 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent neural network models for working memory of continuous variables: activity manifolds, connectivity patterns, and dynamic codes
Nov 01, 2021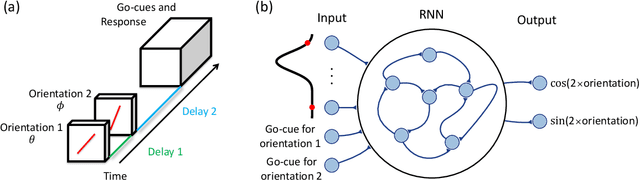
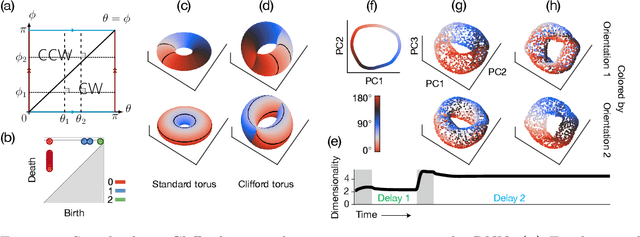
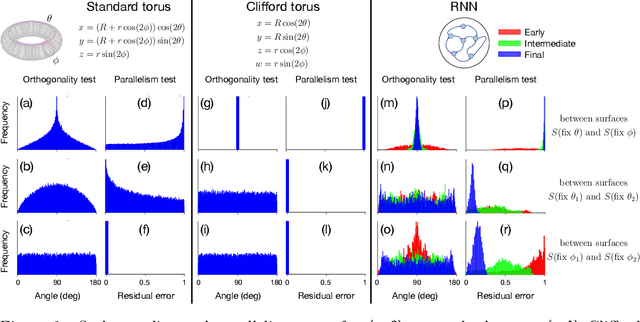
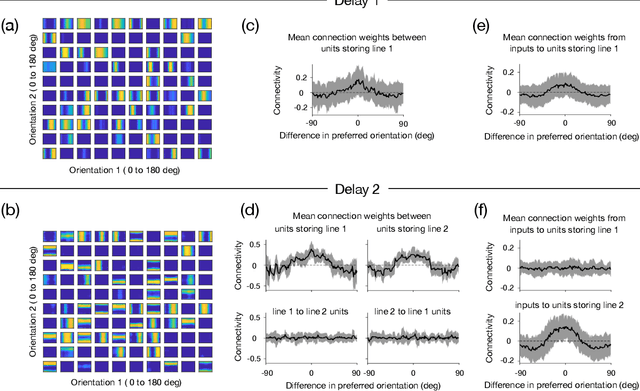
Many daily activities and psychophysical experiments involve keeping multiple items in working memory. When items take continuous values (e.g., orientation, contrast, length, loudness) they must be stored in a continuous structure of appropriate dimensions. We investigate how this structure is represented in neural circuits by training recurrent networks to report two previously shown stimulus orientations. We find the activity manifold for the two orientations resembles a Clifford torus. Although a Clifford and standard torus (the surface of a donut) are topologically equivalent, they have important functional differences. A Clifford torus treats the two orientations equally and keeps them in orthogonal subspaces, as demanded by the task, whereas a standard torus does not. We find and characterize the connectivity patterns that support the Clifford torus. Moreover, in addition to attractors that store information via persistent activity, our networks also use a dynamic code where units change their tuning to prevent new sensory input from overwriting the previously stored one. We argue that such dynamic codes are generally required whenever multiple inputs enter a memory system via shared connections. Finally, we apply our framework to a human psychophysics experiment in which subjects reported two remembered orientations. By varying the training conditions of the RNNs, we test and support the hypothesis that human behavior is a product of both neural noise and reliance on the more stable and behaviorally relevant memory of the ordinal relationship between the two orientations. This suggests that suitable inductive biases in RNNs are important for uncovering how the human brain implements working memory. Together, these results offer an understanding of the neural computations underlying a class of visual decoding tasks, bridging the scales from human behavior to synaptic connectivity.
