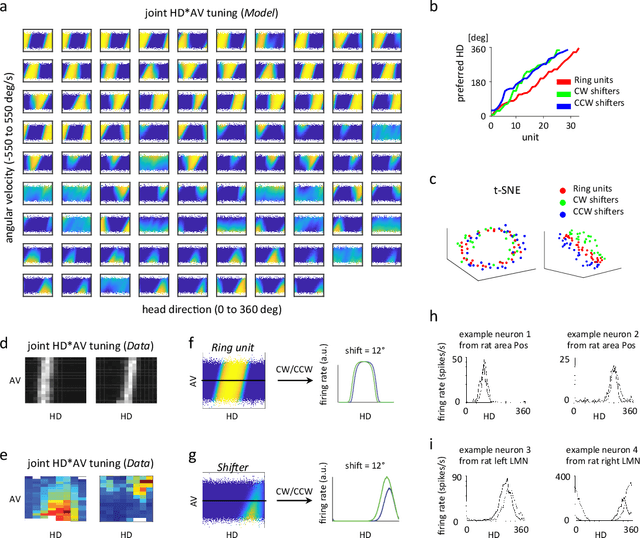


Recent work suggests goal-driven training of neural networks can be used to model neural activity in the brain. While response properties of neurons in artificial neural networks bear similarities to those in the brain, the network architectures are often constrained to be different. Here we ask if a neural network can recover both neural representations and, if the architecture is unconstrained and optimized, the anatomical properties of neural circuits. We demonstrate this in a system where the connectivity and the functional organization have been characterized, namely, the head direction circuits of the rodent and fruit fly. We trained recurrent neural networks (RNNs) to estimate head direction through integration of angular velocity. We found that the two distinct classes of neurons observed in the head direction system, the Ring neurons and the Shifter neurons, emerged naturally in artificial neural networks as a result of training. Furthermore, connectivity analysis and in-silico neurophysiology revealed structural and mechanistic similarities between artificial networks and the head direction system. Overall, our results show that optimization of RNNs in a goal-driven task can recapitulate the structure and function of biological circuits, suggesting that artificial neural networks can be used to study the brain at the level of both neural activity and anatomical organization.
Emergence of grid-like representations by training recurrent neural networks to perform spatial localization
Mar 21, 2018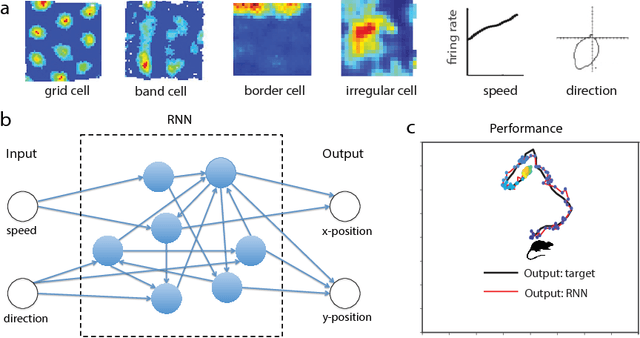
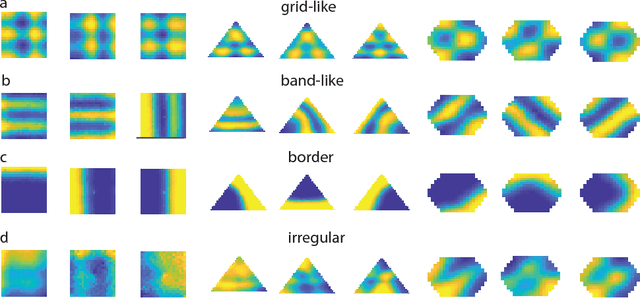
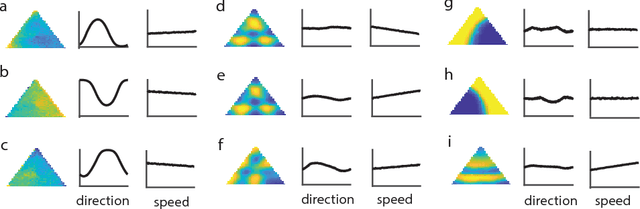
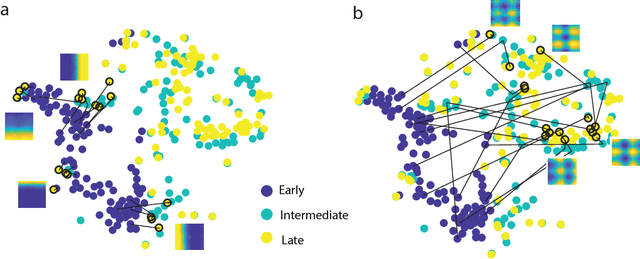
Decades of research on the neural code underlying spatial navigation have revealed a diverse set of neural response properties. The Entorhinal Cortex (EC) of the mammalian brain contains a rich set of spatial correlates, including grid cells which encode space using tessellating patterns. However, the mechanisms and functional significance of these spatial representations remain largely mysterious. As a new way to understand these neural representations, we trained recurrent neural networks (RNNs) to perform navigation tasks in 2D arenas based on velocity inputs. Surprisingly, we find that grid-like spatial response patterns emerge in trained networks, along with units that exhibit other spatial correlates, including border cells and band-like cells. All these different functional types of neurons have been observed experimentally. The order of the emergence of grid-like and border cells is also consistent with observations from developmental studies. Together, our results suggest that grid cells, border cells and others as observed in EC may be a natural solution for representing space efficiently given the predominant recurrent connections in the neural circuits.