In-RDBMS Hardware Acceleration of Advanced Analytics
Sep 18, 2018

The data revolution is fueled by advances in machine learning, databases, and hardware design. Programmable accelerators are making their way into each of these areas independently. As such, there is a void of solutions that enables hardware acceleration at the intersection of these disjoint fields. This paper sets out to be the initial step towards a unifying solution for in-Database Acceleration of Advanced Analytics (DAnA). Deploying specialized hardware, such as FPGAs, for in-database analytics currently requires hand-designing the hardware and manually routing the data. Instead, DAnA automatically maps a high-level specification of advanced analytics queries to an FPGA accelerator. The accelerator implementation is generated for a User Defined Function (UDF), expressed as a part of an SQL query using a Python-embedded Domain-Specific Language (DSL). To realize an efficient in-database integration, DAnA accelerators contain a novel hardware structure, Striders, that directly interface with the buffer pool of the database. Striders extract, cleanse, and process the training data tuples that are consumed by a multi-threaded FPGA engine that executes the analytics algorithm. We integrate DAnA with PostgreSQL to generate hardware accelerators for a range of real-world and synthetic datasets running diverse ML algorithms. Results show that DAnA-enhanced PostgreSQL provides, on average, 8.3x end-to-end speedup for real datasets, with a maximum of 28.2x. Moreover, DAnA-enhanced PostgreSQL is, on average, 4.0x faster than the multi-threaded Apache MADLib running on Greenplum. DAnA provides these benefits while hiding the complexity of hardware design from data scientists and allowing them to express the algorithm in =30-60 lines of Python.
Applications of Machine Learning Methods to Quantifying Phenotypic Traits that Distinguish the Wild Type from the Mutant Arabidopsis Thaliana Seedlings during Root Gravitropism
Aug 31, 2010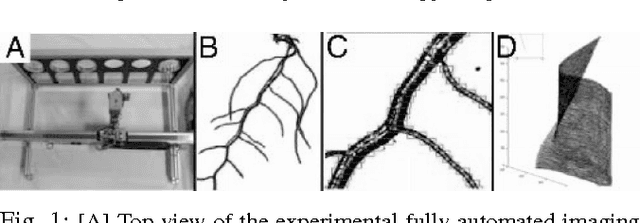

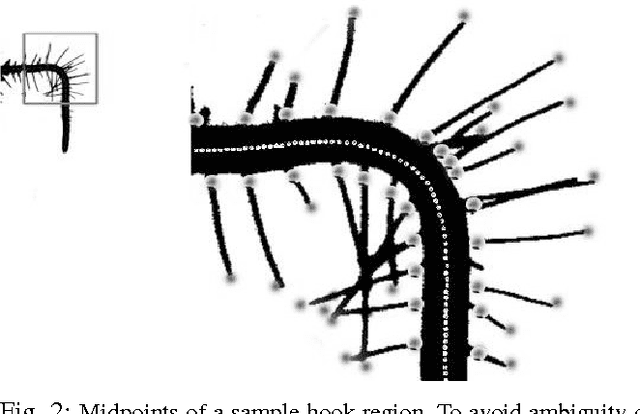
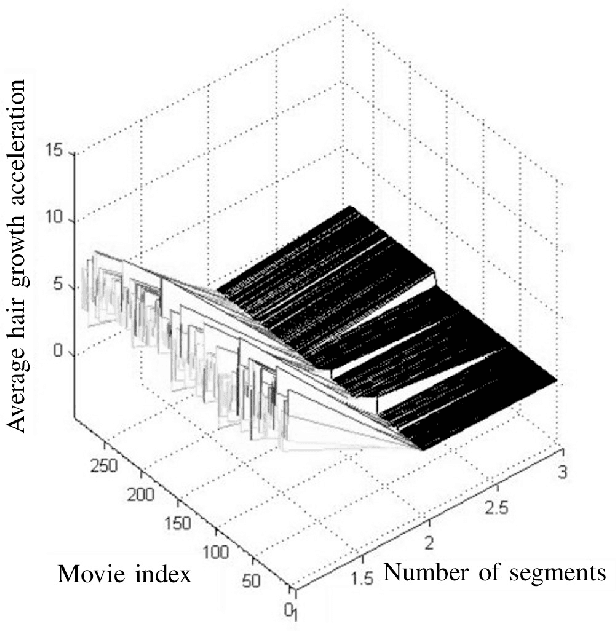
Post-genomic research deals with challenging problems in screening genomes of organisms for particular functions or potential for being the targets of genetic engineering for desirable biological features. 'Phenotyping' of wild type and mutants is a time-consuming and costly effort by many individuals. This article is a preliminary progress report in research on large-scale automation of phenotyping steps (imaging, informatics and data analysis) needed to study plant gene-proteins networks that influence growth and development of plants. Our results undermine the significance of phenotypic traits that are implicit in patterns of dynamics in plant root response to sudden changes of its environmental conditions, such as sudden re-orientation of the root tip against the gravity vector. Including dynamic features besides the common morphological ones has paid off in design of robust and accurate machine learning methods to automate a typical phenotyping scenario, i.e. to distinguish the wild type from the mutants.
Pattern Recognition in Collective Cognitive Systems: Hybrid Human-Machine Learning (HHML) By Heterogeneous Ensembles
Aug 31, 2010
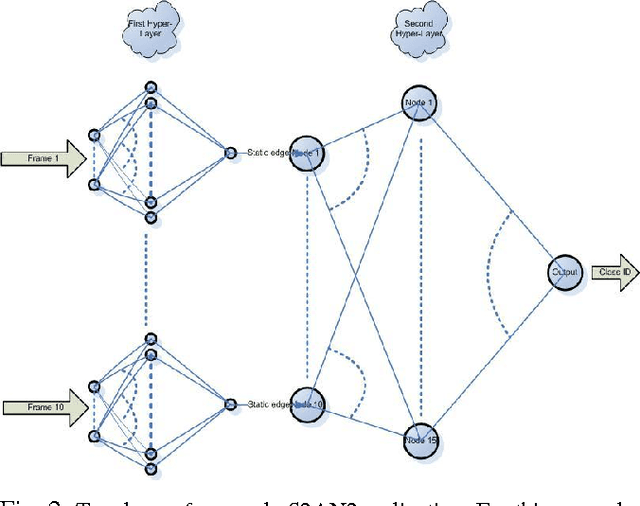
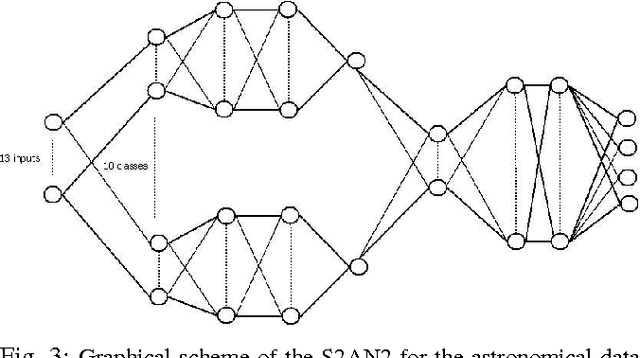
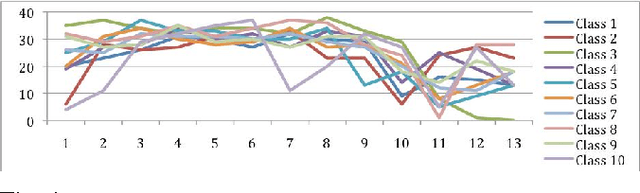
The ubiquitous role of the cyber-infrastructures, such as the WWW, provides myriad opportunities for machine learning and its broad spectrum of application domains taking advantage of digital communication. Pattern classification and feature extraction are among the first applications of machine learning that have received extensive attention. The most remarkable achievements have addressed data sets of moderate-to-large size. The 'data deluge' in the last decade or two has posed new challenges for AI researchers to design new, effective and accurate algorithms for similar tasks using ultra-massive data sets and complex (natural or synthetic) dynamical systems. We propose a novel principled approach to feature extraction in hybrid architectures comprised of humans and machines in networked communication, who collaborate to solve a pre-assigned pattern recognition (feature extraction) task. There are two practical considerations addressed below: (1) Human experts, such as plant biologists or astronomers, often use their visual perception and other implicit prior knowledge or expertise without any obvious constraints to search for the significant features, whereas machines are limited to a pre-programmed set of criteria to work with; (2) in a team collaboration of collective problem solving, the human experts have diverse abilities that are complementary, and they learn from each other to succeed in cognitively complex tasks in ways that are still impossible imitate by machines.
* International Conference on Artificial Intelligence, WorldComp 2010