full-FORCE: A Target-Based Method for Training Recurrent Networks
Oct 09, 2017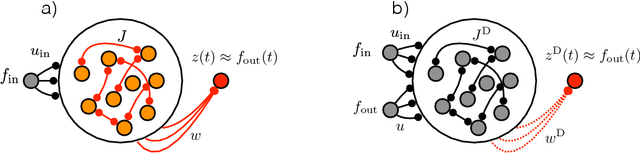
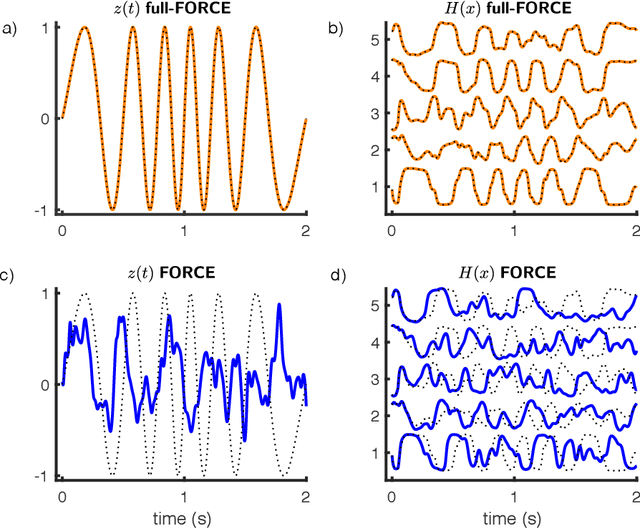
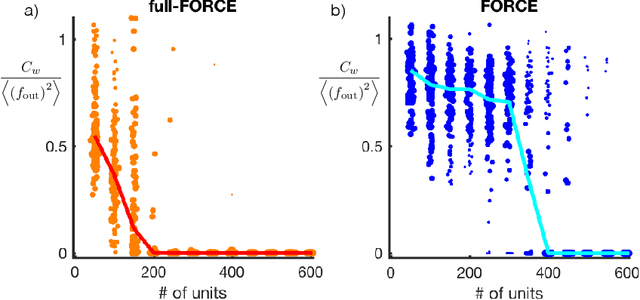
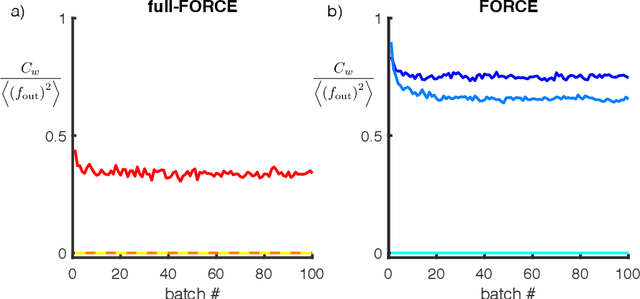
Trained recurrent networks are powerful tools for modeling dynamic neural computations. We present a target-based method for modifying the full connectivity matrix of a recurrent network to train it to perform tasks involving temporally complex input/output transformations. The method introduces a second network during training to provide suitable "target" dynamics useful for performing the task. Because it exploits the full recurrent connectivity, the method produces networks that perform tasks with fewer neurons and greater noise robustness than traditional least-squares (FORCE) approaches. In addition, we show how introducing additional input signals into the target-generating network, which act as task hints, greatly extends the range of tasks that can be learned and provides control over the complexity and nature of the dynamics of the trained, task-performing network.